이 global.metric.enabled매개변수는 배포 아키텍처를 정의하는 마스터 스위치입니다. true(기본값)으로 설정하면 차트는 기존 Flink 및 Batch 모듈 대신 Kafka, Pinot, Telegraf를 배포합니다. 이를 통해 Pinpoint 3.x에 도입된 강력한 실시간 메트릭 분석 및 URI 통계 기능을 사용할 수 있습니다.
설치: 시작해 봅시다
설치 및 실행은 간단합니다. 먼저 저장소를 복제하고 Helm 종속성을 업데이트해야 합니다.
# 1. 저장소 복제 # 이 명령은 공식 Pinpoint Kubernetes 저장소를 로컬 머신에 복제합니다. git clone https://github.com/pinpoint-apm/pinpoint-kubernetes.git
cd pinpoint-kubernetes# 2. Helm 종속성 업데이트 # 이 명령은 Chart.yaml에 지정된 종속 차트(예: mysql, zookeeper 등)를 가져옵니다. helm dependency update
최신 “메트릭 프로파일” 설치(권장):
이 모드는 Kafka와 Pinot을 사용하여 Pinpoint의 최신 기능을 모두 제공합니다.
# 3. 메트릭 프로필 모드로 차트 설치 # 이 명령은 릴리스 이름이 'pinpoint'인 Pinpoint 차트를 # 'pinpoint'라는 새 네임스페이스에 설치합니다. 메트릭 프로필은 기본적으로 활성화되어 있습니다. helm install pinpoint . -n pinpoint --create-namespace
레거시 “클래식 모드” 설치:
기존 APM 추적만 필요한 경우 Flink와 Batch를 사용하여 클래식 스택을 배포할 수 있습니다.
# 3. 클래식 모드에서 차트 설치 # 'global.metric.enabled'를 'false'로 설정하면 Helm은 Kafka와 Pinot 대신 Flink와 Batch 구성 요소를 포함하는 클래식 스택을 배포합니다. helm install pinpoint . -n pinpoint --create-namespace --set global.metric.enabled=false
설치가 완료되면 다음을 사용하여 Pinpoint 웹 UI에 액세스할 수 있습니다 port-forward.
# 4. 웹 UI에 액세스합니다. # 이 명령은 로컬 포트 8080에서 Kubernetes 클러스터 내부에서 실행되는 pinpoint-web 서비스로 트래픽을 전달합니다. kubectl port-forward svc/pinpoint-web 8080:8080 -n pinpoint
이제 http://localhost:8080브라우저에서 Pinpoint 대시보드를 볼 수 있습니다.
Enter 키를 누르거나 클릭하여 이미지를 전체 크기로 보세요.
웹 UI
구성 및 프로덕션 팁
프로덕션 수준의 배포에서는 values.yaml파일을 사용자 지정하는 것이 중요합니다.
지속성: 모든 상태 저장 구성 요소(HBase, MySQL, Zookeeper, Kafka, Pinot)를 설정하고 enabled: true적절한 .을 선택하세요 storageClassName.
리소스:requests/limits 예상 부하에 따라 각 구성 요소의 CPU와 메모리를 정의합니다 . 이는 클러스터 안정성에 필수적입니다.
Ingress: 웹 UI를 외부에 노출하려면 web.ingress.enabled=true호스트 이름과 TLS 인증서(Kubernetes 비밀을 통해)를 설정하고 구성합니다.
자격 증명: Helm --set플래그나 사용자 정의 값 파일을 사용하여 MySQL, Redis 및 기타 구성 요소의 기본 비밀번호를 항상 변경하세요.
CREATE OR REPLACE PACKAGE PKG_CRYPTO
IS
FUNCTION ENCRYPT(INPUT_STRING IN VARCHAR2, KEY_DATA IN VARCHAR2 := ‘12345678’)RETURN RAW;
FUNCTION DECRYPT(INPUT_STRING IN VARCHAR2, KEY_DATA IN VARCHAR2 := ‘12345678’)RETURN VARCHAR2;
END;
CREATE OR REPLACE PACKAGE BODY PKG_CRYPTO
IS
— 에러 발생시에 error code 와 message 를 받기 위한 변수 지정.
SQLERRMSG VARCHAR2(255) ;
SQLERRCDE NUMBER;
— 암호화 함수 선언 key_data 는 입력하지 않을 시에 default 로 12345678 로 지정됨.FUNCTION ENCRYPT(INPUT_STRING IN VARCHAR2
, KEY_DATA IN VARCHAR2 := ‘12345678’
)
RETURN RAW
IS
KEY_DATA_RAW RAW(4000) ;
CONVERTED_RAW RAW(4000) ;
ENCRYPTED_RAW RAW(4000) ;
BEGIN
— 들어온 data 와 암호키를 각각 RAW 로 변환한다.
CONVERTED_RAW := UTL_I18N.STRING_TO_RAW(INPUT_STRING, ‘AL32UTF8’) ;
KEY_DATA_RAW := UTL_I18N.STRING_TO_RAW(KEY_DATA, ‘AL32UTF8’) ;
— DBMS_PKG_CRYPTO.ENCRYPT 로 암호화 하여 encrypted_raw 에 저장.
ENCRYPTED_RAW := DBMS_CRYPTO.ENCRYPT(SRC => CONVERTED_RAW,
— typ 부분만 변경하면 원하는 알고리즘을 사용할 수 있다.
— 단, key value bype 가 다 다르니 확인해야 한다.
TYP => DBMS_CRYPTO.DES_CBC_PKCS5, KEY => KEY_DATA_RAW, IV => NULL) ;
RETURN ENCRYPTED_RAW;
EXCEPTION
WHEN OTHERS THEN
RETURN INPUT_STRING;
END ENCRYPT;FUNCTION DECRYPT(INPUT_STRING IN VARCHAR2
, KEY_DATA IN VARCHAR2 := ‘12345678’
)
RETURN VARCHAR2
IS
CONVERTED_STRING VARCHAR2(4000) ;
KEY_DATA_RAW RAW(4000) ;
DECRYPTED_RAW VARCHAR2(4000) ;
BEGIN
KEY_DATA_RAW := UTL_I18N.STRING_TO_RAW(KEY_DATA, ‘AL32UTF8’) ;
DECRYPTED_RAW := DBMS_CRYPTO.DECRYPT(SRC => INPUT_STRING, TYP => DBMS_CRYPTO.DES_CBC_PKCS5, KEY => KEY_DATA_RAW, IV => NULL) ;
— DBMS_PKG_CRYPTO.DECRYPT 수행 결과 나온 복호화된 raw data 를 varchar2 로 변환하면 끝!
CONVERTED_STRING := UTL_I18N.RAW_TO_CHAR(DECRYPTED_RAW, ‘AL32UTF8’) ;
RETURN CONVERTED_STRING;
EXCEPTION
WHEN OTHERS THEN
RETURN INPUT_STRING;
END DECRYPT;
END;
사용할유저에게실행권한부여
기본적으로 DBMS_CRYPTO 패키지 권한 만 부여하면 되지만, 혹시 안 될 경우 두 개의 패키지에 대한 사용 권한을 준다.
grant execute on pkg_crypto to USER;
테스트
패키지가 정상적으로 생성되었는지 테스트
SQL> select sys.pkg_crypto.encrypt ( ‘test’ ) from dual ;
A04B686B118AF67B
SQL> select sys.pkg_crypto.decrypt ( ‘A04B686B118AF67B’ ) from dual ;
test
SQL> create table test_crypto (id int , pwd varchar2(64)) ;
SQL> insert into test_crypto values (1, sys.pkg_crypto.encrypt(‘password1’) ) ;
SQL> insert into test_crypto values (2, sys.pkg_crypto.encrypt(‘password2’) ) ;
SQL> commit ;
SQL> select * from test_crypto ;
1 8A65E0E80532B5FADACA597658B8E8E0
2 8A65E0E80532B5FA6635EBCA6EB4D195
SQL> select id , sys.pkg_crypto.decrypt(pwd) from test_crypto ;
1 password1
2 password2
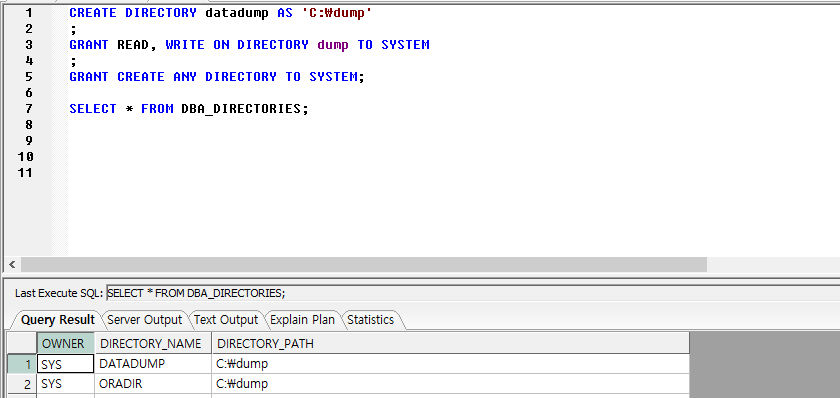
패키지소스암호화 (WRAP)
패키지 바디 부분을 SQL 파일로 저장한 후에, 해당 SQL파일을 오라클의 WRAP 명령을 이용하여 소스를 암호화 한다.
암호화된 소스를 이용하여 패키지를 생성한다.
패키지 바디 부분을 pkg_crypto.sql 파일로 만든 후에, WRAP 명령을 이용하여 소스 암호화를 진행 한다.
BGP(Border Gateway Protocol): AS 사이에서 이용되는 라우팅 프로토콜. 대규모 네트워크(수천만의 경로 수)에 대응하도록 설계됐다. 그래서 BGP로 동작하는 라우터는 비교적 고가인 제품이 많다.
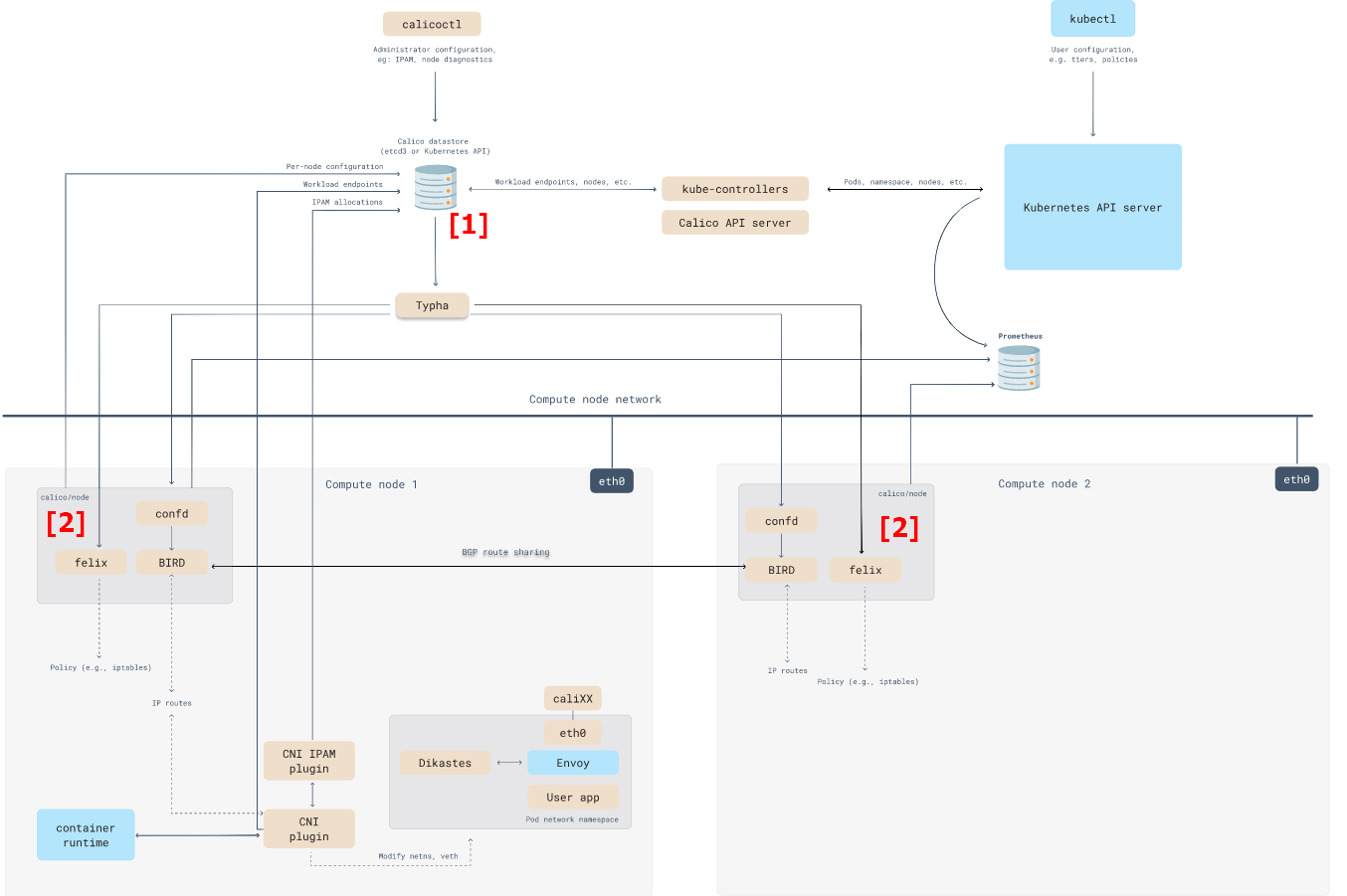
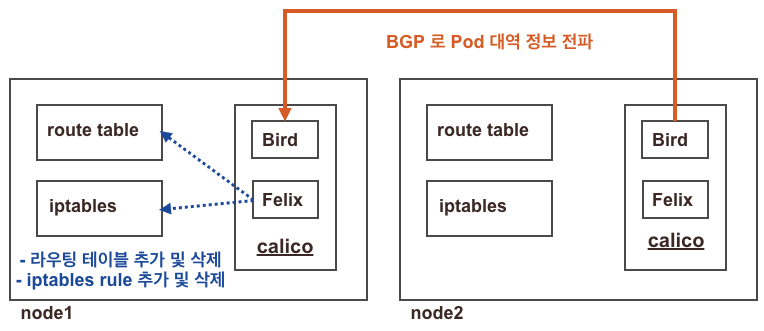
AS(Autonomous System): 하나의 정책을 바탕으로 관리되는 네트워크(자율 시스템)를 말한다. ISP, 엔터프라이즈 기업, 공공기관 같은 조직이 이에 해당하며 인터넷은 이러한 자율 시스템의 집합체이다.여러가지 구성 요소가 많지만, 일단 눈여겨 볼 내용은 Calico가 사용하는 Datastore[1]와 마스터 노드를 포함한 모든 노드들에 존재하는 Calico Pods[2]
Felix (필릭스) : 인터페이스 관리, 라우팅 정보 관리, ACL 관리, 상태 체크
BIRD (버드): BGP Peer 에 라우팅 정보 전파 및 수신, BGP RR(Route Reflector)
Confd : calico global 설정과 BGP 설정 변경 시(트리거) BIRD 에 적용해줌
Datastore plugin : calico 설정 정보를 저장하는 곳 – k8s API datastore(kdd) 혹은 etcd 중 선택
Calico IPAM plugin : 클러스터 내에서 파드에 할당할 IP 대역
calico-kube-controllers : calico 동작 관련 감시(watch)
calicoctl : calico 오브젝트를 CRUD 할 수 있다, 즉 datastore 접근 가능
구성 요소 확인하기
데몬셋으로 각 노드에 calico-node 파드가 동작하여, 해당 파드에 bird, felix, confd 등이 동작 + Calico 컨트롤러 파드는 디플로이먼트로 생성
Calico의 특징은 BGP를 이용해 각 노드에 할당된 Pod 대역의 정보를 전달한다. 즉, 쿠버네티스 서버뿐만 아니라 물리적인 라우터와도 연동이 가능 하다는 뜻이다. (Flannel의 경우 해당 구성 불가)
Calico Pod 안에서 Bird라고 하는 오픈소스 라우팅 데몬 프로그램이 프로세스로 동작하여 각 Node의 Pod 정보가 전파되는 것이다.
이후 Felix라는 컴포넌트가 리눅스 라우터의 라우팅 테이블 및 iptables rule에 전달 받은 정보를 주입하는 형태이다.
confd는 변경되는 값을 계속 반영할 수 있도록 트리거 하는 역할이다.
Calico 기본 통신 과정 확인하기
calicoctl 설치
리소스 관리를 위해 Calico CLI를 설치 및 구성
마스터 노드 확인
Calico CNI 설치시, 데몬셋이므로 모든 노드에 칼리코 파드가 하나씩 존재하게 된다. (calico-node-*)
칼리코 컨트롤러가 하나 존재하는 것을 확인할 수 있다.
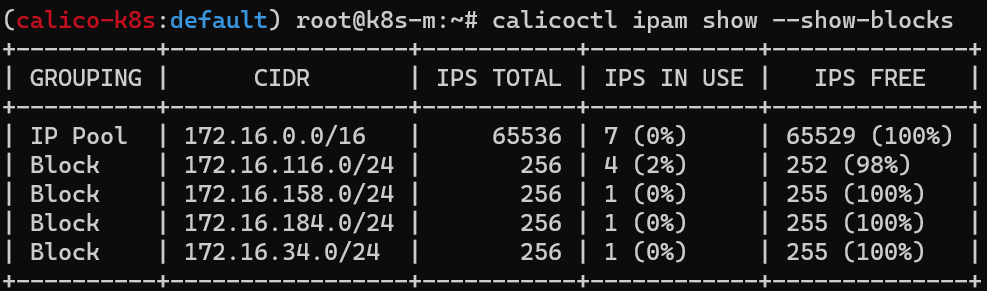
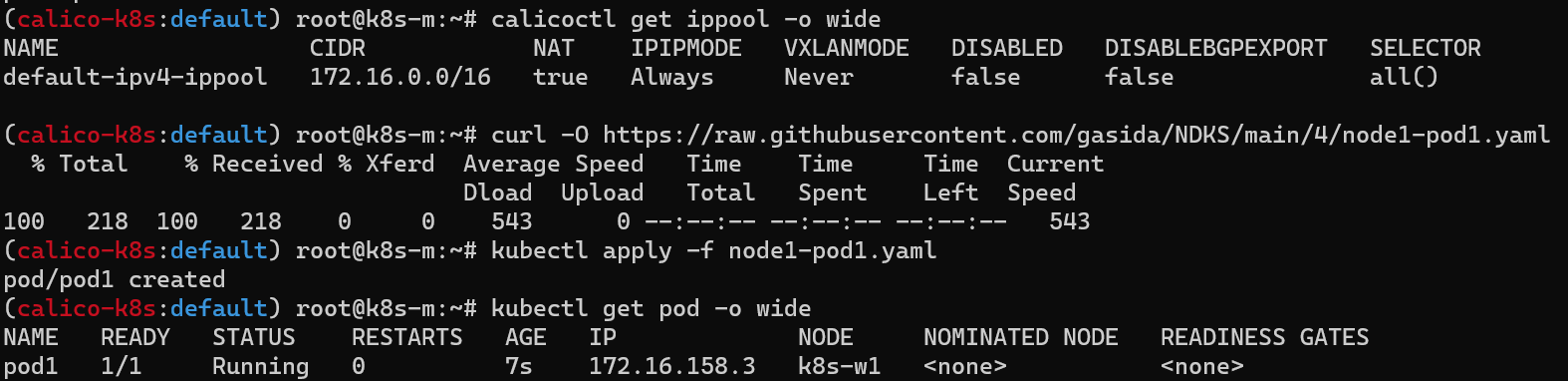
calicoctl ipm show 명령어를 통해, IAPM 정보를 확인할 수 있다. 아래 스크린샷에서는 172.16.0.0/16 대역을 해당 쿠버네티스 클러스터에서 사용할 수 있다는 내용을 알 수 있다.
IPAM(IP Address Management): 풍부한 사용자 환경을 통해 IP 주소 인프라의 엔드 투 엔드 계획, 배포, 관리 및 모니터링을 지원하는 통합 도구 모음이다.
IPAM은 네트워크상의 IP 주소 인프라 서버 및 DNS(도메인 이름 시스템) 서버를 자동으로 검색하여 중앙 인터페이스에서 이들 서버를 관리할 수 있다.
옵션을 통해 아래와 같이 특정한 노드에 할당 가능한 대역대를 확인할 수도 있음(Block는 각 노드에 할당된 Pod CIDR 정보를 나타냄)
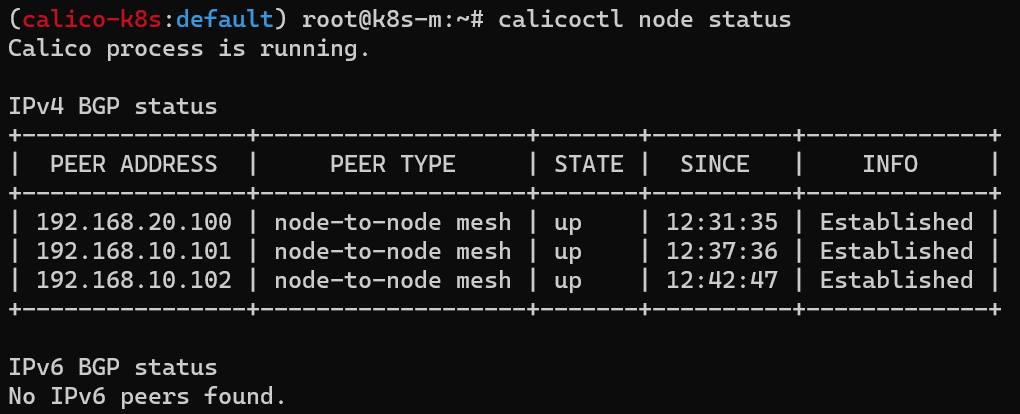
calicoctl node 정보 확인
ippool 정보 확인
파드와 서비스 사용 네트워크 대역 정보 확인
실습 1.
동일 노드 내 파드 간 통신
결론: 동일 노드 내의 파드 간 통신은 내부에서 직접 통신됨
파드 생성 전 노드(k8s-w1)의 기본 상태
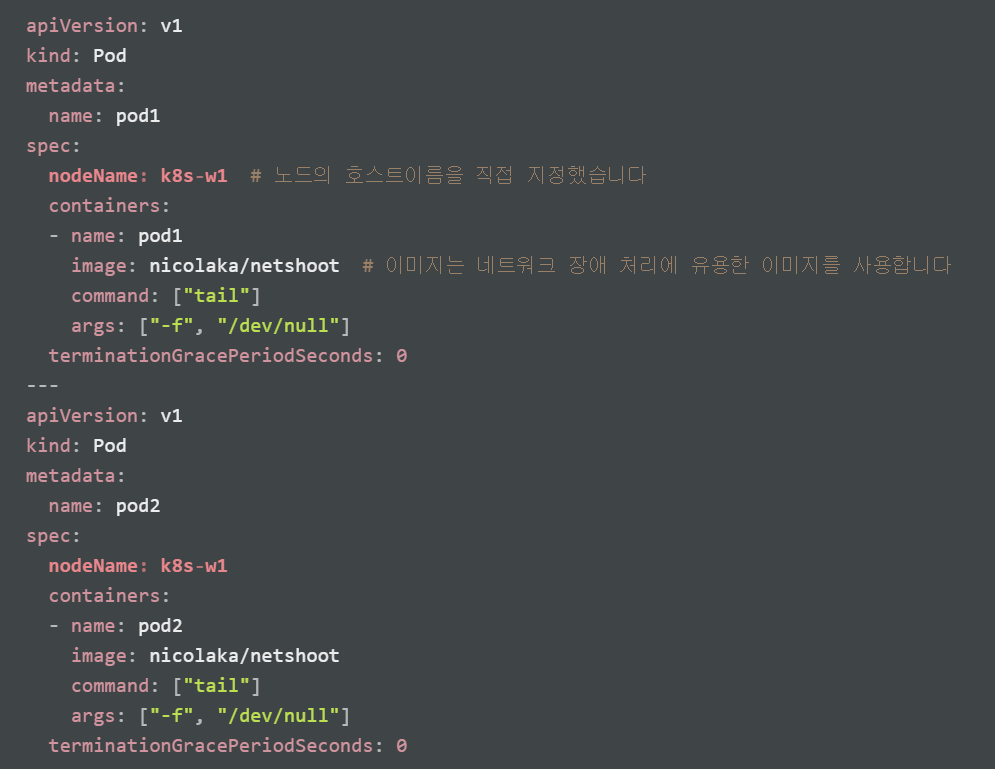
노드(k8s-w1)에 파드 2개 생성
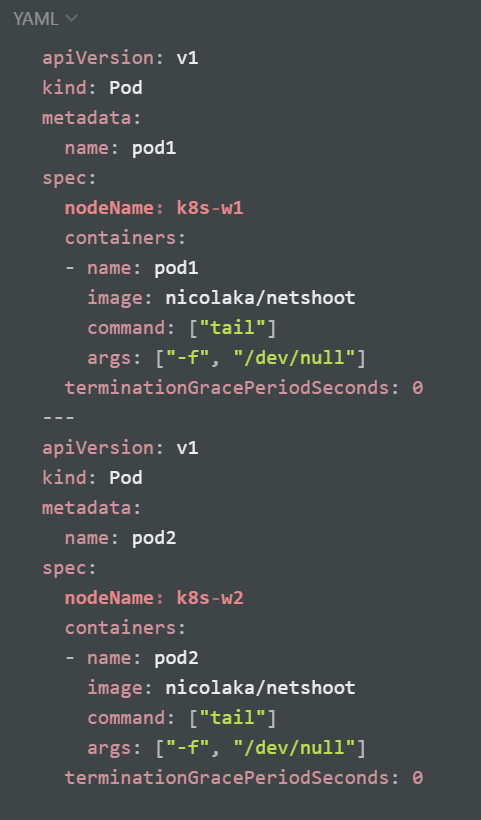
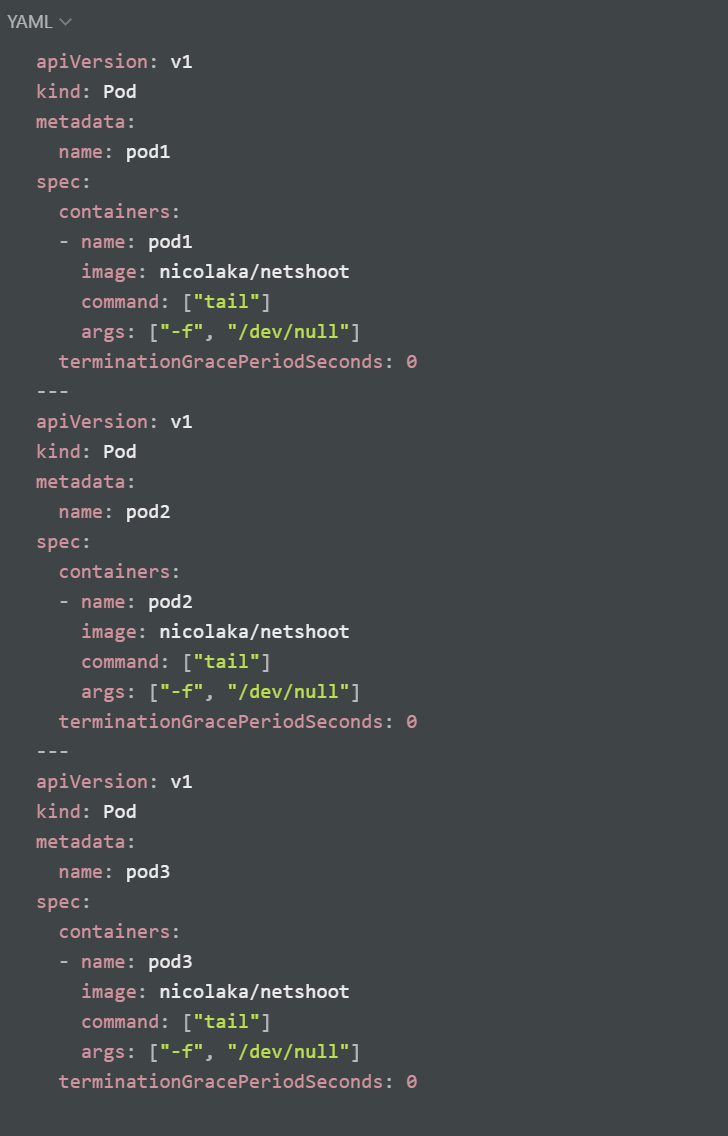
아래 내용으로 node1-pod2.yaml 파일 작성 후 파드 생성
파드 생성 전후의 변화를 관찰하기 위해 터미널 하단 추가 탭에watch calicoctl get workloadEndpoint 명령어를 사용하여 모니터링
calicoctl 명령어로 endpoint 확인: veth 정보도 확인할 수 있음
생성된 파드 정보 확인
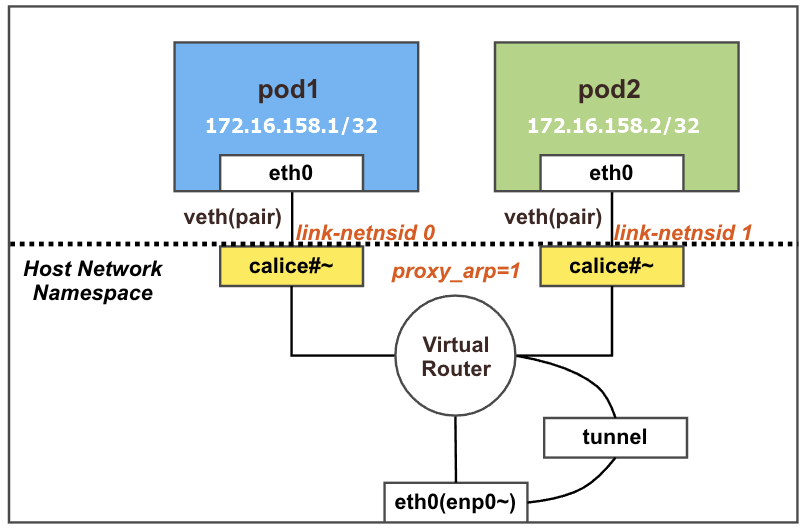
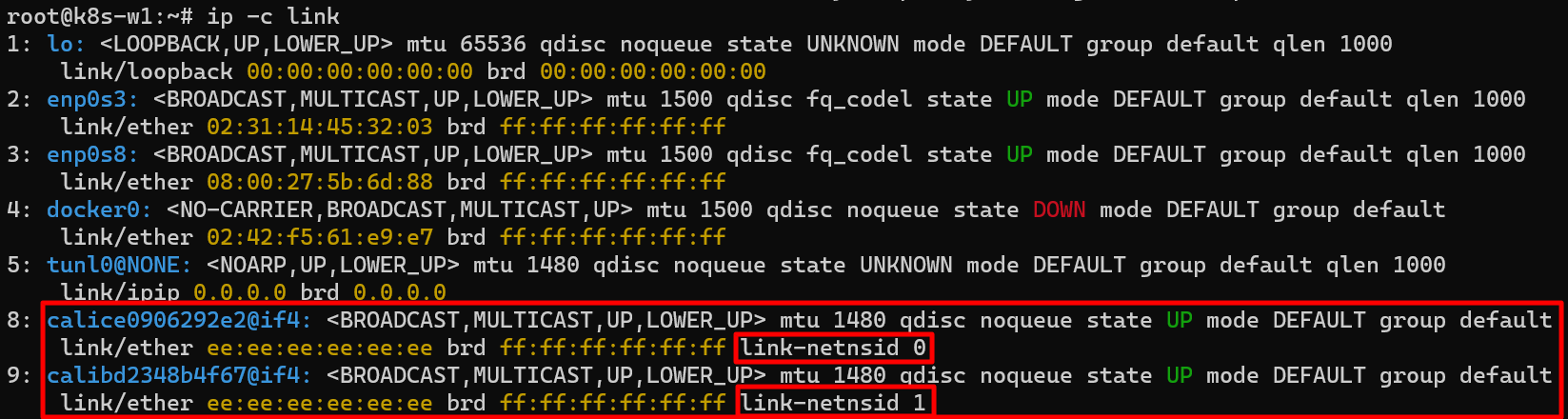
네트워크 인터페이스 정보 확인(k8s-w1)
calice#~ 두개 추가된 것을 확인할 수 있음
각각 net ns 0,1로 호스트와 구별되는 것을 확인할 수 있음
네트워크 네임스페이스 확인
아래 2개 PAUSE 컨테이너가 각각 파드별로 생성된 것을 확인할 수 있음
바로 위 스크린샷인 link-netnsid 0, link-netnsid 1과 매칭됨
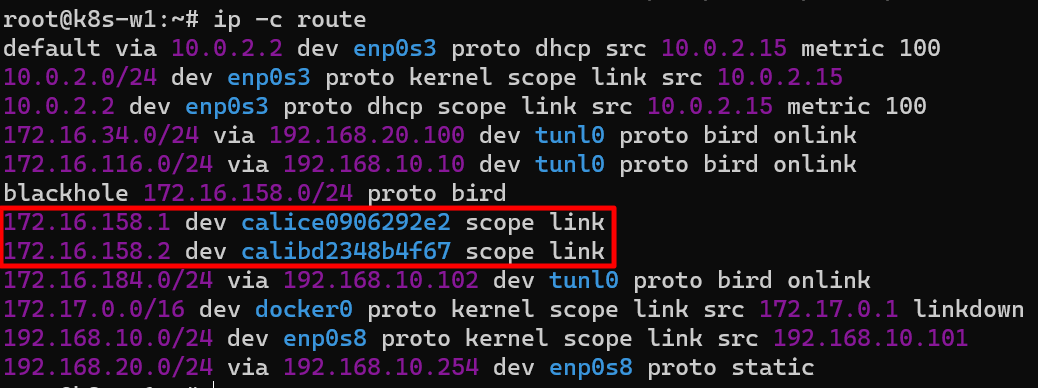
라우팅 테이블 확인
파드의 IP/32bit 호스트 라우팅 대역이 라우팅 테이블에 추가된 것을 확인할 수 있음
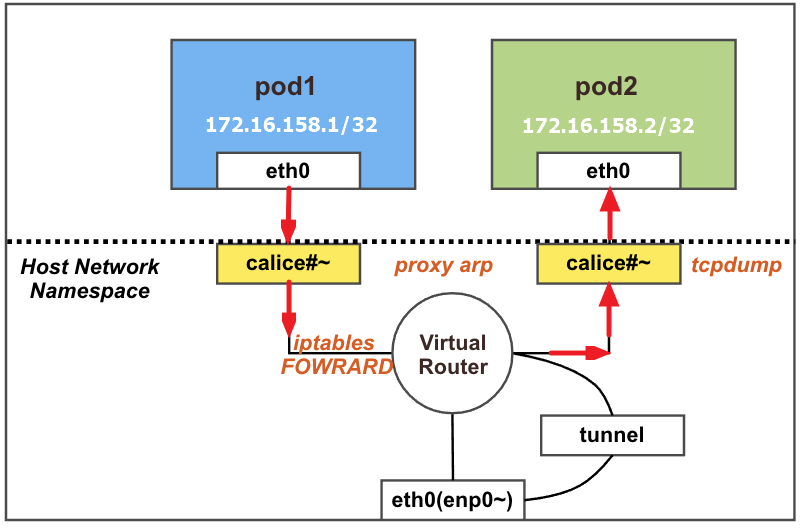
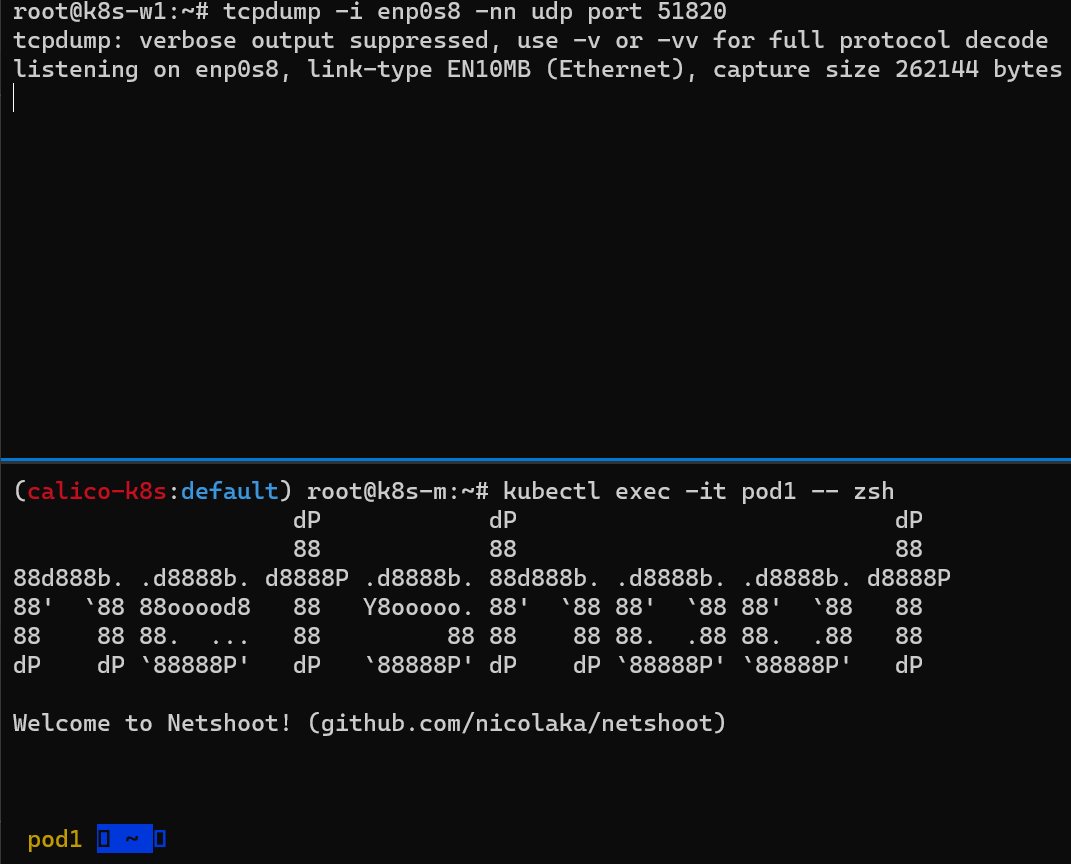
파드간 통신 실행 이해
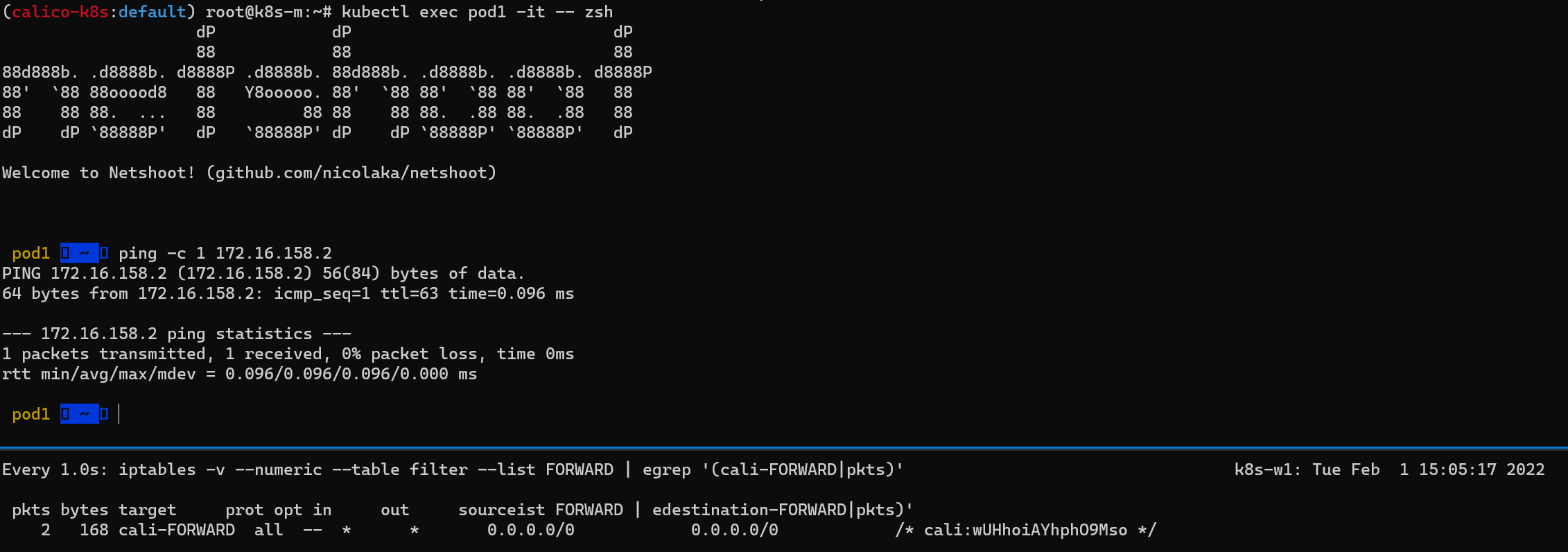
(위) 마스터 노드에서 Pod1 Shell에 접근하여 Pod2로 Ping 테스트
(아래) 워커 노드(k8s-w1)에서 iptables 필터 테이블에 FORWARD 리스트 중 cali-FORWARD 룰 정보를 필터링해서 watch로 확인
테스트 결과 아래 이미지와 같이 Host iptables에서 FOWRARD라는 테이블의 허용 조건에 따라 정상적으로 통신이 가능한 것을 확인할 수 있다.
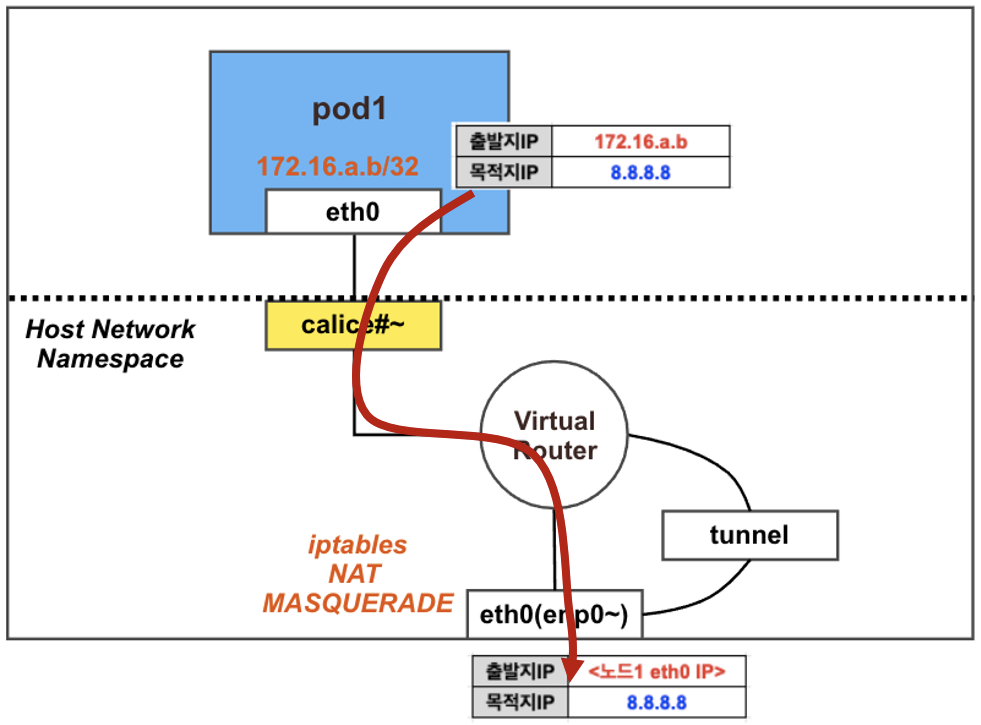
파드에서 외부(인터넷)로의 통신
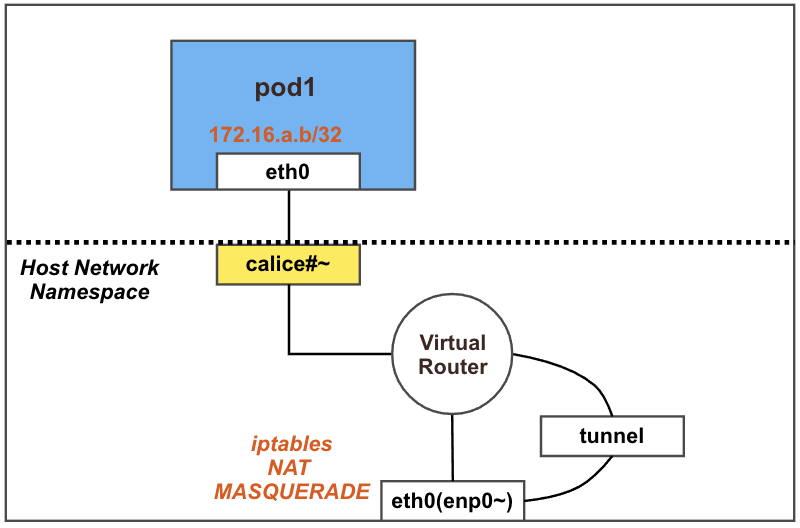
결론: 파드에서 외부(인터넷) 통신 시에는 해당 노드의 네트워크 인터페이스 IP 주소로 MASQUERADE(출발지 IP가 변경) 되어서 외부에 연결됨
파드 배포 전 calico 설정 정보 확인 & 노드에 iptables 확인
마스터 노드에서 아래 내용 확인: natOutgoing의 기본값이 true로 설정되어 있는 것을 확인 할 수 있다. 즉 이 노드에서 외부로 통신할 때 NAT의 MASQUERADE를 사용하겠다는 의미이다.
NAT – MASQUERADE : 조건에 일치하는 패킷의 출발지 주소를 변환하는 것. 내부에서 전달되는 요청의 출발지 주소를 조건에 지정된 인터페이스의 IP로 변환한다.
워커 노드(k8s-w1)에서도 외부로 통신시 MASQUERADE 동작 Rule이 존재하는 것을 확인할 수 있다.
마스터 노드에서 워커 노드(k8s-w1)에 아래 내용의 파드 1개 생성
외부 통신 가능 여부 확인
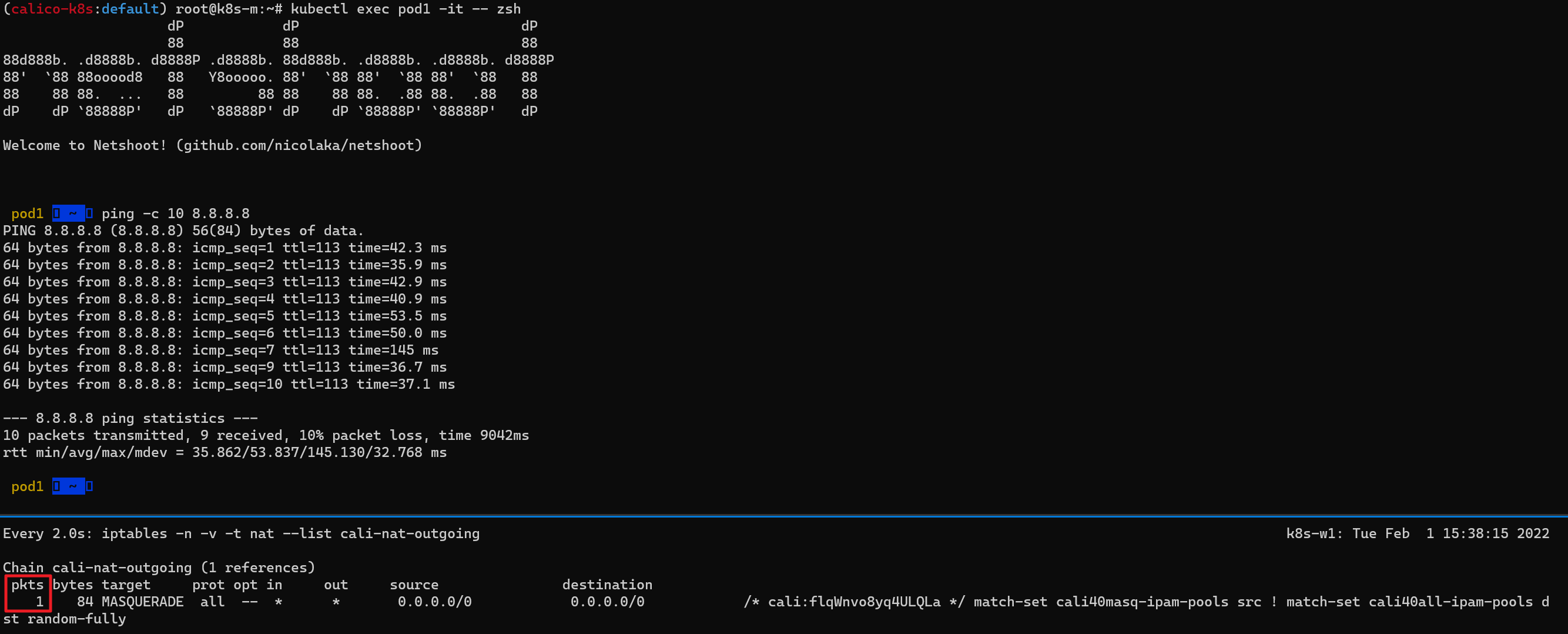
통신 전, 워커 노드(k8s-w1)에 iptables NAT MASQUERADE 모니터링을 활성화 하면 외부 통신시 pkts값이 증가하는지 확인할 수 있다.
(위) 마스터 노드에서 Pod1 Shell 실행 후, 8.8.8.8로의 통신 성공
(아래) pkts 값이 이전 이미지와 다르게 증가한 것을 확인할 수 있다.
다른 노드에서 파드 간 통신
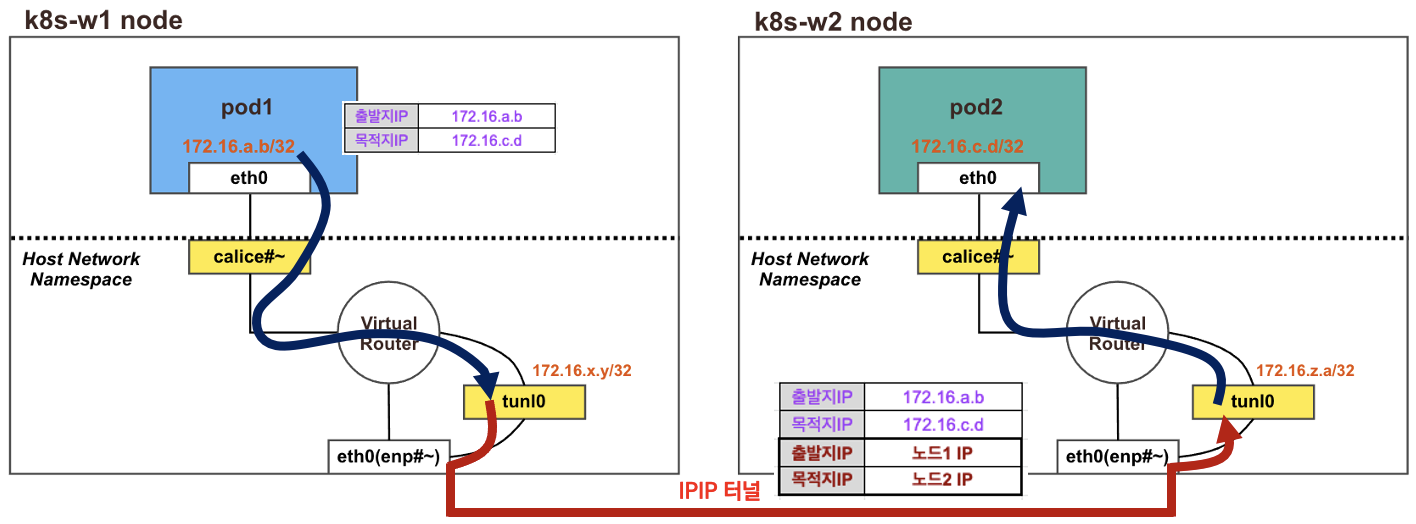
결론: 다른 노드 환경에서 파드 간 통신시에는 IPIP터널(기본값) 모드를 통해서 이루어진다.
각 노드에 파드 네트워크 대역은 Bird에 의해서 BGP로 광고 전파/전달 되며, Felix에 의해서 호스트의 라우팅 테이블에 자동으로 추가/삭제 된다.
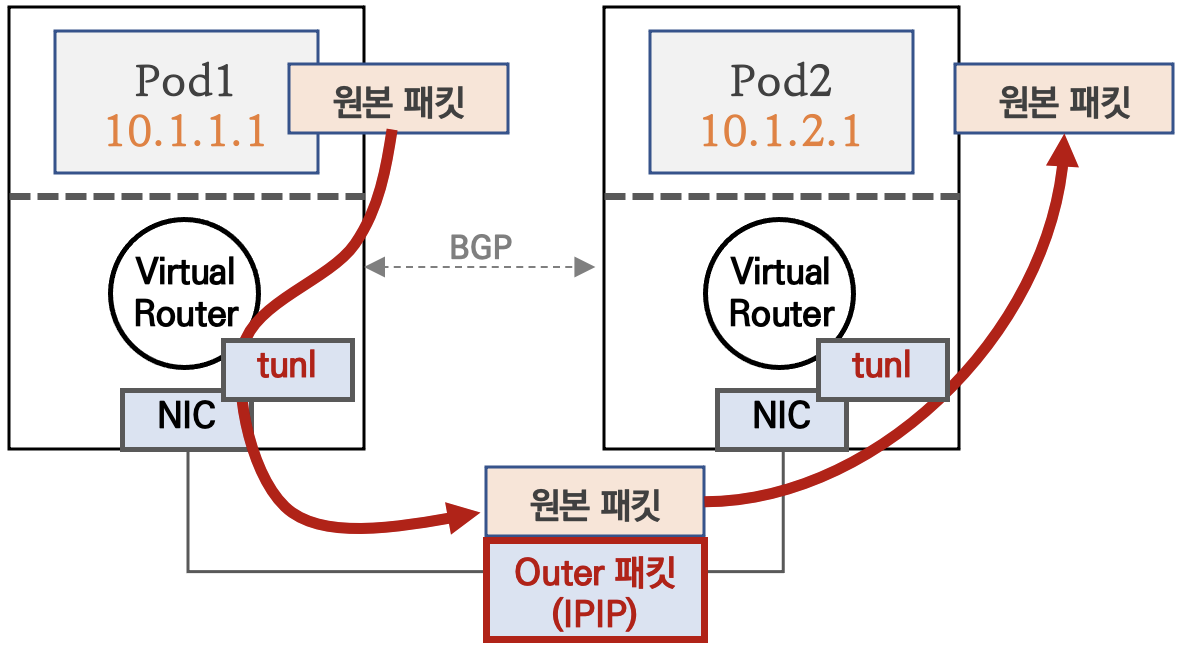
다른 노드 간의 파드 통신은 tunl0 인터페이스를 통해 IP 헤더에 감싸져서 상대측 노드로 도달 후 tunl0 인터페이스에서 Outer 헤더를 제거하고 내부 파드와 통신한다.
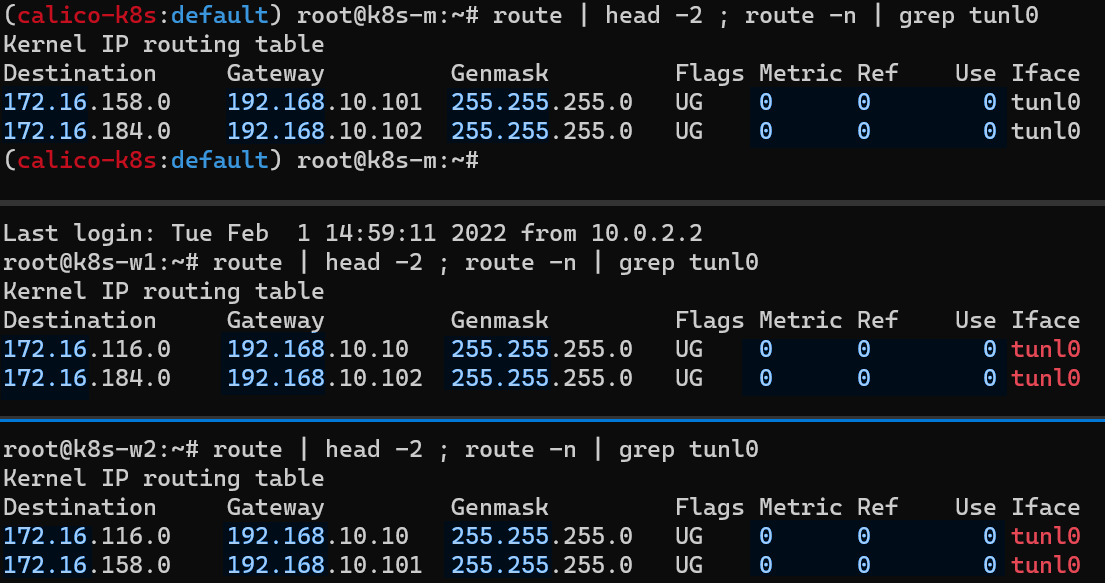
파드 배포 전, 노드에서 BGP에 의해 전달 받은 정보가 호스트 라우팅 테이블에 존재하는지 확인
아래 명령어를 통해 나머지 노드들의 파드 대역을 자신의 호스트 라우팅 테이블에 가지고 있고, 해당 경로는 tunl0 인터페이스로 보내게 된다는 사실을 알 수 있다.
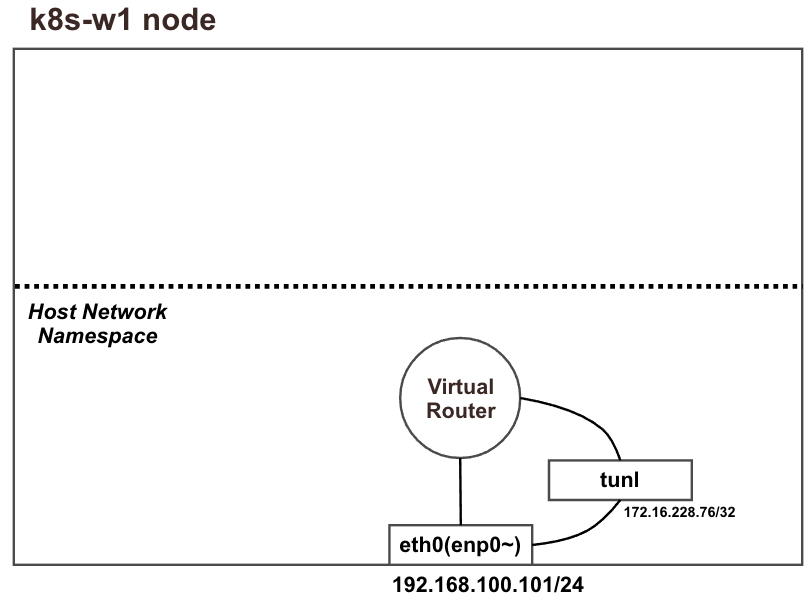
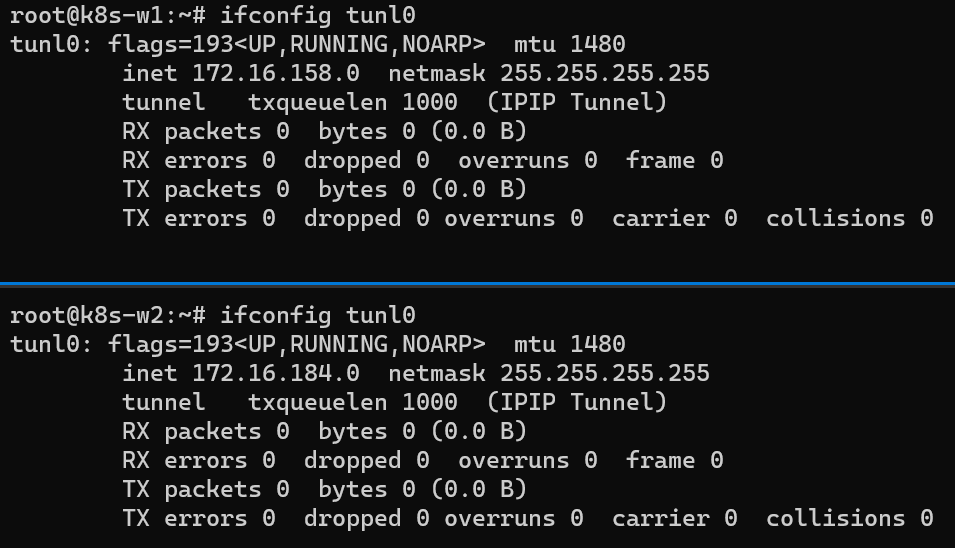
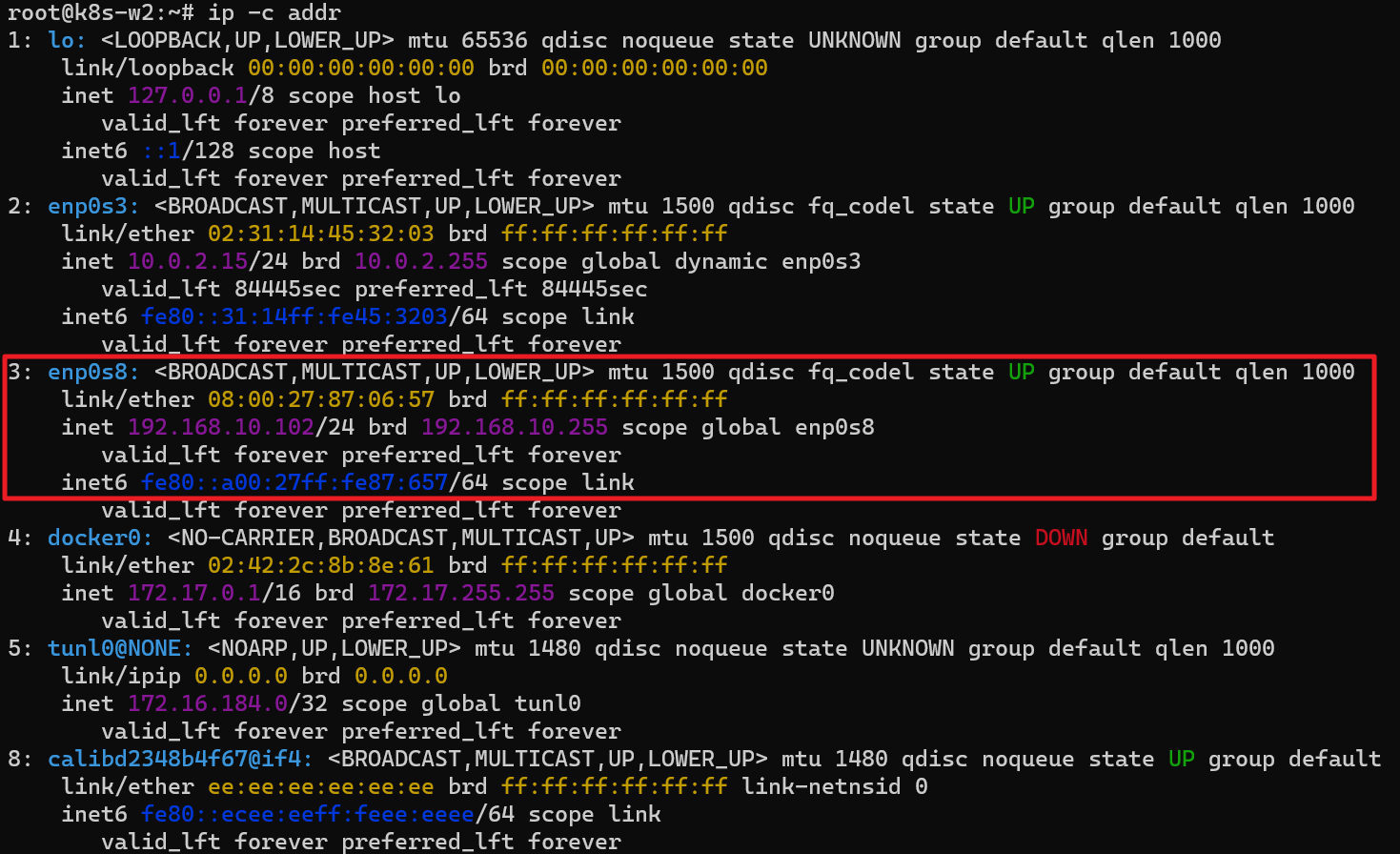
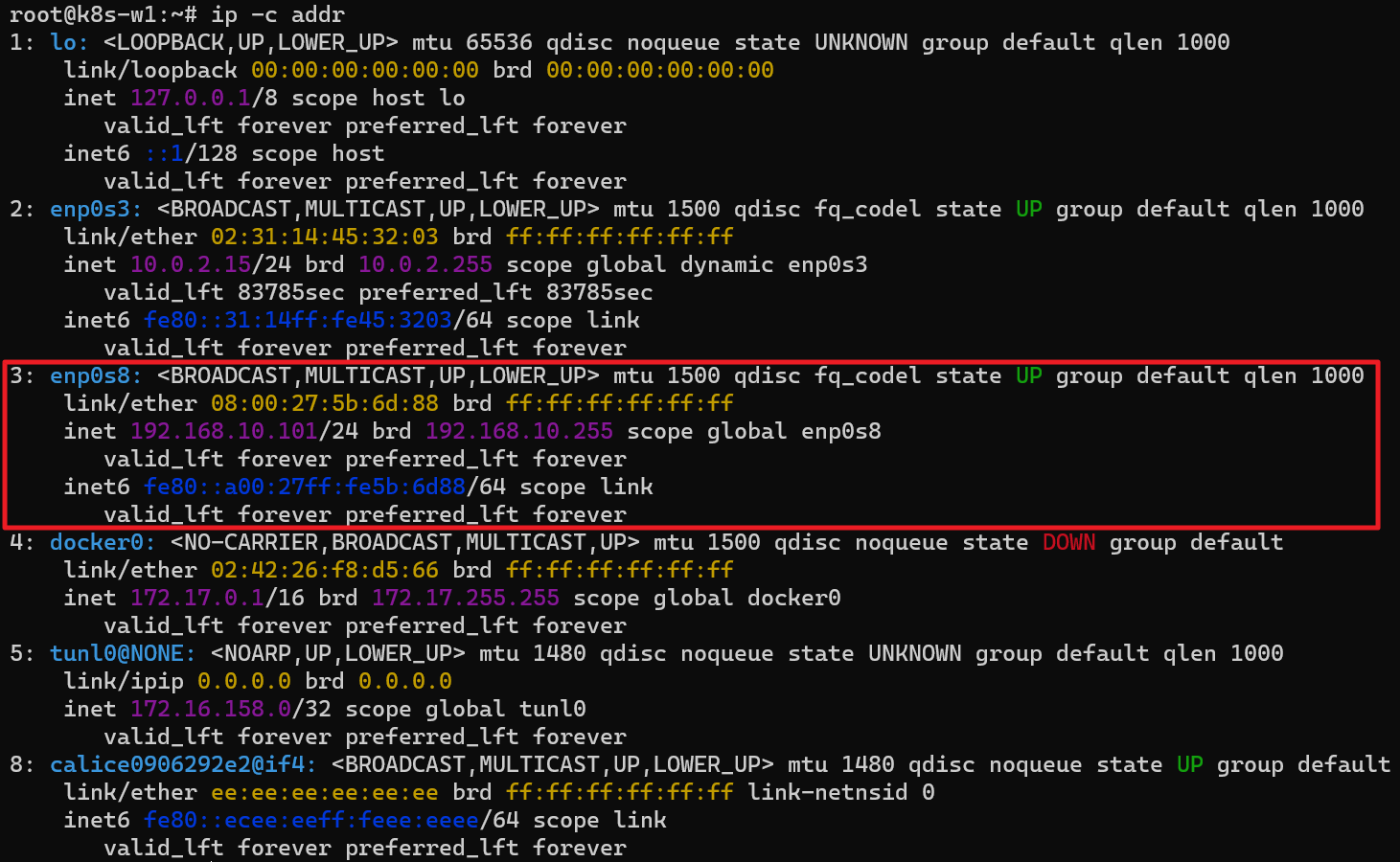
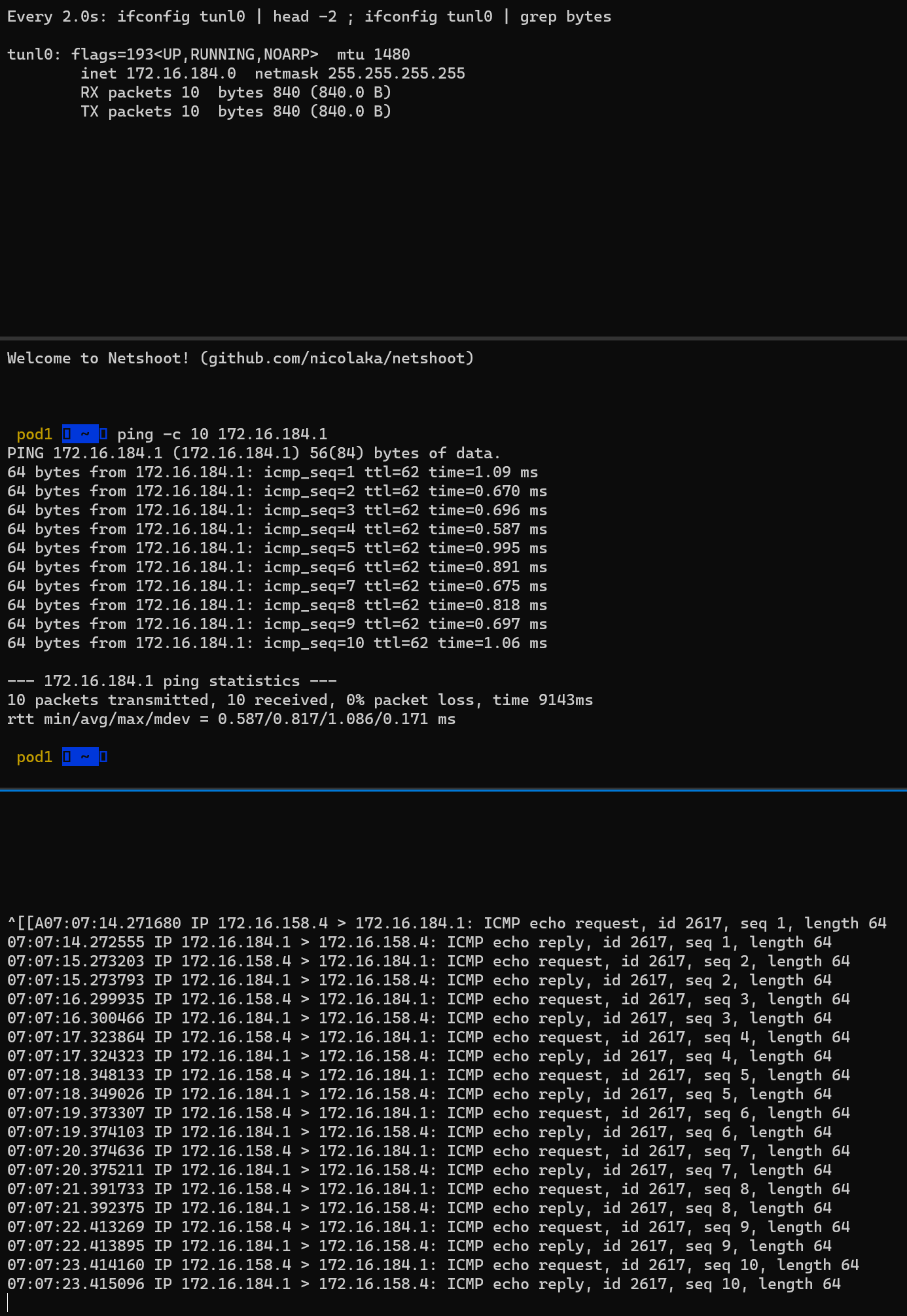
워커 노드(k8s-w1, w2)의 tunl0 정보 확인
터널 인터페이스가 IP에 할당되어 있음
MTU는 1480 (칼리코 사용 시 파드의 인터페이스도 기본 MTU 1480 사용)
현재 TX/RX 카운트는 0 –> 잠시 후, 오버레이 통신시 카운트 값이 증가할 것
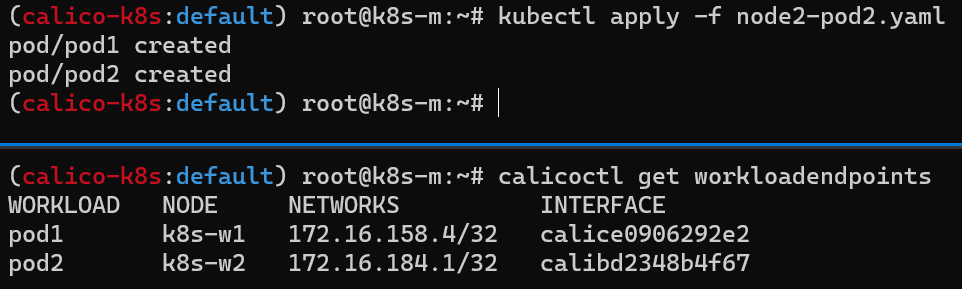
마스터 노드에서 워커 노드(k8s-w1, w2) 대상으로 각각 파드 1개씩 생성
calicoctl 명령어를 이용하여 생성된 파드의 엔드포인트 확인
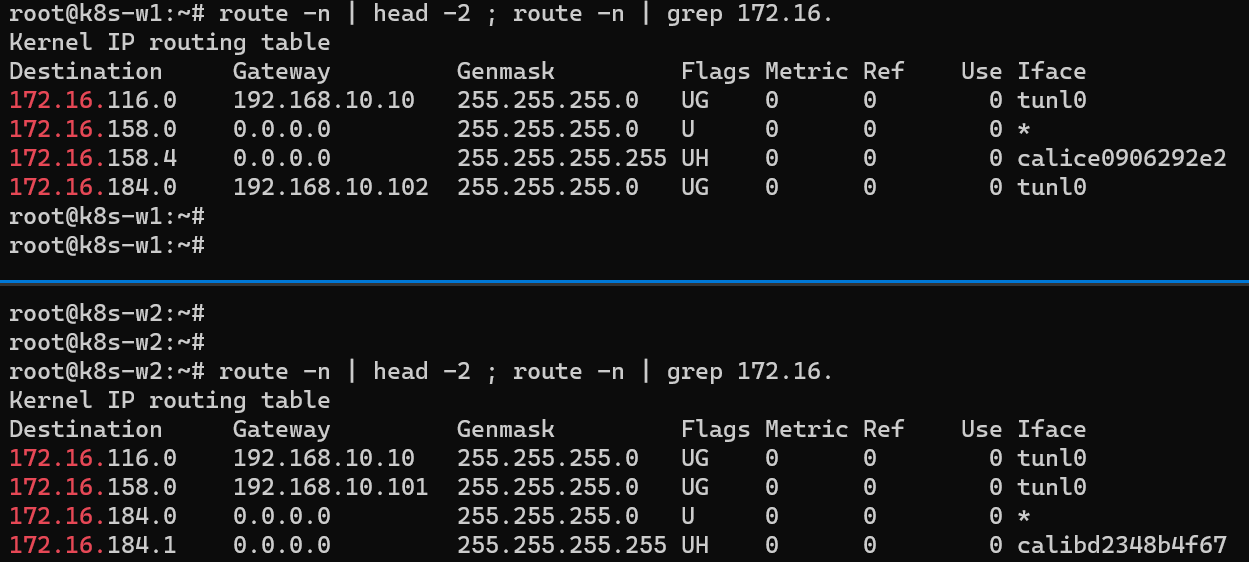
각 노드에서 파드 간 통신을 처리하는 라우팅 정보 확인
k8s-w1(172.16.158.4/32) 노드에서 w2(172.16.184.0) 노드 대역에 통신하려면 192.168.10.102를 거쳐야 한다는 것을 확인할 수 있다.
반대로 w2(172.16.184.1/32) 노드에서 w1(172.16.158.0) 노드 대역에 통신하려면 192.168.10.101를 거쳐야 한다.
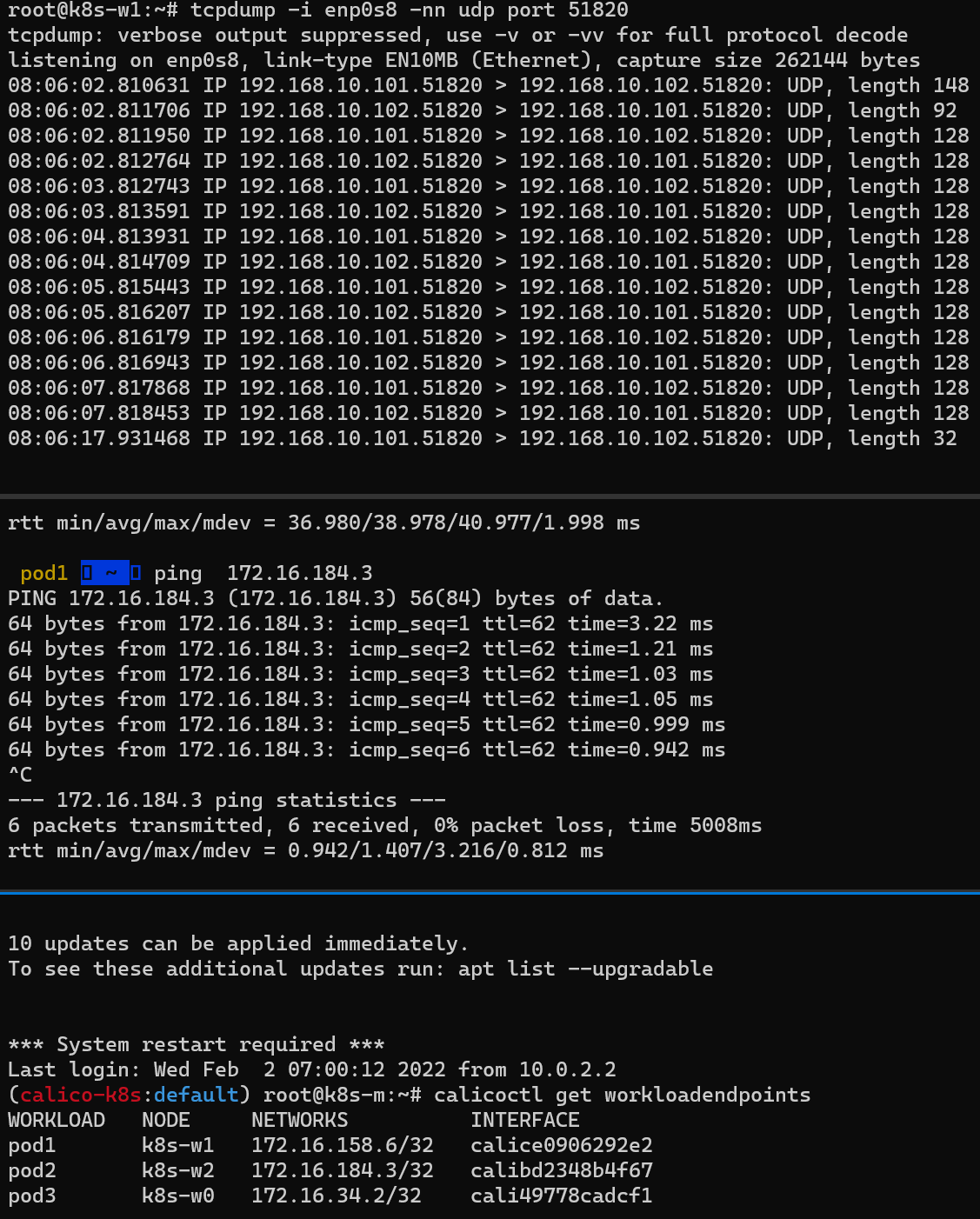
다른 노드 파드 간 통신이 어떻게 실행되는지 확인 ⇒ IPIP
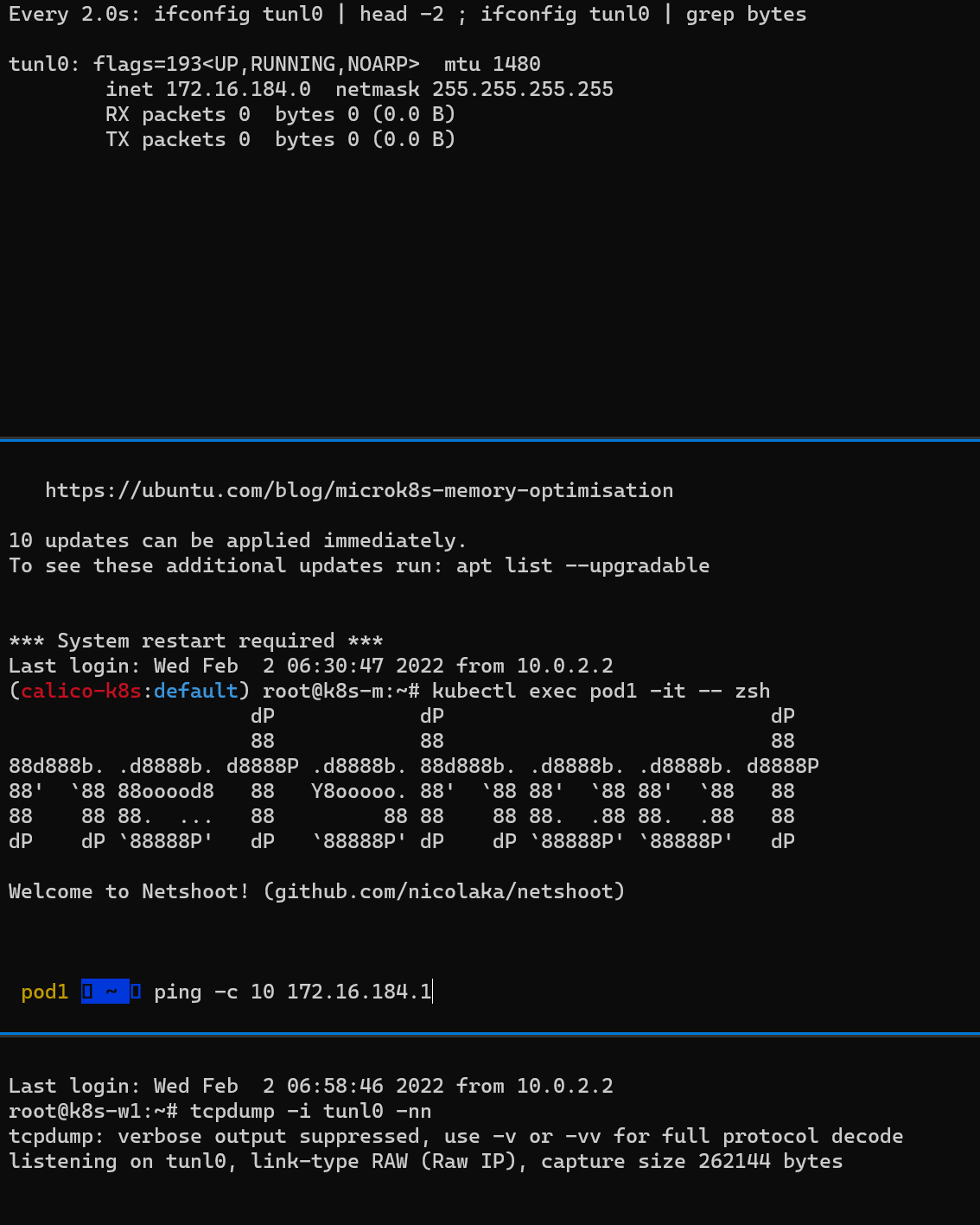
(상) Pod2가 속한 노드(k8s-w2)에 tunl0 인터페이스 TX/RX 패킷 카운트 모니터링 세팅
(중) 마스터 노드에서 Pod1 Shell 접속 후, Pod2로 Ping 통신 테스트 준비
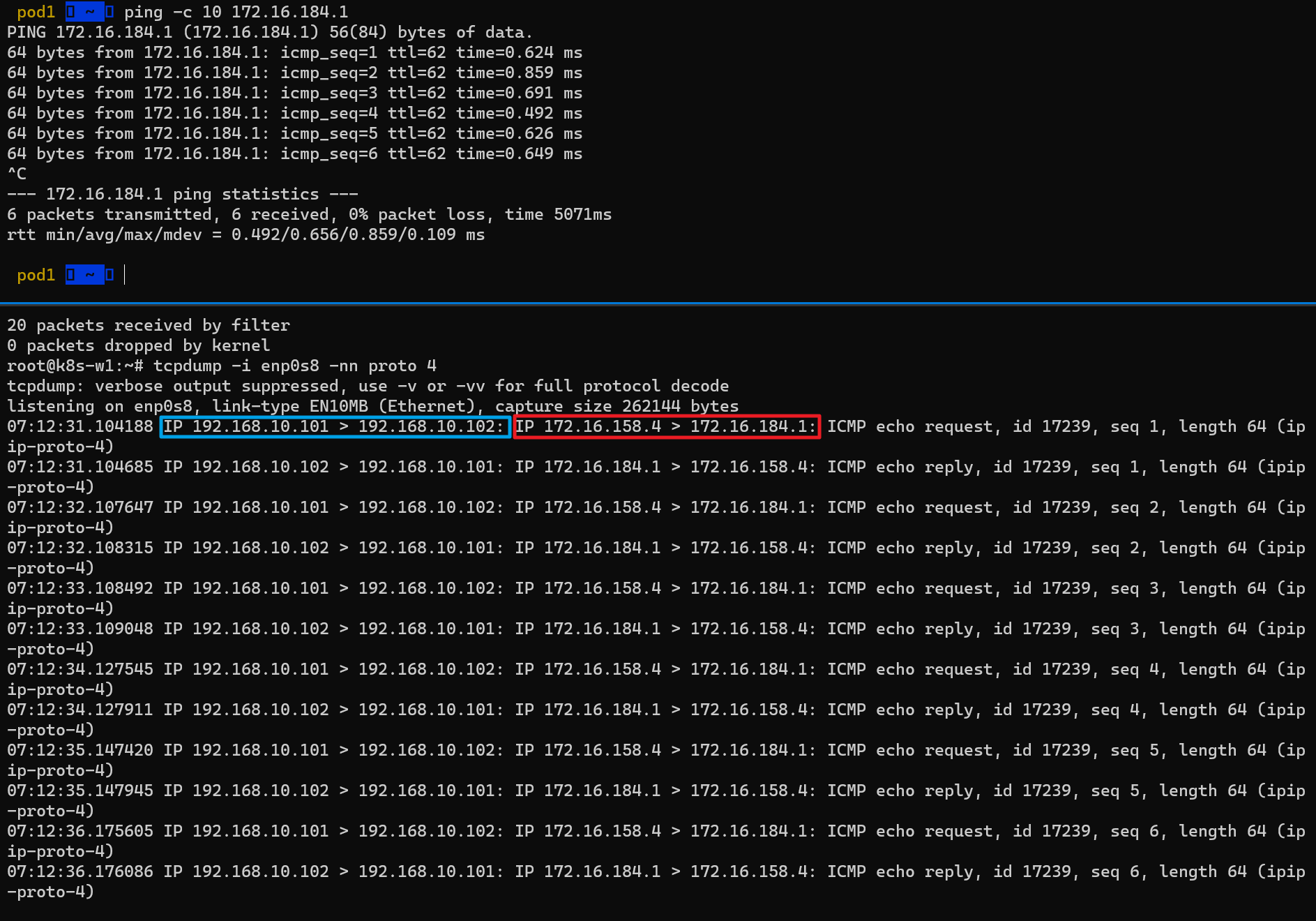
(하) Pod1이 속한 노드(k8s-w1)에서 패킷 덤프 세팅: tunl0 – 터널 인터페이스에 파드간 IP 패킷 정보를 확인할 수 있음
결과
(중) Pod1 –> Pod2로 정상 통신 확인
(상) tunl0 인터페이스의 TX/RX 패킷 카운트가 각각 10개로 증가
(하) 실제 통신을 하게 되는 파드 간 IP 패킷 정보 확인
실제로 오버레이 통신을 하고 있는지 확인하기 위해 패킷덤프 명령어를 아래와 같이 수정하여 Ping 통신을 다시 하였고, 결과적으로 IP Outer(파란색 박스) 헤더 정보 안쪽에 Inner(빨간색 박스) 헤더가 1개 더 있음을 확인할 수 있다.
Calico 네트워크 모드
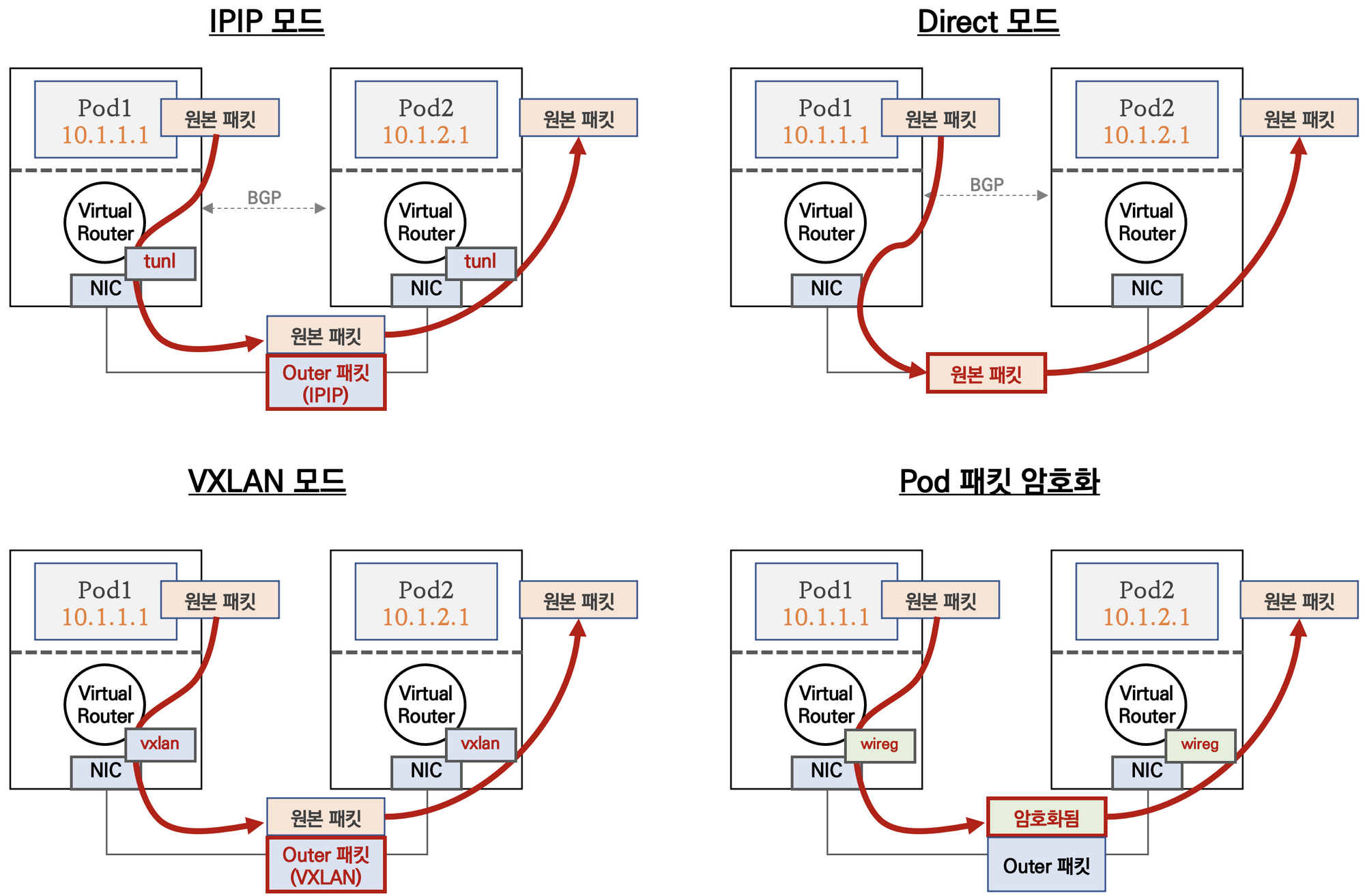
Calico Mode 요약
칼리코는 다양한 네트워크 통신 방법을 제공한다.
IPIP 모드
파드 간 통신이 노드와 노드 구간에서는 IPIP 인캡슐레이션을 통해 이루어진다.
단, Azure 네트워크에서는 IPIP 통신이 불가능하기 때문에 대신 VXLAN 모드를 사용한다고 한다.
Direct 모드
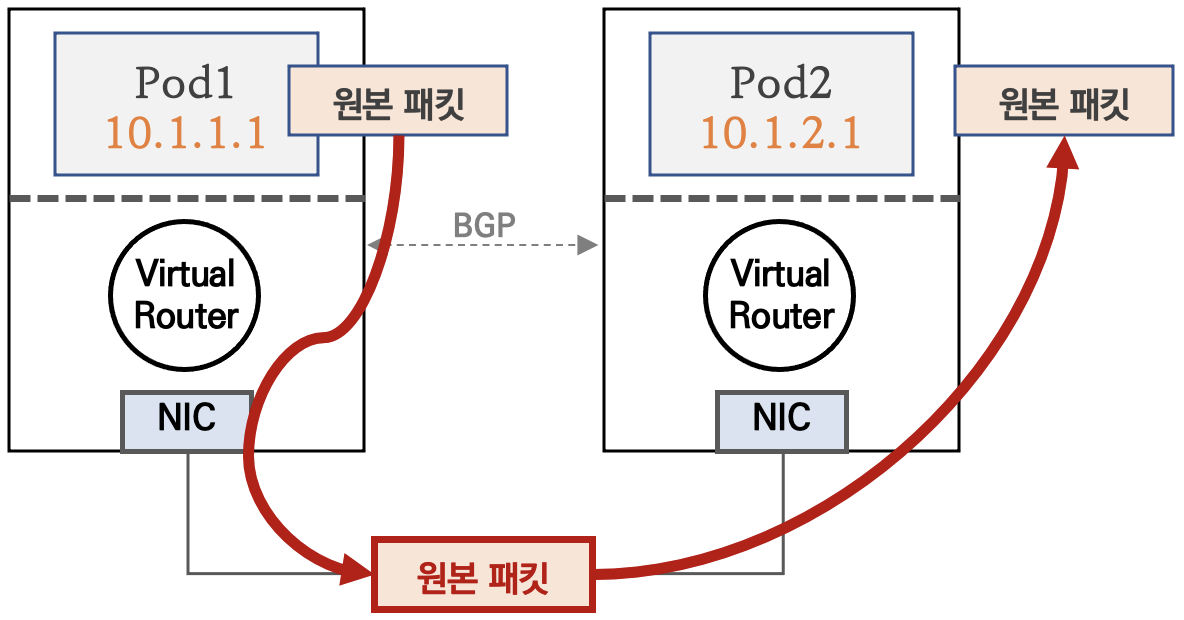
파드 통신 패킷이 출발지 노드의 라우팅 정보를 보고 목적지 노드로 원본 패킷 그대로 전달된다.
단, 클라우드 사업자 네트워크 사용 시, NIC에 매칭되지 않는 IP 패킷은 차단되니 NIC의 Source/Destination Check 기능을 Disable해야 정상 통신 가능 (AWS 문서 링크)
BGP 연동
Kubernetes 클러스터 내부 네트워크와 IDC 내부망 네트워크 간 직접 라우팅도 가능
VXLAN 모드
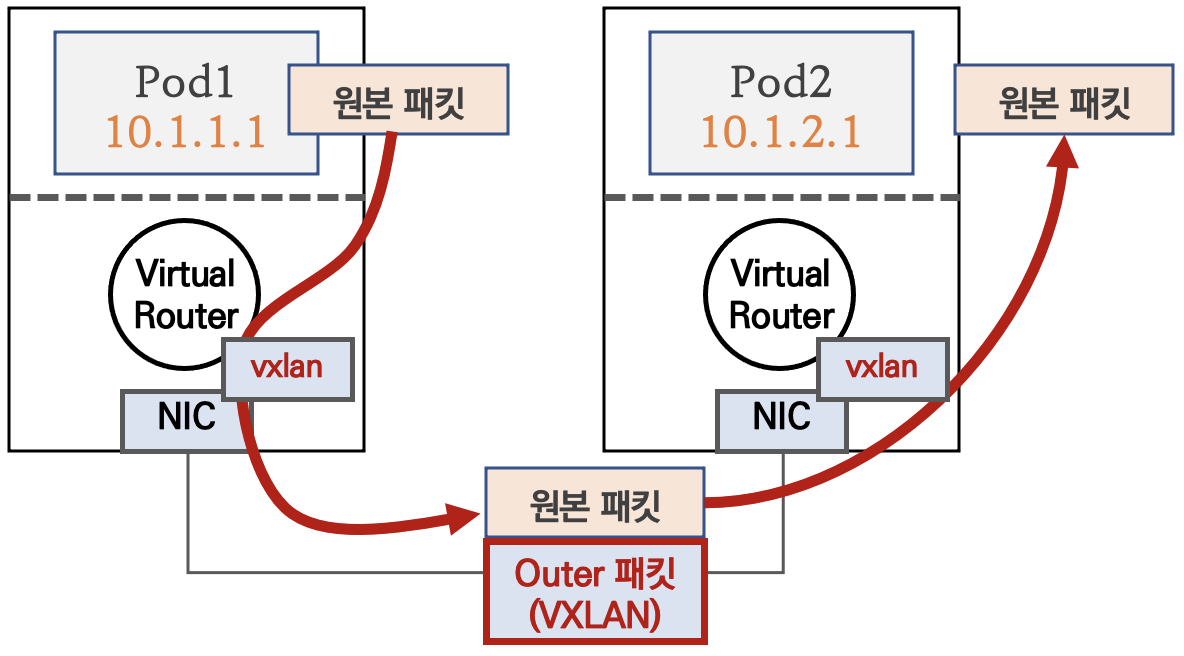
파드 간 통신이 노드와 노드 구간에서는 VXLAN 인캡슐레이션을 통해서 이루어진다.
다른 노드 간의 파드 통신은 vxlan 인터페이스를 통해 L2 프레임이 UDP – VXLAN에 감싸져 상대 노드로 도달 후 vxlan 인터페이스에서 Outer헤더를 제거하고 내부의 파드와 통신하게 된다.
BGP 미사용, VXLAN L3 라우팅을 통해서 동작한다.
UDP를 사용하므로 Azure 네트워크에서도 사용 가능하다.
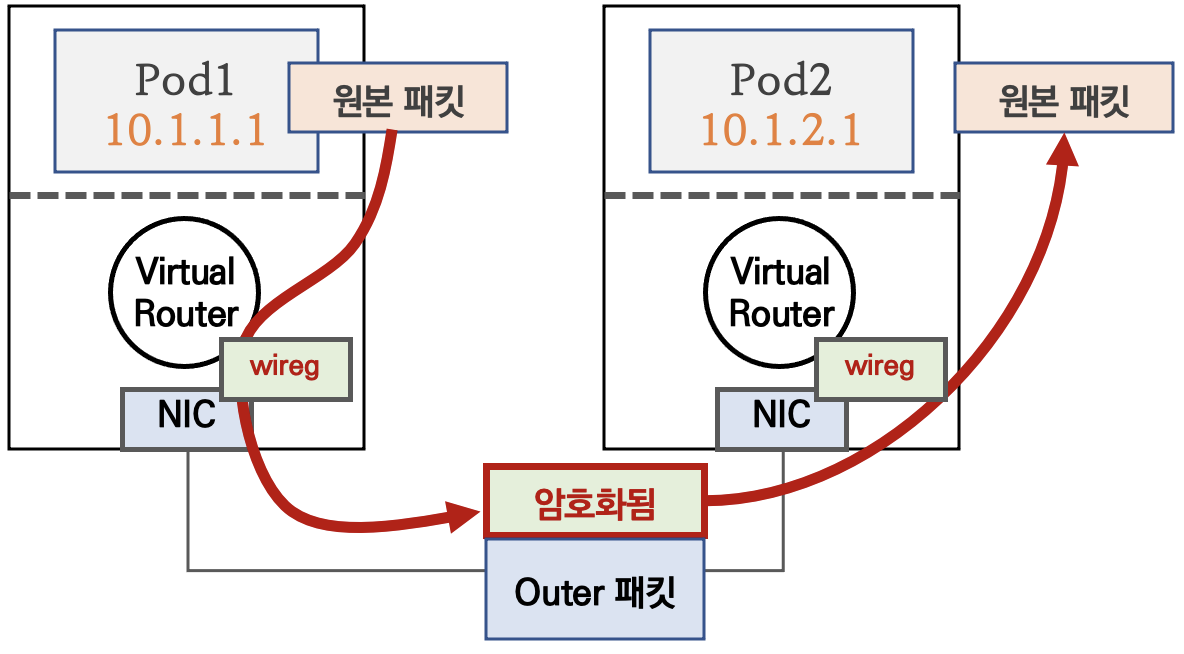
Pod 패킷 암호화(네트워크 레벨)
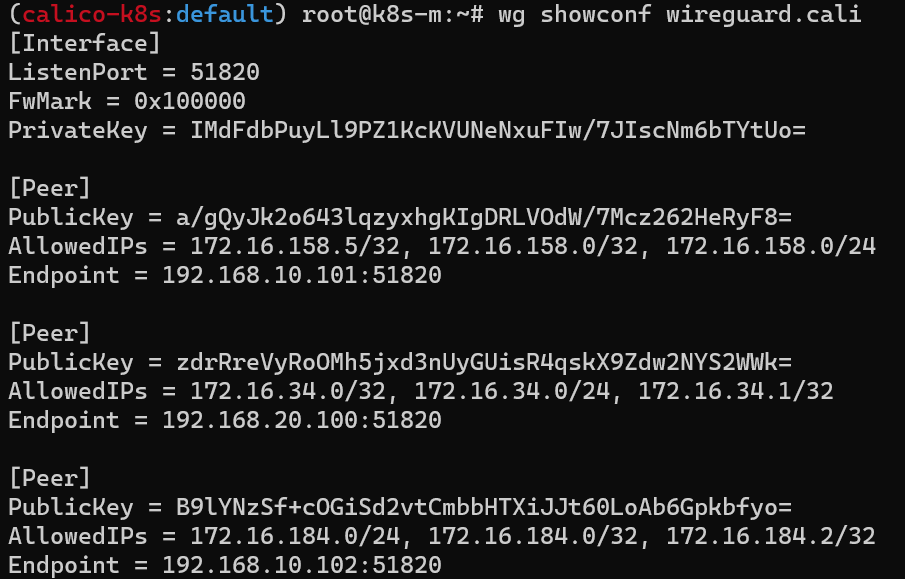
Calico의 다양한 네트워크 모드 환경 위에서 WireGuard 터널을 자동 생성 및 파드 트래픽을 암호화하여 노드 간 전달한다.
Yaml 파일에 간단하게 추가하는 것만으로도 네트워크 레벨의 패킷 암호화를 설정할 수 있다.
이제 이미지도 준비되었고, yaml 파일만 생성하여 기동해보면 된다.
도커와는 다르게 쿠버네티스의 경우에는 쿠버네티스 클러스터 내에서 동작하기 때문에 생성된 컨테이너의 IP 또한 클러스터 내의 CNI 네트워크 대역으로 할당된다.
그렇기 때문에 외부에서 해당 컨테이너에 접근하여 서비스를 호출하려면 Service를 통해 가능하다. AWS나 GCP같은 Public Cloud의 경우에는 Service에서 LoadBalnancer를 제공하여 외부로 노출할 IP를 할당 받지만, 우리가 테스트하는 방식과 같이 Baremetal(On-Premise) 환경에서는 LoadBalancer 기능이 없다. 그래서 LoadBalancer타입을 지원하게끔 하기 위해 MetalLB라는 놈을 사용해주어야 한다.
=================================
metallb.yaml 파일을 이용하여 파드와 기타 등등의 서비스를 실행한다.
이후, metallb-system 네임스페이스에 있는 리소스들을 조회해본다.
=================================
root@master:~/yaml# kc get all -n metallb-system
NAME READY STATUS RESTARTS AGE
pod/controller-675d6c9976-d5k57 1/1 Running 0 9s
pod/speaker-h4l8n 1/1 Running 0 9s
pod/speaker-rm54l 1/1 Running 0 9s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/speaker 2 2 2 2 2 beta.kubernetes.io/os=linux 9s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/controller 1/1 1 1 9s
NAME DESIRED CURRENT READY AGE
replicaset.apps/controller-675d6c9976 1 1 1 9s
이제 3-Tier환경의 컨테이너를 생성할 차례다.
yaml 파일의 경우 아래와 같다.
모든 항목들을 세세히 설명할 수는 없고 하나씩 찾아보면 기본적인 설정(포트/환경변수)만 되어있음을 볼 수 있다.
이 글에서는 가볍게 구성해보는 것이기 때문에 다음 글에서 좀 더 yaml 문법이나 파라미터 값을 공부해보아야 겠다.
(중략)
…
update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/unpack200 to provide /usr/bin/unpack200 (unpack200) in auto mode
update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/lib/jexec to provide /usr/bin/jexec (jexec) in auto mode
Setting up libxdmcp-dev:amd64 (1:1.1.3-0ubuntu1) …
Setting up x11proto-core-dev (2019.2-1ubuntu1) …
Setting up libxcb1-dev:amd64 (1.14-2) …
Setting up libx11-dev:amd64 (2:1.6.9-2ubuntu1.2) …
Setting up libxt-dev:amd64 (1:1.1.5-1) …
1-3. JAVA_HOME 설정
> 현재 java -version으로 버전 확인 시 설치한 자바로 설정되어 있지 않기 때문에 아래와 같이 변경이 필요하다.
root@master:/home/src# java -version
openjdk version “1.8.0_292”
OpenJDK Runtime Environment (build 1.8.0_292-8u292-b10-0ubuntu1~20.04-b10)
OpenJDK 64-Bit Server VM (build 25.292-b10, mixed mode)
1-4. 소스 Build
> 이제 소스와 컴파일 할 JDK와 maven도 준비되었기 때문에 Compile을 해보도록 하자
소스 경로에 들어가 압축을 풀고 아래와 같이 빌드를 진행해준다.
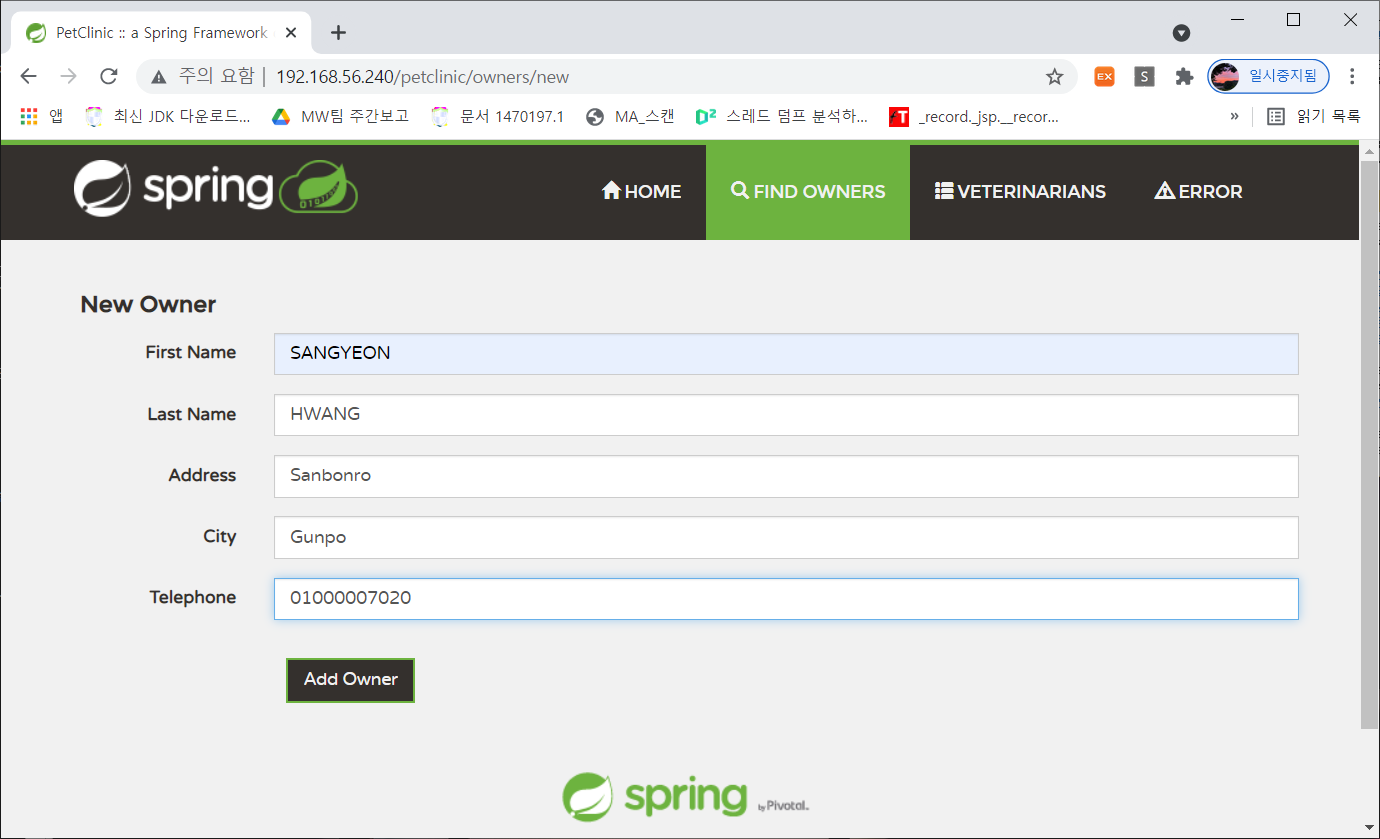
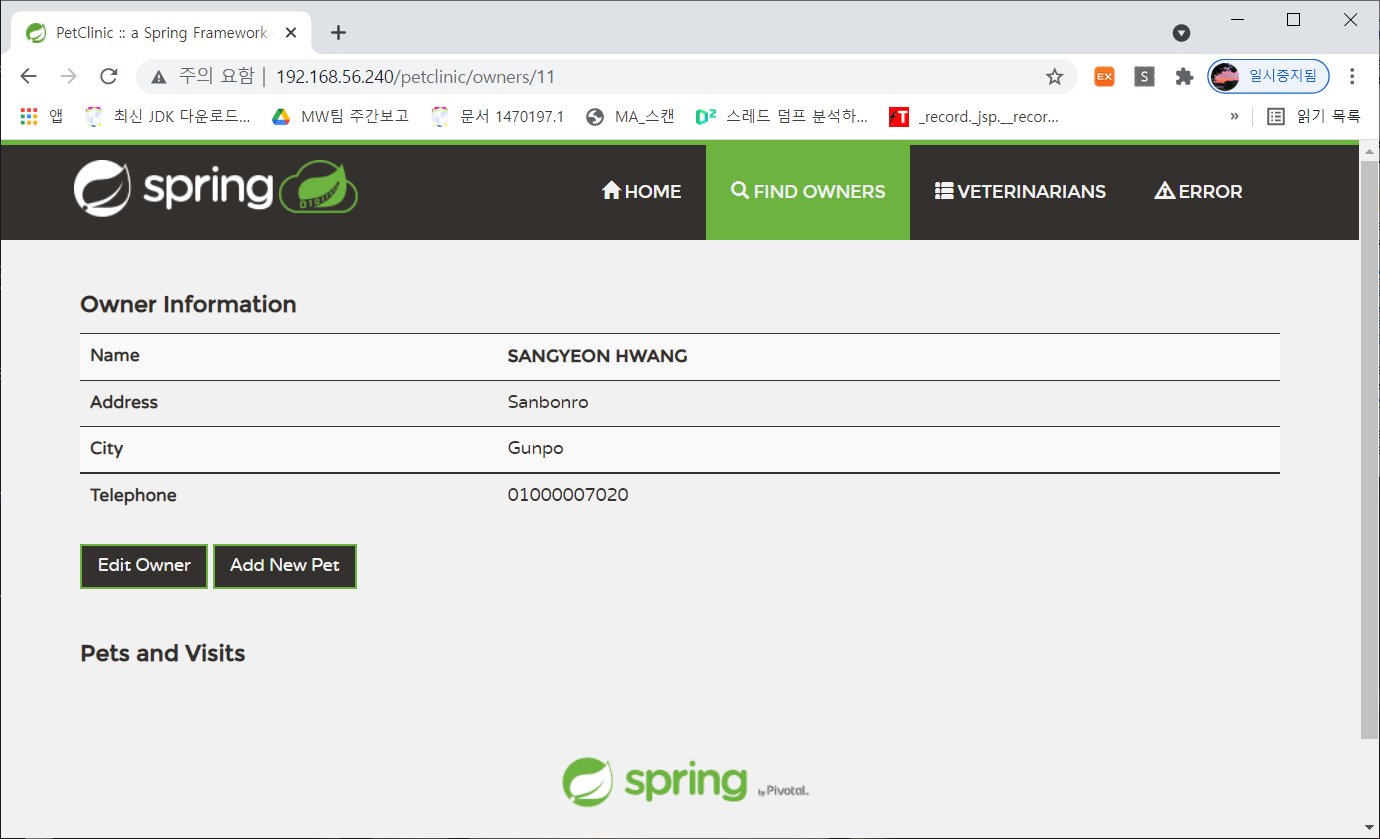
빌드 전에 잠시 소스 수정이 필요하다. pom.xml에 mysql 연동 부분에 localhost:3306을 mysql-petclinic:3306으로 수정하자. was와 db가 다른 컨테이너로 기동되기 때문에 localhost를 인식할 수 없다. 그러나 mysql-petclinic은 컨테이너 명으로 link가 걸려 통신이 가능하다..
root@master:/home/src/spring-framework-for-petclinic/spring-framework-for-petclinic# mvn clean package -Dmaven.test.skip=true -P MySQL
…(중략)
[INFO] ————————————————————————
[INFO] BUILD SUCCESS
[INFO] ————————————————————————
[INFO] Total time: 16.802 s
[INFO] Finished at: 2021-11-07T13:54:37+09:00
[INFO] ————————————————————————
========================================================================= 빌드를 하고 나면, 소스 경로 하위의 target 디렉토리에 petclinic.war 소스 파일이 생성된다.
root@master:/home/src/spring-framework-for-petclinic/spring-framework-for-petclinic/target# ls -arlt|grep petclinic.war
-rw-r–r– 1 root root 41605349 11월 7 13:54 petclinic.war
1-5. WAS 이미지 생성
> 이제 만든 소스를 활용하여 tomcat 이미지를 만들어보도록 하자.
우선 이미지 생성을 위해 Dockerfile을 생성하고 이전에 만들었던 petclinic.war 파일을 같은 디렉토리에 위치시킨다.
root@master:/home/dockerfile/petclinic# pwd
/home/dockerfile/petclinic
root@master:/home/dockerfile/petclinic# ls -arlt
total 40644
drwxr-xr-x 5 root root 4096 11월 7 14:06 ..
-rw-r–r– 1 root root 41605349 11월 7 14:06 petclinic.war
-rw-r–r– 1 root root 64 11월 7 14:06 Dockerfile
drwxr-xr-x 2 root root 4096 11월 7 14:06 .
하기는 Dockerfile 내용이다.
root@master:/home/dockerfile/petclinic# cat Dockerfile
From tomcat:8-jre8
ADD petclinic.war /usr/local/tomcat/webapps/
> tomcat 컨테이너에서 mysql 컨테이너의 ip로 접속할 수 있겠지만, static ip가 아니기 때문에 mysql 컨테이너의 이름으로 접속을 해야 할 필요가 있다. 이럴 경우 link 옵션을 통해 컨테이너를 구동하면 tomcat 컨테이너에서 mysql 컨테이너로 이름으로 접속할 수 있다. link 옵션으로 구동하면 톰캣 컨테이너 안의 /etc/hosts에 링크된 mysql 컨테이너 hostname과 ip가 들어간다.