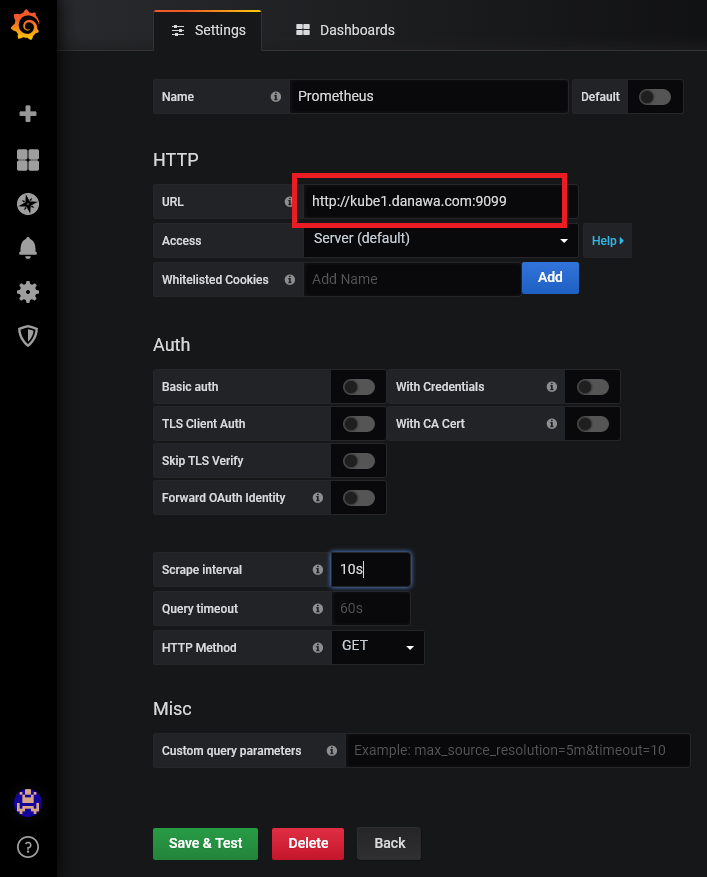
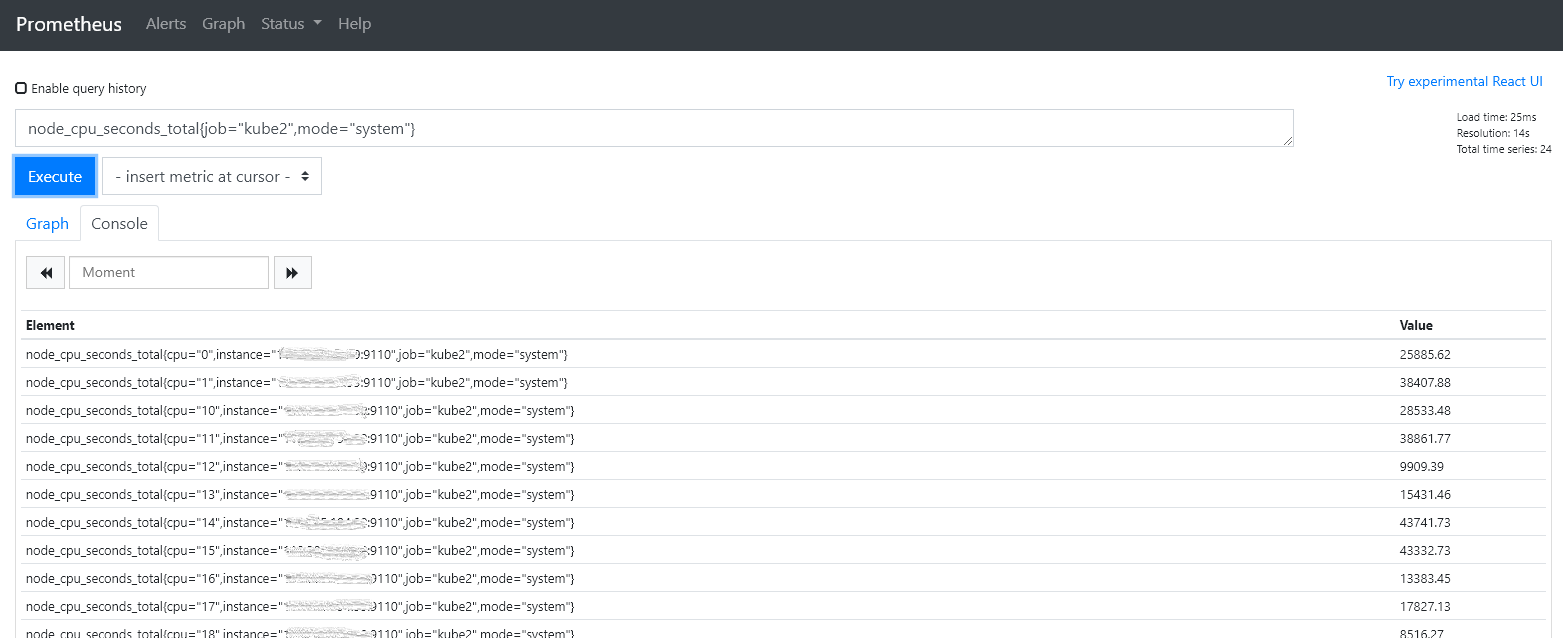
블루투스 페어링
Bluetooth가 연결되지 않고 검색 가능한 경우 페어링할 수 있습니다. 주로 이 섹션을 참조하세요:
문제가 있는 경우 이 지침을 사용하여 문제 해결을 수행하십시오: BLE 문제 해결
하드웨어 스위치
원래 딥 스위치 위치에는 푸시 스위치가 있습니다. 이것은 컨트롤러의 유일한 스위치입니다.
주목:
- 이 스위치는 누르면 꺼지고, 올리면 켜집니다.
- 이 스위치의 기능은 블루투스가 아니라 배터리 전원 공급을 켜거나 끄는 것입니다.
- 따라서 이 스위치가 꺼져 있을 때에도 USB 케이블을 연결하면 USB가 전원이므로 Bluetooth가 계속 작동할 수 있습니다.
블루투스를 끄고 싶으시다면 블루투스 스위치 및 연결 상태를 참고하세요.
힌트
- 이 소프트웨어 스위치는 USB만 또는 일시적으로 사용하는 사람들을 위해 **Bluetooth 기능**을 완전히 끄도록 설계되었습니다. 이 스위치가 꺼져 있는 동안 물리적 전원 스위치를 끄는 것이 좋습니다.
- 이 기능은 에너지를 절약하기 위해 매일 Bluetooth를 끄도록 설계된 것이 아닙니다. BLE660C/BLE980C는 잠금 모드보다 이 기능을 사용하여 대기 모드에서 훨씬 더 많은 전력을 소모합니다.
배터리 충전
충전 포트와 데이터 포트는 모두 컨트롤러의 USB 포트입니다.
충전에는 PC의 USB 포트나 5V 충전기를 사용하는 것이 좋습니다.
- 부적절한 충전(6V 이상)은 충전 IC를 파손할 수 있습니다. 고전력 충전기를 사용해도 기본 충전 전류가 약 450mA로 제한되어 충전 속도가 빨라지지 않습니다.
- 충전에는 5V 이하의 충전기를 사용하세요. 전원 공급 장치 또는 다른 충전기가 있는 HUB의 일부 U 포트는 5V보다 높을 수 있습니다.
- 장시간 플러그를 꽂아 사용할 경우, 배터리를 뽑아두거나 적어도 배터리 스위치를 끄는 것이 좋습니다.
충전 표시등은 전원 버튼 아래에 있는 빨간색(또는 파란색) LED입니다. 아래에서 볼 수 있습니다. 세 가지 상태가 있습니다. v2.3 버전에서는 충전 표시등이 제거되었지만 배터리 수준을 x1%로 표시하여 여전히 충전 중임을 판단할 수 있습니다.
| 충전 LED 상태 | 의미 |
|---|---|
| 밝기가 낮거나 깜박임 | 비정상(배터리가 없거나 배터리에 문제가 있음) |
| 높은 밝기 | 충전 중 |
| 꺼짐 또는 매우 낮은 밝기 | 배터리가 완전히 충전되었습니다 |
win10 1809 이상에서는 배터리 백분율 표시가 지원됩니다. 정확하지 않으며 참조용일 뿐입니다(특히 충전 중에 표시되는 오류가 더 큽니다). 10%마다 수준이고 가장 높은 것은 90%입니다. 또한, 충전 중에는 백분율이 x1%로 표시되며 다음 그림과 같이 충전하지 않을 때보다 1% 더 높습니다.
 완전히 충전되면 충전 표시등이 꺼지거나 밝기가 매우 낮아질 수 있습니다.
완전히 충전되면 충전 표시등이 꺼지거나 밝기가 매우 낮아질 수 있습니다.
Mac은 타사 Bluetooth 장치의 배터리 서비스를 차단했습니다. 따라서 배터리 수준을 알고 싶다면 Output Battery Percetage as Text 기능(BLE660C/BLE980C의 기본 단축키는 Fn+E)을 사용할 수 있습니다. 충전 및 배터리 정보
키맵 편집 및 펌웨어 재플래시
웹사이트 https://ydkb.io를 열고 키보드 BLE660C 또는 BLE980C를 선택한 다음 [대용량 저장 장치 부트로더(U 디스크 모드)](부트로더/msd-부트로더) 페이지에 플래싱 방법이 있습니다. 키 편집기에 대한 설명은 이 문서의 다른 부분을 참조하세요.
케이블을 삽입하여 점멸 모드로 들어가려면 왼쪽 위 키(일반적으로 ESC)를 누르는 것 외에도 LED와 기능을 사용할 수 있습니다 Reset. 실수 로 누르는 것을 방지하기 위해 <kbd>LCtrl을 누른 상태에서 이 키를 누르면 됩니다. 이렇게 하면 플러그 Reset를 뽑았다가 다시 꽂지 않고도 바로 점멸 모드로 전환할 수 있습니다.
지표 및 전력 절약
표시기의 일반적인 기능은 LEDMAP 으로 정의할 수 있습니다 . 표시기는 키보드가 작동 중일 때만 켜지고 절전 모드는 아닙니다. 표시기를 계속 켜두는 기능으로 설정하지 않는 것이 좋습니다. 그러면 전력 소모가 증가하고 배터리 수명이 크게 줄어들 수 있습니다.
블루투스 모드에서 주의 사항
- 블루투스 모드에서는 Num, Caps, Scroll Lock 표시등이 블루투스 모드의 OS 상태와 동기화되지 않습니다.
- 블루투스 모드에서는 누르면 켜지거나 꺼집니다. USB 모드에서는 동기화됩니다.
- 한 지표가 동기화되지 않은 경우 Shift + Capslock과 같은 Shift + KEY를 사용할 수 있습니다. 이런 식으로 CapsLock은 적용되지만 지표는 변경되지 않습니다.
- 블루투스 모드에서 이 기능을 적절히 사용하면 표시등을 반대로 바꿀 수 있습니다. 예를 들어, Num Lock이 켜져 있을 때 Num Lock 표시등을 끄고 꺼져 있을 때 표시등을 켜면 전력을 절약할 수 있습니다.
LEDMAP 설정 외에도 몇 가지 특수 기능이 있습니다.
| 상태 또는 작업 | BLE660C LED 표시 방식 |
|---|---|
| 플래시 모드(대기) | 두 개의 표시등이 함께 깜박이거나 번갈아 깜박이며 절대 꺼지지 않습니다. 660C의 무소음 버전은 전면에 표시등이 하나뿐입니다. |
| 플래시 모드(데이터 쓰기) | 위의 내용을 토대로 Caps 표시등이 빠르게 깜빡입니다. |
| 시작시 블루투스가 연결되지 않음 상태 표시 | 두 개의 표시등이 깜박이며 연결되지 않은 경우 약 15초 후에 깜박임이 멈춥니다. |
| 시작 시 블루투스가 연결됨. 상태 표시 | 두 표시등이 동시에 느리게 깜박입니다. 켜지는 시간은 꺼지는 시간보다 훨씬 깁니다. |
| LShift+ RShift+를 누르세요s | 위와 같이 Bluetooth 연결 상태를 표시합니다. |
| 수동으로 잠금 모드로 들어가기 | 두 개의 표시등이 동시에 켜진 후 Scroll 표시등, Caps 표시등 순으로 꺼집니다. |
| 2단계 에너지 절약 또는 잠금 모드에서 깨어나기 | 두 개의 표시등이 동시에 켜진 후 Bluetooth 연결 상태를 나타내기 시작합니다. |
| 배터리 부족 알림 | 키보드를 사용할 때는 두 개의 표시등이 동시에 깜박입니다. 에너지를 절약할 때는 깜박이지 않습니다. 2~3일은 여전히 사용할 수 있습니다. |
| 배터리가 매우 부족하다는 메시지 | 키보드를 사용할 때 두 개의 표시등이 동시에 빠르게 깜박입니다. 에너지를 절약할 때는 깜박이지 않습니다. 가능한 한 빨리 충전하는 것이 좋습니다. |
BLE980C의 경우, 설명의 편의를 위해 전면의 3개 표시등을 왼쪽에서 오른쪽으로 LED1 LED2 LED3으로 표시하였습니다.
| 상태 또는 작업 | BLE980C LED 표시 방식 |
|---|---|
| 점멸 모드(유휴) | 3개의 표시등이 함께 깜박이거나 교대로 깜박이며 항상 켜져 있습니다. |
| 플래시 모드(데이터 쓰기) | 위 내용을 기준으로 LED3가 빠르게 깜박입니다. |
| 시작 시 Bluetooth 연결 해제 상태 표시 | LED3가 깜박이며, 연결되지 않은 경우 약 15초 후에 깜박임이 멈춥니다. |
| 시작 시 Bluetooth 연결 상태 표시기 | LED2와 LED3이 동시에 느리게 깜박입니다. 켜지는 시간은 꺼지는 시간보다 훨씬 깁니다. |
| LShift+ RShift+를 누르세요s | 위와 같이 Bluetooth 연결 상태를 표시합니다. |
| 수동으로 잠금 모드로 들어가기 | 3개의 조명이 동시에 켜지고 LED3 LED2 LED1 순으로 꺼집니다. |
| 2단계 에너지 절약 또는 잠금 모드에서 깨우기 | 3개의 표시등이 동시에 켜지고 블루투스 연결 상태를 나타내기 시작합니다. |
| 배터리 부족 알림 | 키보드를 사용할 때는 세 개의 불빛이 동시에 깜빡인다. 에너지를 절약할 때는 깜빡이지 않는다. 2~3일은 쓸 수 있다. |
| 배터리 매우 부족 알림 | 키보드를 사용할 때 세 개의 표시등이 동시에 빠르게 깜박입니다. 에너지를 절약할 때는 깜박이지 않습니다. 가능한 한 빨리 충전하는 것이 좋습니다. |
힌트
- 배터리 부족 프롬프트는 가장 높은 우선순위를 갖습니다. 배터리가 부족하면 항상 다른 것을 표시하고 덮습니다.
- FC660C의 무소음 버전에는 스크롤 표시기가 없으므로 Caps 표시기를 보고 판단하세요.
그 다음은 절전 모드에 대해서입니다.
- 키보드가 아무 키도 누르지 않고 3초 동안 유휴 상태가 되면 일반 절전 모드로 들어갑니다. 이 모드에서는 30ms마다 매트릭스가 스캔됩니다. 아무 키나 누르면 일반 절전 모드에서 빠져나갑니다.
- 키보드의 블루투스가 90초 동안 연결되지 않거나 2.5시간 이상 사용하지 않으면 블루투스가 꺼지고 심층 절전 모드로 전환됩니다. 아무 키나 3~5초 동안 길게 눌러 깨우세요.
- 잠금 모드를 사용하면 키보드가 바로 심층 절전 모드로 전환됩니다. 2와의 차이점은 이 방법으로 F와 J만 3~5초 동안 함께 눌러서 깨울 수 있다는 것입니다.
심층 절전 모드의 전력 소모는 매우 낮습니다. 일상적으로 사용하는 경우 전원 스위치를 끌 필요가 없으며 키보드를 그대로 두고 절전 모드로 전환하면 됩니다. 가방에 넣어 가지고 다니려면 잠금 모드로 전환하여 예기치 않게 깨어나는 것을 방지하는 것이 좋습니다.
다음 GIF는 배터리가 부족할 때의 효과를 보여줍니다.

예외 처리
키 누름 오류 트리거 또는 무작위 트리거가 있는 경우. 타오바오 링크에서 제공하는 설치 지침에 따라 배터리가 hhkb 상단 키보드 회로 보드에서 절연되어 있는지 확인하십시오.
작업 중에 문제가 발생하면 가장 빠른 방법은 USB 케이블을 다시 연결하거나 키보드 전원 스위치를 껐다가 다시 켜서 제대로 작동하는지 확인하는 것입니다.
그리고 BLE 문제 해결 을 참조하세요 . 다른 버그가 있으면 이메일로 알려주세요.
하드웨어 버전의 차이점
나중에 다른 사람들이 볼 수 있도록 판매된 하드웨어 버전 간의 차이점을 기록해 두세요.
v2.3:메인 컨트롤 atmega32u4의 패키지를 변경했습니다. 일부 커패시터와 저항의 패키지를 변경했습니다(0805 -> 0603). 컨트롤러의 충전 표시등을 제거했습니다.
v2.2:v2.1 기반으로, LWin+ LAlt+를 사용하여 RestBluetooth를 재설정할 수 있습니다.
v2.1:v2.0을 기반으로, 블루투스를 재설정하기 위한 단락 회로를 용이하게 하기 위해 두 개의 구멍이 추가되었습니다. 그리고 외부 크리스털 발진기 대신 MCU의 내장 발진기를 사용합니다.