1. Stop firewalld service and Time synchronization
# firewalld 서비스 중지
sudo systemctl stop firewalld
# firewalld 서비스 자동 실행 중지
sudo systemctl disable firewalld
# 표준 시간대 설정 (서울)
sudo timedatectl set-timezone Asia/Seoul
# chrony 설치 및 NTP 동기화 활성화
sudo dnf install -y chrony
sudo systemctl enable --now chronyd
# 동기화 상태 확인
chronyc tracking
chronyc sources -v
2. swap 기능 비활성화
# swap 끄기
sudo swapoff -a
# swap 자동 마운트 끄기
sudo vi /etc/fstab
# /swap 라인 주석 처리
3. containerd(docker) 설치
# 패키지 업데이트
sudo yum update -y
# 필수 패키지 설치
sudo yum install -y yum-utils iproute-tc
# docker 저장소 추가
sudo yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
# containerd 설치
sudo yum install containerd.io.x86_64 -y
# containerd 자동 시작하도록 설정
sudo systemctl enable --now containerd
# containerd 설정 파일 생성
sudo bash -c "containerd config default > /etc/containerd/config.toml"
# Cgroup을 Systemd를 통해 관리하도록 설정
sudo sed -i 's/ SystemdCgroup = false/ SystemdCgroup = true/' /etc/containerd/config.toml
# SELinux 를 permissive mode로 변경
# 즉시 변경 (재부팅시 적용 X)
sudo setenforce 0
# 설정 파일 수정 (재부팅 후 적용)
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# kubelet kubeadm kubectl 설치
sudo yum install kubelet kubeadm kubectl --disableexcludes=kubernetes -y
# kubelet 자동 시작하도록 설정
sudo systemctl enable --now kubelet
# net.ipv4.ip_forward=1 로 설정
echo "net.ipv4.ip_forward=1" | sudo tee -a /etc/sysctl.conf
# bridge 모듈 로드
sudo modprobe br_netfilter
# net.bridge.bridge-nf-call-iptables = 1 로 설정
echo "net.bridge.bridge-nf-call-iptables = 1" | sudo tee -a /etc/sysctl.conf
# 변경 사항 적용
sudo sysctl -p
sudo kubeadm init --pod-network-cidr=10.10.0.0/16 --apiserver-advertise-address 192.168.1.71
[조금 기다리다 보면 ....]
[앞부분 생략]
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.1.71:6443 --token fx8wwi.h1sg517qd62hft7e \
--discovery-token-ca-cert-hash sha256:62133cfdf41b98d1f45d0a42a9f72af146b632c50c0bda7044461f7e41c1cc1c
# 인증 정보 복사 (위에서 제시한 가이드)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# calico 설치 (network cni 플러그인 중 하나)
kubectl apply -f https://raw.githubusercontent.com/projectcalico/calico/master/manifests/tigera-operator.yaml
# custom-resources.yaml 파일은 수정이 필요해서 다운로드 먼저
curl -O https://raw.githubusercontent.com/projectcalico/calico/master/manifests/custom-resources.yaml
# custom-resoures.yaml 편집
vi custom-resources.yaml #cidr 정보를 변경 (-> 10.10.0.0/16)
# 설치
kubectl apply -f custom-resources.yaml
# /etc/resolve.conf 소프트 링크 (혹은 copy) (master node)
# 쿠버네티스 dns 질의 시 /run/systemd/resolve/resolv.conf 파일을 참조 함
sudo mkdir -p /run/systemd/resolve
sudo ln -s /etc/resolv.conf /run/systemd/resolve/resolv.conf
# 설치 확인하기
kubectl get pods -A
[STATUS : All Pending --> All Running]
추후 worker를 추가할 경우 유효기간 경과(24시간)로 인해 token 발행 및 해쉬값 확인이 필요함. worker 바로 연결 시에는 아래 단계 생략 하고 “5. kubeadm init (master node) 단계”에서 복사해둔 kubeadm join 문 사용.
# master node의 config 파일 복사 (worker node)
mkdir -p $HOME/.kube
scp totoli@192.168.1.71:/home/totoli/.kube/config /home/totoli/.kube
sudo chown $(id -u):$(id -g) $HOME/.kube/config
7. hosts 편집 (all node)
# hostname추가
hostnamectl set-hostname k8s-master
# /etc/hosts 추가
sudo echo "192.168.1.71 k8s-master" >> /etc/hosts
sudo echo "192.168.1.72 k8s-worker1" >> /etc/hosts
sudo echo "192.168.1.73 k8s-worker2" >> /etc/hosts
sudo echo "192.168.1.74 k8s-worker3" >> /etc/hosts
127.0.1.1 k8s-worker3 <----- 필요 시 sudo vi /etc/hosts
# master & workers node 연결 확인
kubectl get nodes
8. Matal LoadBalancer 설치
# MetalLB Manifest 적용
kubectl apply -f https://raw.githubusercontent.com/metallb/metallb/v0.14.8/config/manifests/metallb-native.yaml
#MetalLB Pod 확인
kubectl -n metallb-system get pods
#모두 Running 상태면 OK.
# IPAddressPool & L2Advertisement 설정
# 예시: 192.168.1.240 ~ 192.168.1.250 구간을 외부 IP 대역으로 사용
cat <<EOF | kubectl apply -f -
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: default-pool
namespace: metallb-system
spec:
addresses:
- 192.168.1.240-192.168.1.250
---
apiVersion: metallb.io/v1beta1
kind: L2Advertisement
metadata:
name: default-adv
namespace: metallb-system
spec:
ipAddressPools:
- default-pool
EOF
# 정상 설치 확인
kubectl -n metallb-system get ipaddresspool,l2advertisement
kubectl -n metallb-system get pods
9. Portainer Environments 연결
# Portainer 이름영역 생성
kubectl create namespace portainer
#Portainer agent 설치 (portainer-agent-k8s-lb manifest 적용)
kubectl apply -n portainer -f https://downloads.portainer.io/ce2-33/portainer-agent-k8s-lb.yaml
#위 YAML은 자동으로 LoadBalancer 서비스를 생성하므로 MetalLB가 설치되어 있다면 자동으로 IP를 할당받음.
# 서비스 확인
kubectl -n portainer get svc
kubectl -n portainer get pods -o wide
# Portainer UI에서 Agent 연결
> 좌측 메뉴 → Environments → Add Environment
> Kubernetes Agent 선택
> 주소 입력: 192.168.1.240:9001
# 최신 버전의 Ingress-NGINX 컨트롤러 설치
kubectl apply -f \
https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/static/provider/cloud/deploy.yaml
# Ingress-NGINX 컨트롤러 Pod 상태 확인
kubectl -n ingress-nginx get pods -o wide
# Ingress-NGINX LoadBalancer 서비스 정보 확인 → EXTERNAL-IP 가 MetalLB IP로 설정되는지 확인
kubectl -n ingress-nginx get svc ingress-nginx-controller
# ingress 컨트롤러 확인 을 위한 App. Pod 생성 (Echo-server)
# 테스트용 네임스페이스 생성 (sandbox)
kubectl create ns sandbox
# echo-server 배포 (테스트용 HTTP 서버)
kubectl -n sandbox create deploy echo-server --image=ealen/echo-server
# echo-server를 ClusterIP 서비스로 노출
kubectl -n sandbox expose deploy echo-server --port 80
# echo-server 로 트래픽을 보내는 Ingress 생성
# - ingressClassName: nginx ← 중요 (Ingress-NGINX 사용)
# - path: / ← 모든 요청을 echo-server 서비스로 전달
cat <<'EOF' | kubectl apply -f -
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: echo-ingress
namespace: sandbox
spec:
ingressClassName: nginx
rules:
- http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: echo-server
port:
number: 80
EOF
# 롤아웃 완료 확인
kubectl -n kube-system rollout status deploy/metrics-server
#deployment "metrics-server" successfully rolled out 결과나오면 OK
# 배포 상태 확인
kubectl -n kube-system get pods -l k8s-app=metrics-server
# API 서비스 등록 확인
kubectl get apiservices | grep metrics
# v1beta1.metrics.k8s.io 가 True 상태여야 함.
kubectl top nodes
# cpu 사용률과 memory 사용률 표출여부 확인하면 완료
2024년 3월 초, docker가 익숙해서 끝까지 버티고 있던 kubernetes v1.23.x 개발 환경 설치에 돌연 문제가 생겼다. Ubuntu에서 kubeadm, kubelet, kubectl 등을 apt로 설치할 수 없게 된 것이다. 원인과 해결 방법에 대해 알아보자.
Kubernetes apt install 에러 현상과 원인
K8s 설치 시 어떤 현상이 발생하는가?
2024년 3월 초부터 ubuntu에 apt install 명령어를 통해 kubeadm, kubelet, kubectl이 설치되지 않는다. 기존 사용하던 개발 환경은 다음과 같다.
위 명령어를 통해 kubernetes 설치를 진행하면, 다음과 같은 에러 메시지를 확인할 수 있다.
master: deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] https://apt.kubernetes.io/ kubernetes-xenial main
master: Hit:1 https://download.docker.com/linux/ubuntu jammy InRelease
master: Hit:3 http://ports.ubuntu.com/ubuntu-ports jammy InRelease
master: Ign:2 https://packages.cloud.google.com/apt kubernetes-xenial InRelease
master: Hit:4 http://ports.ubuntu.com/ubuntu-ports jammy-updates InRelease
master: Err:5 https://packages.cloud.google.com/apt kubernetes-xenial Release
master: 404 Not Found [IP: 142.250.76.142 443]
master: Hit:6 http://ports.ubuntu.com/ubuntu-ports jammy-backports InRelease
master: Get:7 http://ports.ubuntu.com/ubuntu-ports jammy-security InRelease [110 kB]
master: Reading package lists...
master: E: The repository 'https://apt.kubernetes.io kubernetes-xenial Release' does not have a Release file.
master:
master: WARNING: apt does not have a stable CLI interface. Use with caution in scripts.
master:
master: Reading package lists...
master: Building dependency tree...
master: Reading state information...
master: E: Unable to locate package kubelet
master: E: Unable to locate package kubectl
master: E: Unable to locate package kubeadm
원인은 package repository에 있다!
위의 에러 메시지를 살펴보면, kubernetes 관련 package 목록을 가져오기 위해 package repository에 접속을 하는데, 404 에러가 발생하고 있음을 알 수 있다. 최근까지 잘 되던 것이 갑자기 되지 않으니까 당황스럽다. 원인은 외부에 있음을 직감하고, kubernetes 공식 문서들을 샅샅이 뒤져보았다.
아니나 다를까, package repository가 대체된다는 안내사항이 있었다. 해당 글에서는 다음과 같이 안내하고 있다.
On behalf of Kubernetes SIG Release, I am very excited to introduce the Kubernetes community-owned software repositories for Debian and RPM packages: pkgs.k8s.io! The new package repositories are replacement for the Google-hosted package repositories (apt.kubernetes.io and yum.kubernetes.io) that we’ve been using since Kubernetes v1.5.
ℹ️ Update (January 12, 2024): the legacy Google-hosted repositories are going away in January 2024. Check out the deprecation announcement for more details about this change.
기존 사용하던 package repository가 2024년 1월부터 아예 사라질 것이라고 되어 있는데, 3월까지 잘 사용한 것도 기적이었던 것이다. 평소 부지런하게 follow up하지 않았던 스스로를 반성하게 된다.
Package repository 관련 문제 해결 방법
Package repository deprecation에 대응하기
안내사항에 따르면, 다음과 같이 package repository를 변경한 후 apt install을 진행하면 된다.
master: Reading package lists...
master: E: Failed to fetch https://pkgs.k8s.io/core:/stable:/v1.23/deb/InRelease 403 Forbidden [IP: 54.192.175.103 443]
master: E: The repository 'https://pkgs.k8s.io/core:/stable:/v1.23/deb InRelease' is not signed.
한 걸음 나아가긴 했다. 404 Not Found 에러 대신 403 Forbidden 에러가 발생하는 것으로 보아, 적어도 새로운 package repository는 서비스를 하고 있긴 하다는 것을 확인할 수 있다. 그렇다면, 왜 이런 현상이 발생하는 것일까? 이 문제에 대한 원인도 앞서 언급한 안내 글에서 찾을 수 있었다.
The new Kubernetes package repositories contain packages beginning with those Kubernetes versions that were still under support when the community took over the package builds. This means that the new package repositories have Linux packages for all Kubernetes releases starting with v1.24.0.
새로운 package repository는 v1.24.0 이상의 kubernetes만 제공한다는 것이다. 결국, kubernetes의 버전을 올려야 한다.
Docker를 버린 kubernetes v1.24로의 여정
Kubernetes v1.23.x와 v1.24.x 사이에는 큰 차이점이 존재한다. Kubernetes v1.24.0부터는 docker를 버렸다는 것이다. 공식 문서의 내용을 간단히 요약하면 다음과 같다.
1.24 버전 이전에는 docker라는 specific한 CRI를 사용하고 있었다.
Kubernetes에서 docker 외에도 다양한 CRI를 지원하기 위해, CRI standard라는 것을 만들었다.
Docker는 CRI standard를 따르지 않고 있다.
Kubernetes는 docker 지원을 위해 dockershim이라는 코드를 만들어서 제공했다.
Kubernetes 개발 참여자들이 docker라는 특수 CRI를 위해 별도로 시간을 할애하는 것이 부담스럽다.
Kubernetes v1.24부터 dockershim 지원 안하기로 했다.
실제로, kubernetes v1.24 버전을 설치할 때 docker를 사용하려고 하면, 다음과 같은 에러를 만날 수 있다.
master: [WARNING SystemVerification]: missing optional cgroups: blkio
master: error execution phase preflight: [preflight] Some fatal errors occurred:
master: [ERROR CRI]: container runtime is not running: output: time="2024-03-05T00:42:52-08:00" level=fatal msg="validate service connection: CRI v1 runtime API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.RuntimeService"
master: , error: exit status 1
master: [preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`
master: To see the stack trace of this error execute with --v=5 or higher
master: failed to load admin kubeconfig: open /root/.kube/config: no such file or directory
master: To see the stack trace of this error execute with --v=5 or higher
눈물과 함께 kubernetes v1.23과 docker와 작별할 시간이다. 앞서 살펴본 package repository 설정 부분에서 버전을 지정해주는 문자열을 변경하자.
이후 apt-cache policy kubeadm 명령어를 통해 설치 가능한 버전을 조회해보고 apt install을 통해 설치를 진행하면 된다. 이때 주의할 점은, docker가 아니라 containerd를 사용할 것이기 때문에 설치하려는 kubernetes 버전과 호환되는 containerd 버전을 알아보고 미리 설치해두어야 한다는 것이다. Containerd와 kubernetes 버전 호환 관계는 이 문서를 확인하면 된다.
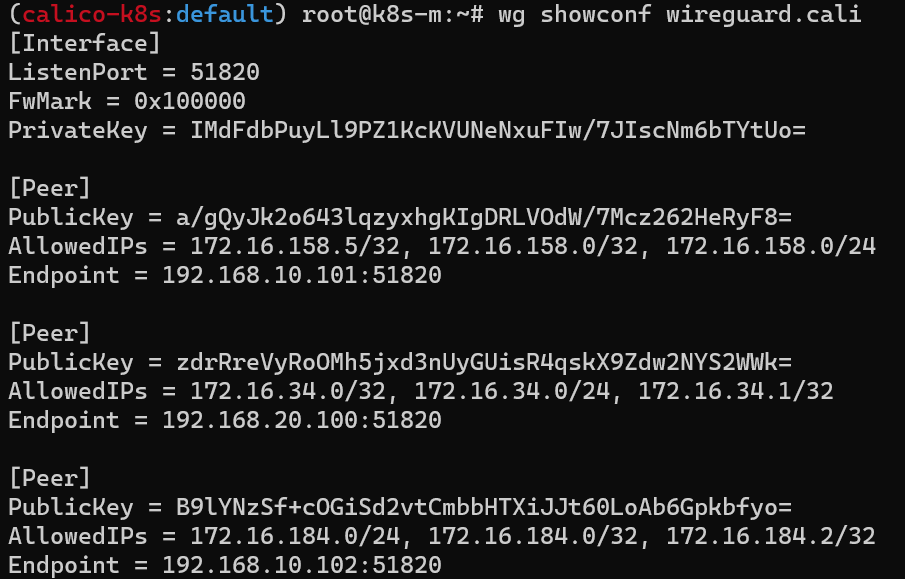
BGP(Border Gateway Protocol): AS 사이에서 이용되는 라우팅 프로토콜. 대규모 네트워크(수천만의 경로 수)에 대응하도록 설계됐다. 그래서 BGP로 동작하는 라우터는 비교적 고가인 제품이 많다.
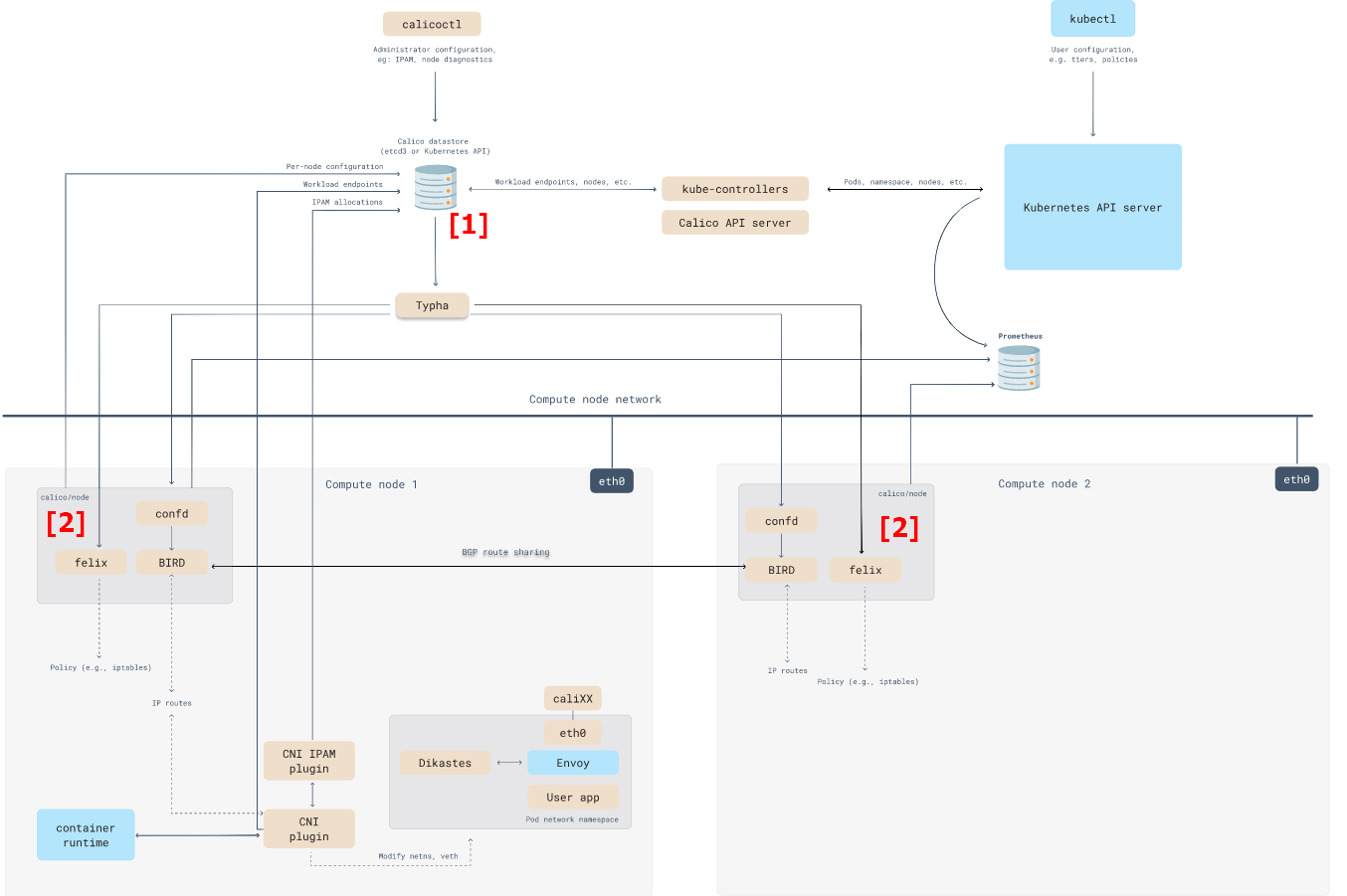
AS(Autonomous System): 하나의 정책을 바탕으로 관리되는 네트워크(자율 시스템)를 말한다. ISP, 엔터프라이즈 기업, 공공기관 같은 조직이 이에 해당하며 인터넷은 이러한 자율 시스템의 집합체이다.여러가지 구성 요소가 많지만, 일단 눈여겨 볼 내용은 Calico가 사용하는 Datastore[1]와 마스터 노드를 포함한 모든 노드들에 존재하는 Calico Pods[2]
Felix (필릭스) : 인터페이스 관리, 라우팅 정보 관리, ACL 관리, 상태 체크
BIRD (버드): BGP Peer 에 라우팅 정보 전파 및 수신, BGP RR(Route Reflector)
Confd : calico global 설정과 BGP 설정 변경 시(트리거) BIRD 에 적용해줌
Datastore plugin : calico 설정 정보를 저장하는 곳 – k8s API datastore(kdd) 혹은 etcd 중 선택
Calico IPAM plugin : 클러스터 내에서 파드에 할당할 IP 대역
calico-kube-controllers : calico 동작 관련 감시(watch)
calicoctl : calico 오브젝트를 CRUD 할 수 있다, 즉 datastore 접근 가능
구성 요소 확인하기
데몬셋으로 각 노드에 calico-node 파드가 동작하여, 해당 파드에 bird, felix, confd 등이 동작 + Calico 컨트롤러 파드는 디플로이먼트로 생성
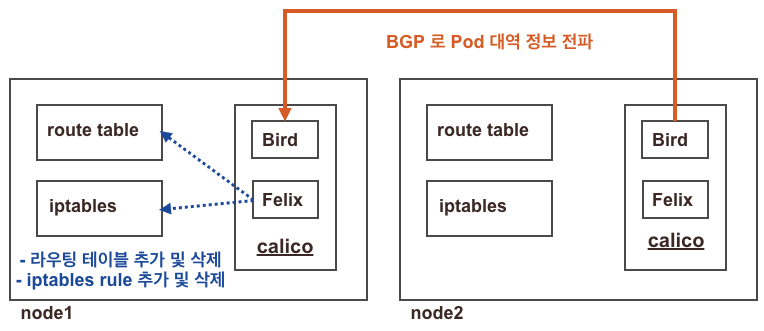
Calico의 특징은 BGP를 이용해 각 노드에 할당된 Pod 대역의 정보를 전달한다. 즉, 쿠버네티스 서버뿐만 아니라 물리적인 라우터와도 연동이 가능 하다는 뜻이다. (Flannel의 경우 해당 구성 불가)
Calico Pod 안에서 Bird라고 하는 오픈소스 라우팅 데몬 프로그램이 프로세스로 동작하여 각 Node의 Pod 정보가 전파되는 것이다.
이후 Felix라는 컴포넌트가 리눅스 라우터의 라우팅 테이블 및 iptables rule에 전달 받은 정보를 주입하는 형태이다.
confd는 변경되는 값을 계속 반영할 수 있도록 트리거 하는 역할이다.
Calico 기본 통신 과정 확인하기
calicoctl 설치
리소스 관리를 위해 Calico CLI를 설치 및 구성
마스터 노드 확인
Calico CNI 설치시, 데몬셋이므로 모든 노드에 칼리코 파드가 하나씩 존재하게 된다. (calico-node-*)
칼리코 컨트롤러가 하나 존재하는 것을 확인할 수 있다.
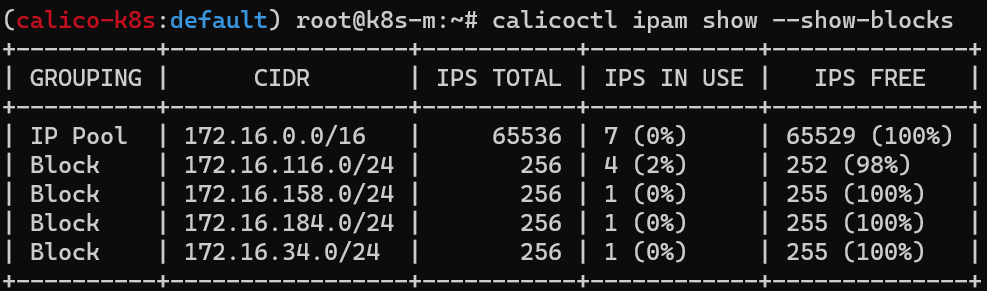
calicoctl ipm show 명령어를 통해, IAPM 정보를 확인할 수 있다. 아래 스크린샷에서는 172.16.0.0/16 대역을 해당 쿠버네티스 클러스터에서 사용할 수 있다는 내용을 알 수 있다.
IPAM(IP Address Management): 풍부한 사용자 환경을 통해 IP 주소 인프라의 엔드 투 엔드 계획, 배포, 관리 및 모니터링을 지원하는 통합 도구 모음이다.
IPAM은 네트워크상의 IP 주소 인프라 서버 및 DNS(도메인 이름 시스템) 서버를 자동으로 검색하여 중앙 인터페이스에서 이들 서버를 관리할 수 있다.
옵션을 통해 아래와 같이 특정한 노드에 할당 가능한 대역대를 확인할 수도 있음(Block는 각 노드에 할당된 Pod CIDR 정보를 나타냄)
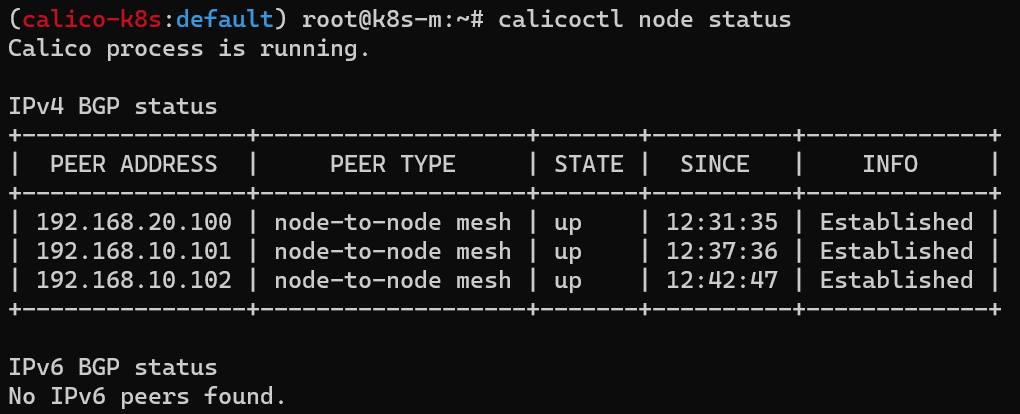
calicoctl node 정보 확인
ippool 정보 확인
파드와 서비스 사용 네트워크 대역 정보 확인
실습 1.
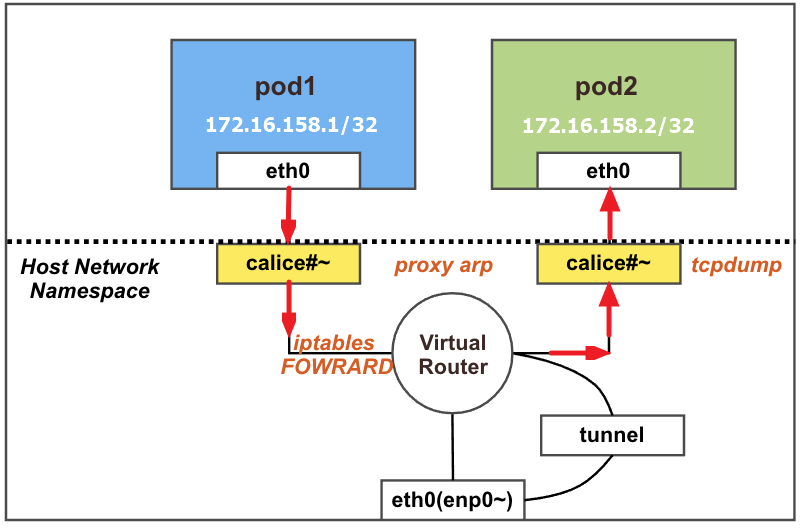
동일 노드 내 파드 간 통신
결론: 동일 노드 내의 파드 간 통신은 내부에서 직접 통신됨
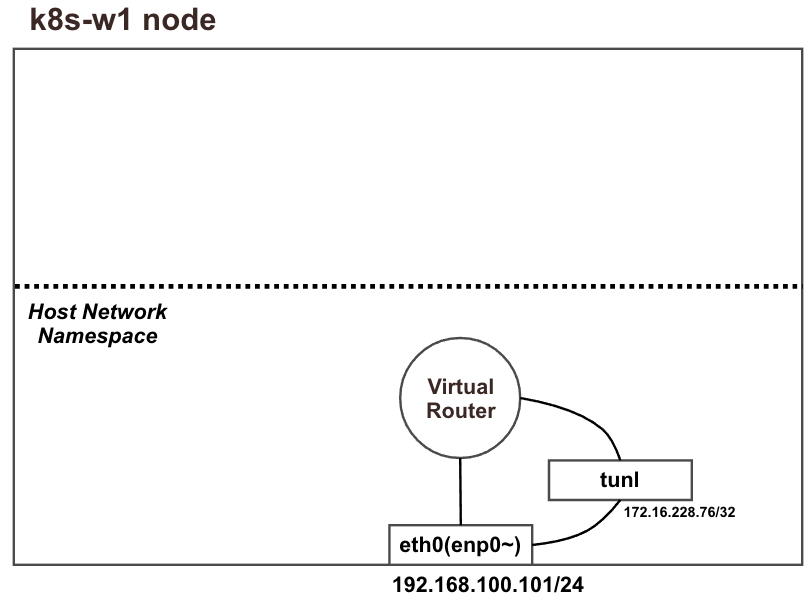
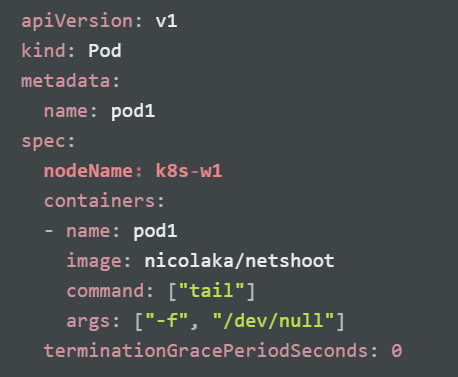
파드 생성 전 노드(k8s-w1)의 기본 상태
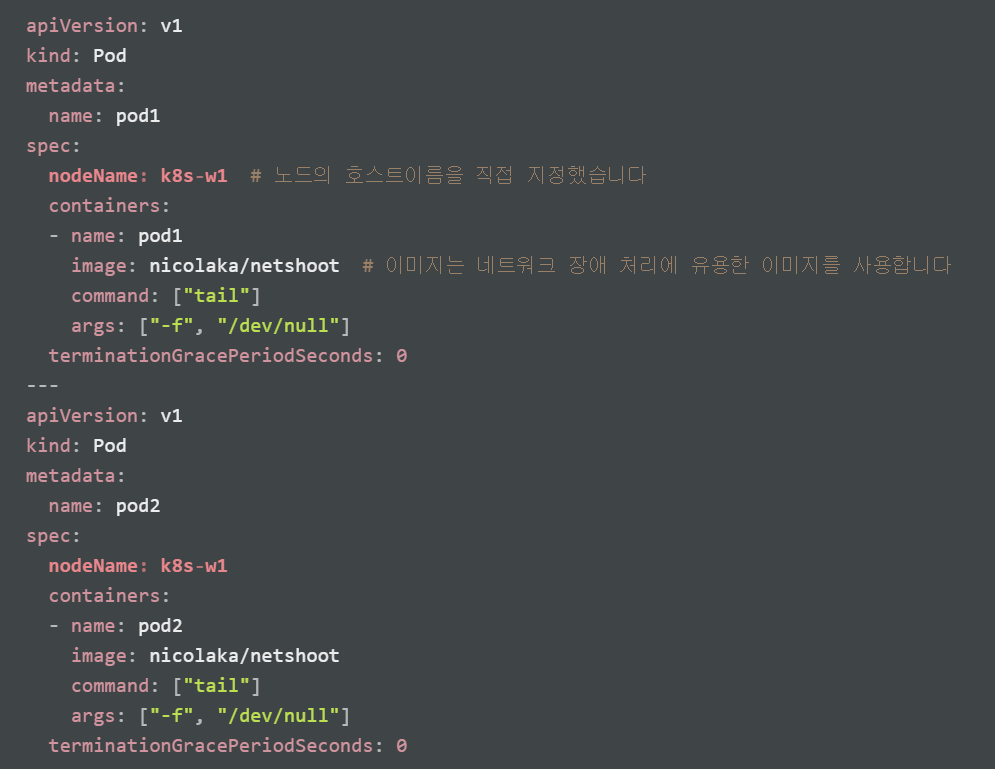
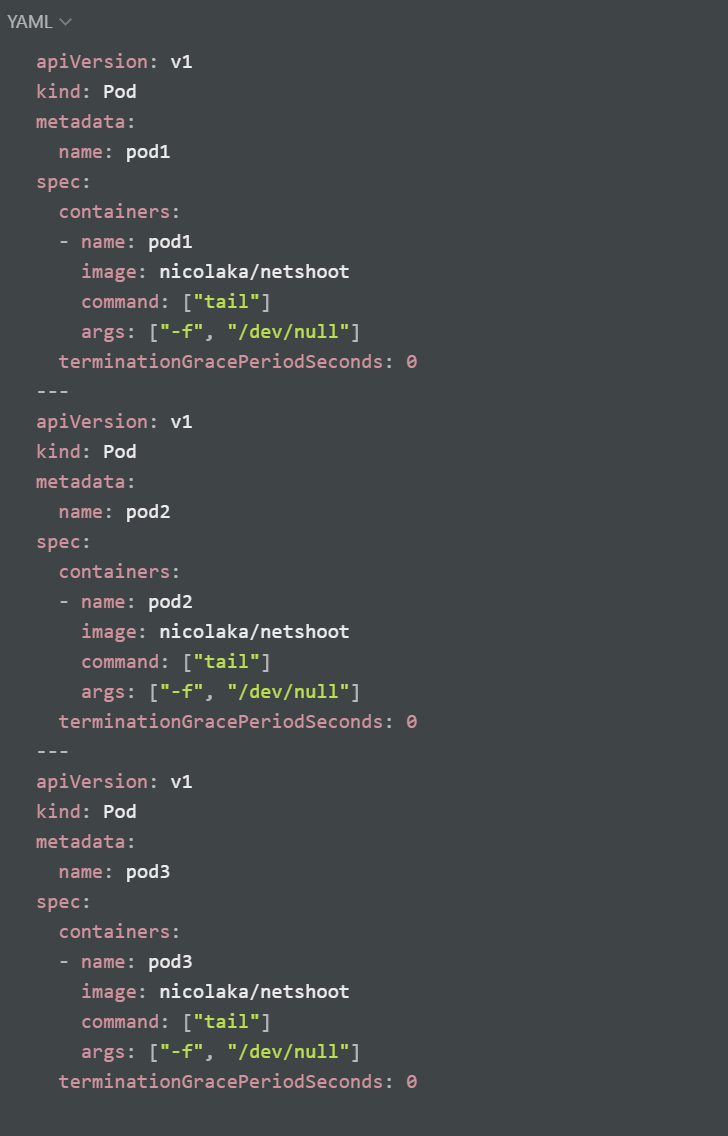
노드(k8s-w1)에 파드 2개 생성
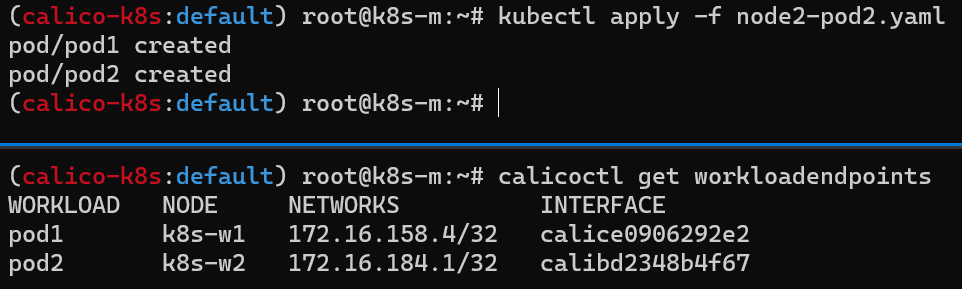
아래 내용으로 node1-pod2.yaml 파일 작성 후 파드 생성
파드 생성 전후의 변화를 관찰하기 위해 터미널 하단 추가 탭에watch calicoctl get workloadEndpoint 명령어를 사용하여 모니터링
calicoctl 명령어로 endpoint 확인: veth 정보도 확인할 수 있음
생성된 파드 정보 확인
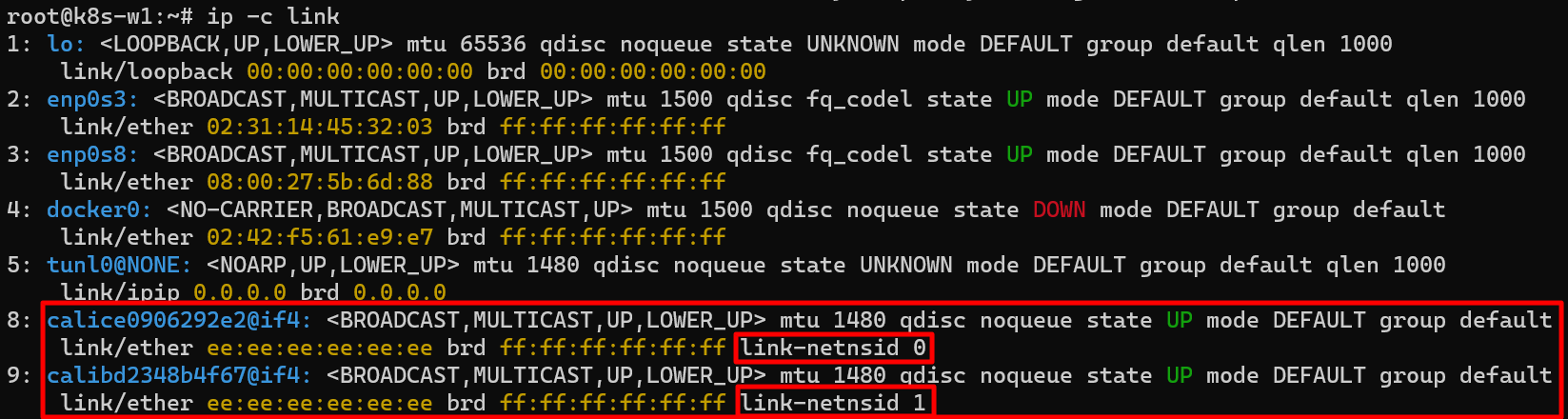
네트워크 인터페이스 정보 확인(k8s-w1)
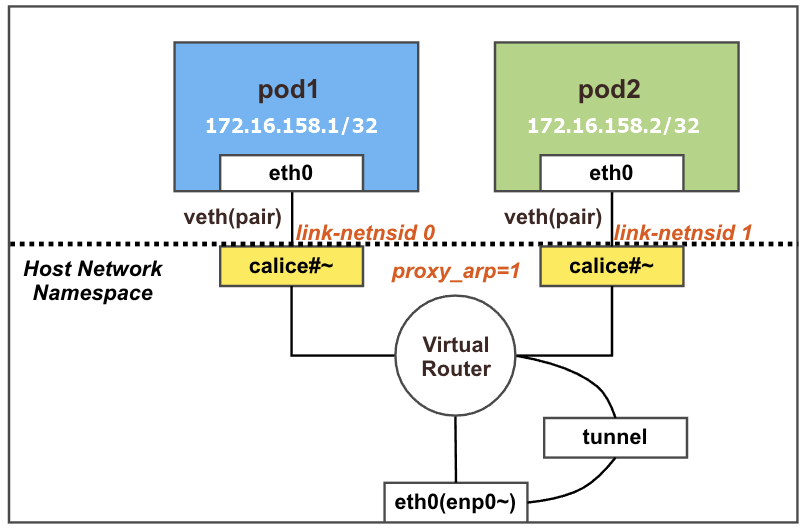
calice#~ 두개 추가된 것을 확인할 수 있음
각각 net ns 0,1로 호스트와 구별되는 것을 확인할 수 있음
네트워크 네임스페이스 확인
아래 2개 PAUSE 컨테이너가 각각 파드별로 생성된 것을 확인할 수 있음
바로 위 스크린샷인 link-netnsid 0, link-netnsid 1과 매칭됨
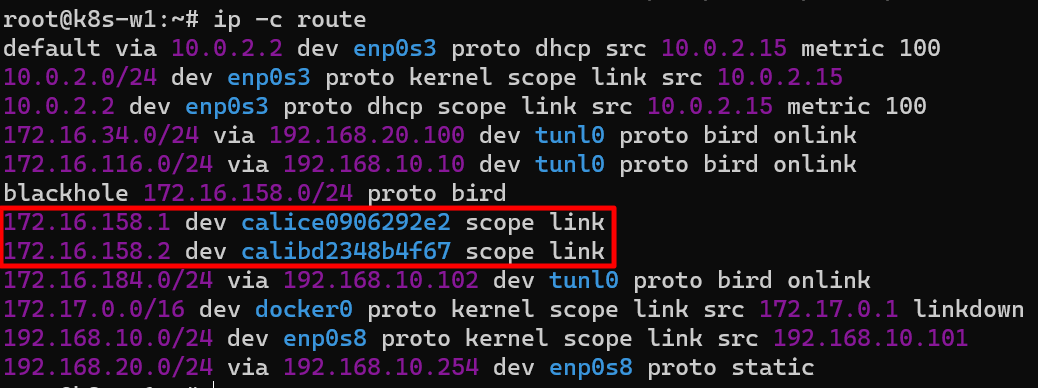
라우팅 테이블 확인
파드의 IP/32bit 호스트 라우팅 대역이 라우팅 테이블에 추가된 것을 확인할 수 있음
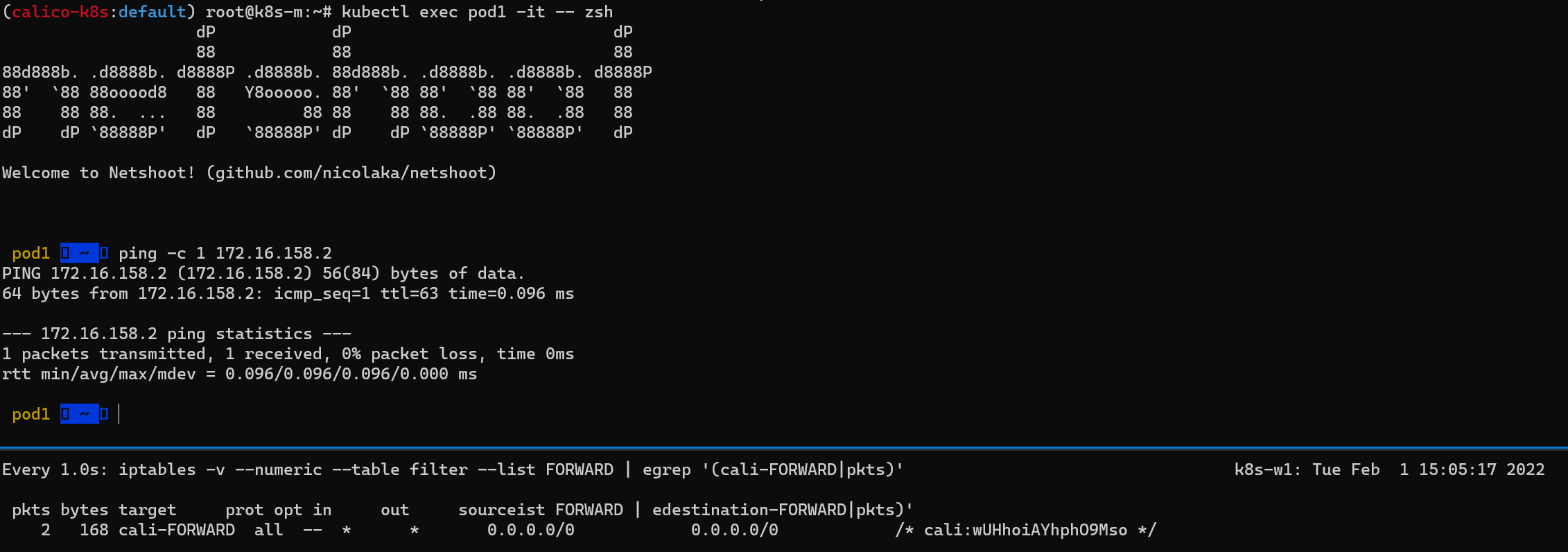
파드간 통신 실행 이해
(위) 마스터 노드에서 Pod1 Shell에 접근하여 Pod2로 Ping 테스트
(아래) 워커 노드(k8s-w1)에서 iptables 필터 테이블에 FORWARD 리스트 중 cali-FORWARD 룰 정보를 필터링해서 watch로 확인
테스트 결과 아래 이미지와 같이 Host iptables에서 FOWRARD라는 테이블의 허용 조건에 따라 정상적으로 통신이 가능한 것을 확인할 수 있다.
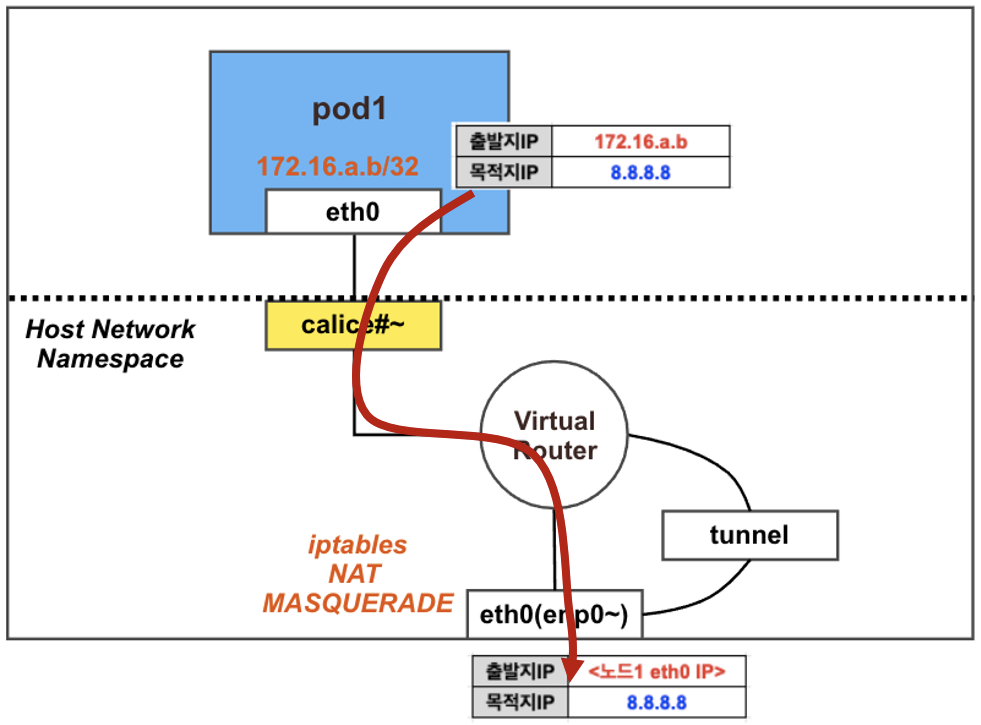
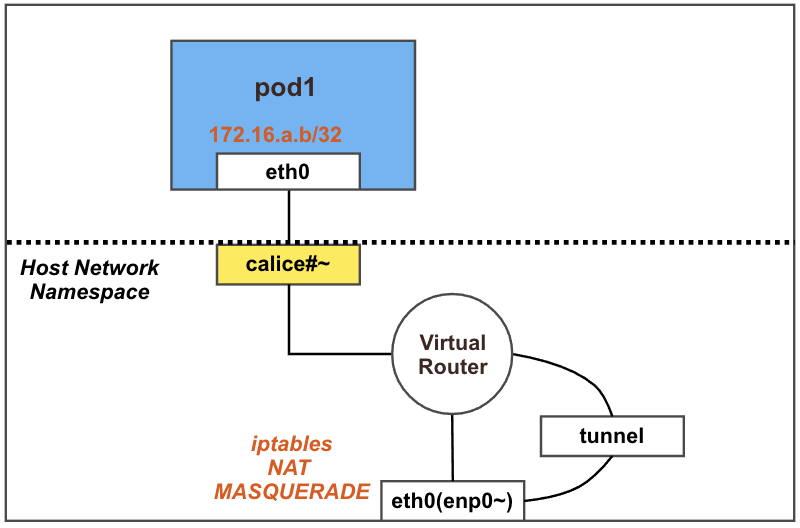
파드에서 외부(인터넷)로의 통신
결론: 파드에서 외부(인터넷) 통신 시에는 해당 노드의 네트워크 인터페이스 IP 주소로 MASQUERADE(출발지 IP가 변경) 되어서 외부에 연결됨
파드 배포 전 calico 설정 정보 확인 & 노드에 iptables 확인
마스터 노드에서 아래 내용 확인: natOutgoing의 기본값이 true로 설정되어 있는 것을 확인 할 수 있다. 즉 이 노드에서 외부로 통신할 때 NAT의 MASQUERADE를 사용하겠다는 의미이다.
NAT – MASQUERADE : 조건에 일치하는 패킷의 출발지 주소를 변환하는 것. 내부에서 전달되는 요청의 출발지 주소를 조건에 지정된 인터페이스의 IP로 변환한다.
워커 노드(k8s-w1)에서도 외부로 통신시 MASQUERADE 동작 Rule이 존재하는 것을 확인할 수 있다.
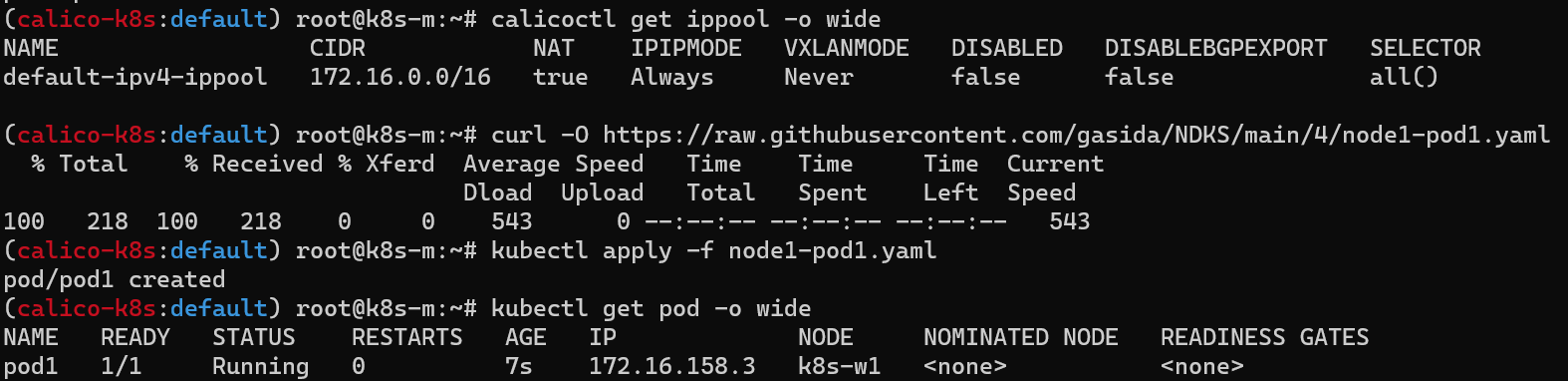
마스터 노드에서 워커 노드(k8s-w1)에 아래 내용의 파드 1개 생성
외부 통신 가능 여부 확인
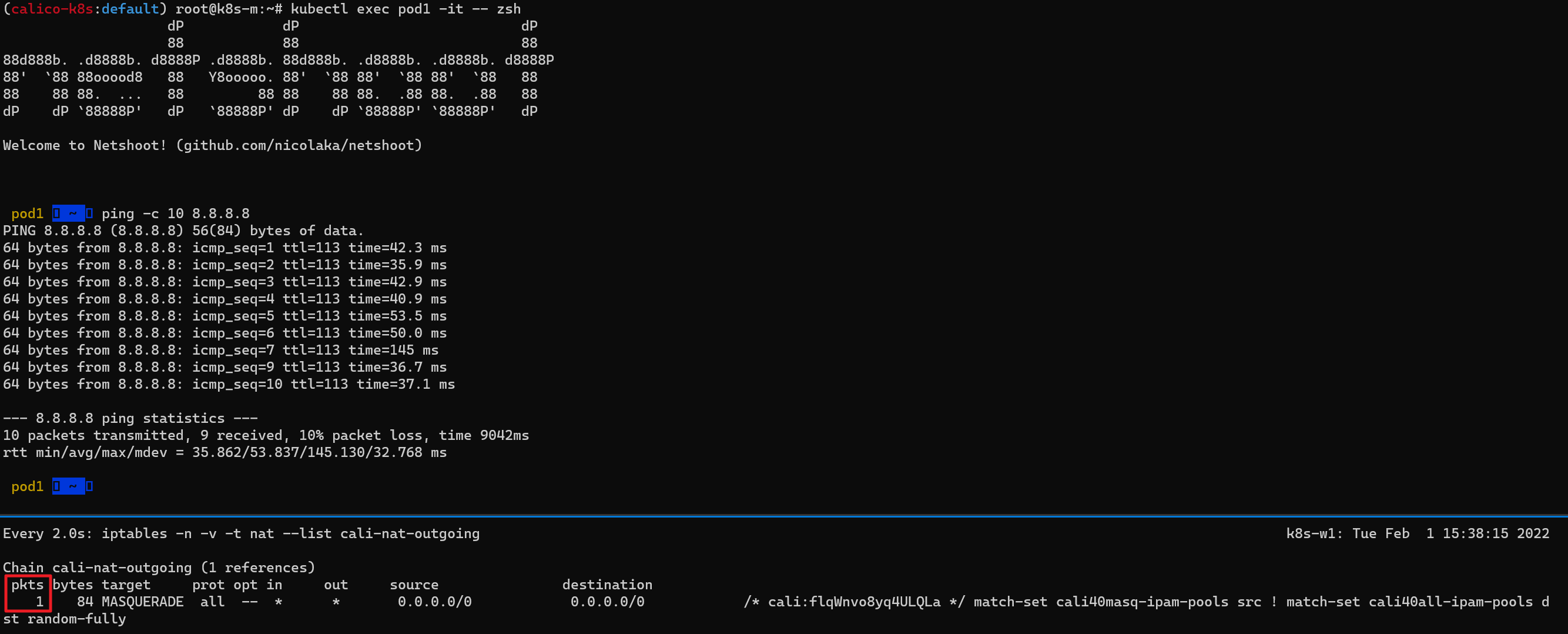
통신 전, 워커 노드(k8s-w1)에 iptables NAT MASQUERADE 모니터링을 활성화 하면 외부 통신시 pkts값이 증가하는지 확인할 수 있다.
(위) 마스터 노드에서 Pod1 Shell 실행 후, 8.8.8.8로의 통신 성공
(아래) pkts 값이 이전 이미지와 다르게 증가한 것을 확인할 수 있다.
다른 노드에서 파드 간 통신
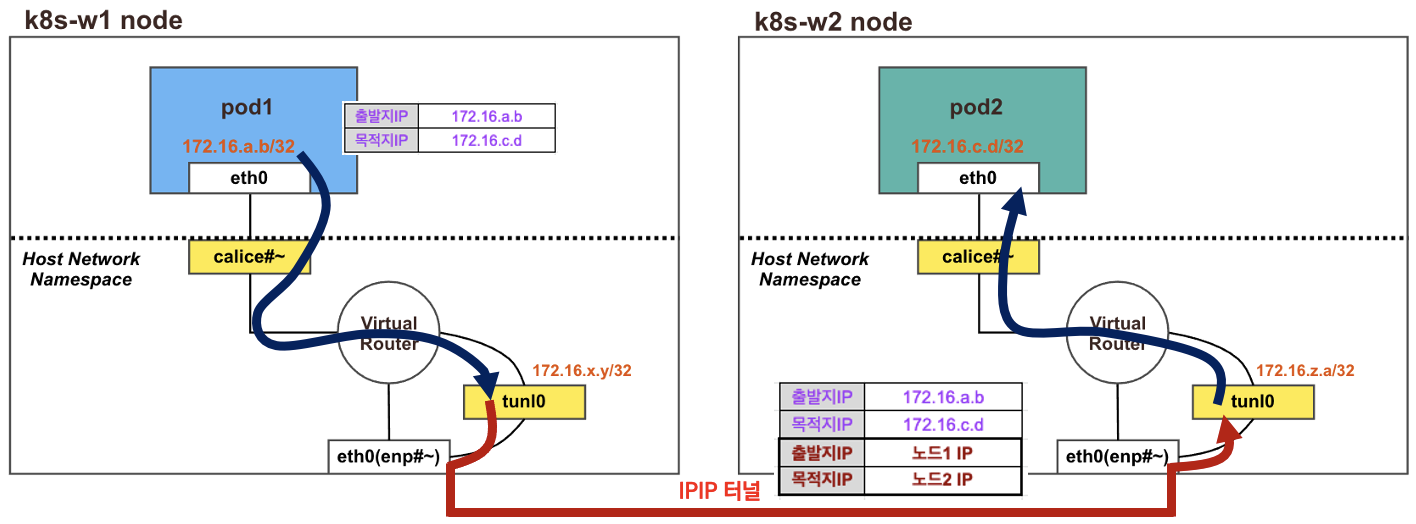
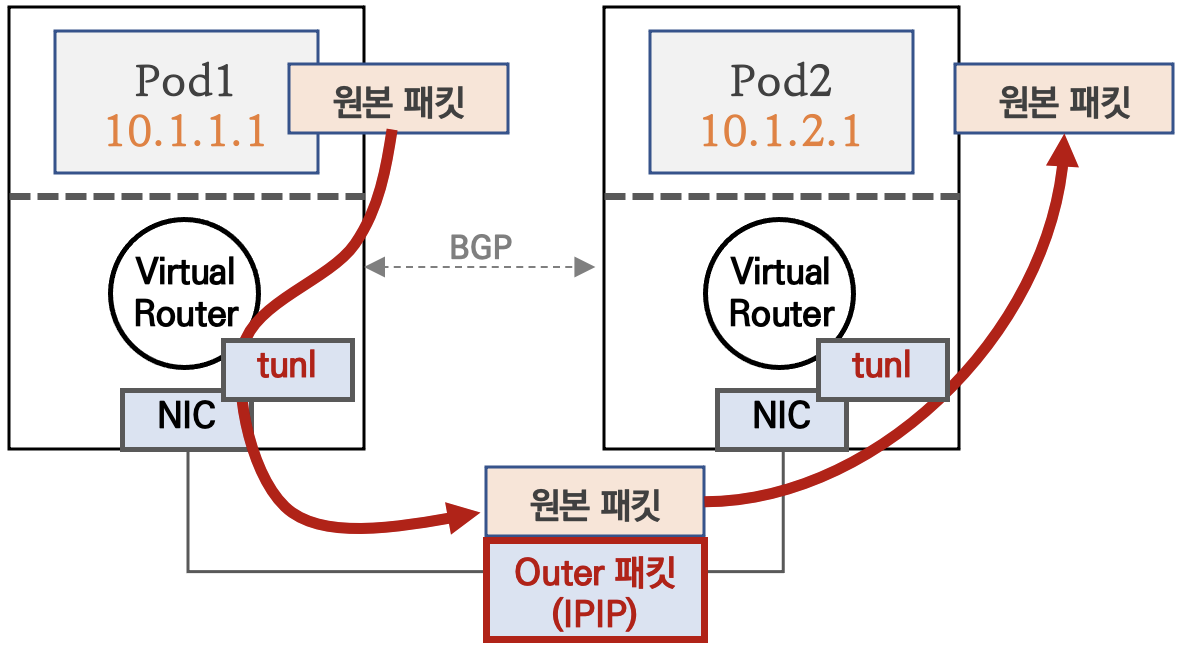
결론: 다른 노드 환경에서 파드 간 통신시에는 IPIP터널(기본값) 모드를 통해서 이루어진다.
각 노드에 파드 네트워크 대역은 Bird에 의해서 BGP로 광고 전파/전달 되며, Felix에 의해서 호스트의 라우팅 테이블에 자동으로 추가/삭제 된다.
다른 노드 간의 파드 통신은 tunl0 인터페이스를 통해 IP 헤더에 감싸져서 상대측 노드로 도달 후 tunl0 인터페이스에서 Outer 헤더를 제거하고 내부 파드와 통신한다.
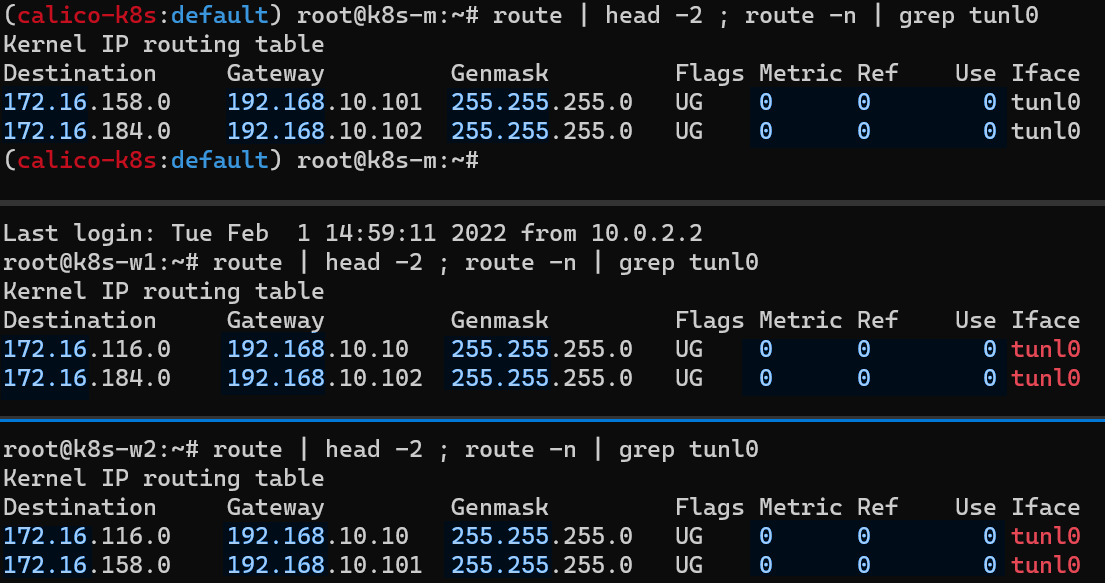
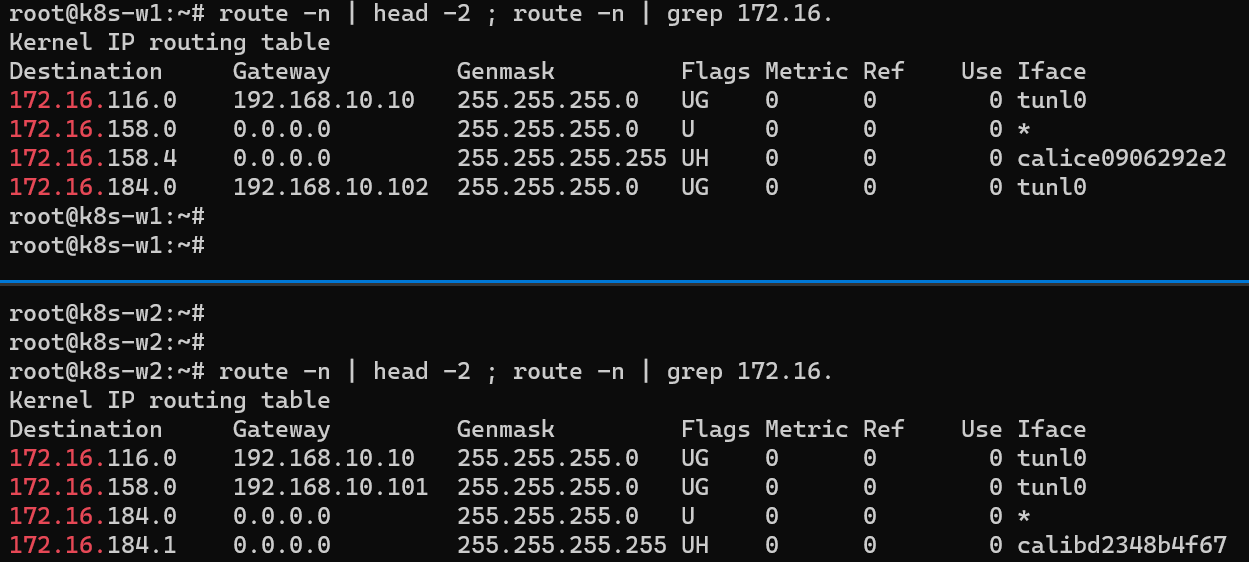
파드 배포 전, 노드에서 BGP에 의해 전달 받은 정보가 호스트 라우팅 테이블에 존재하는지 확인
아래 명령어를 통해 나머지 노드들의 파드 대역을 자신의 호스트 라우팅 테이블에 가지고 있고, 해당 경로는 tunl0 인터페이스로 보내게 된다는 사실을 알 수 있다.
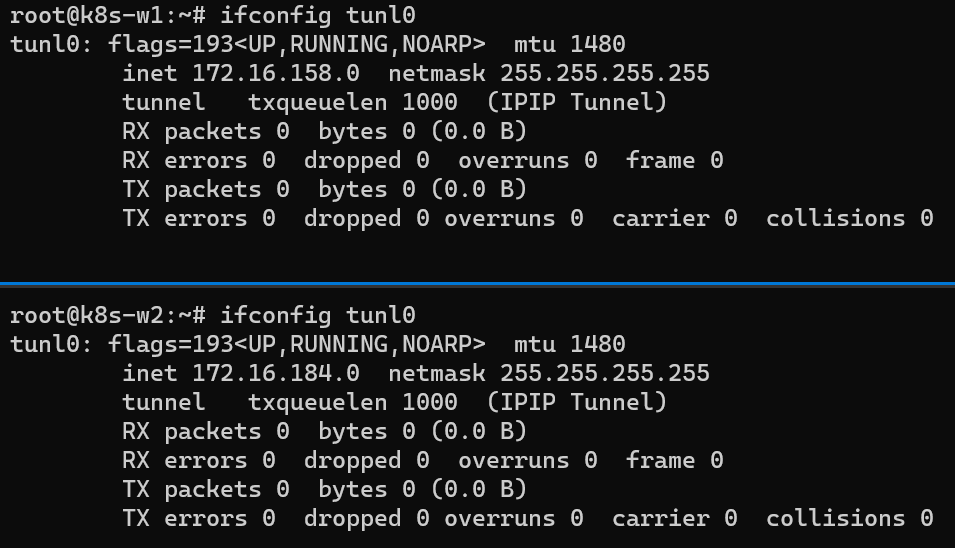
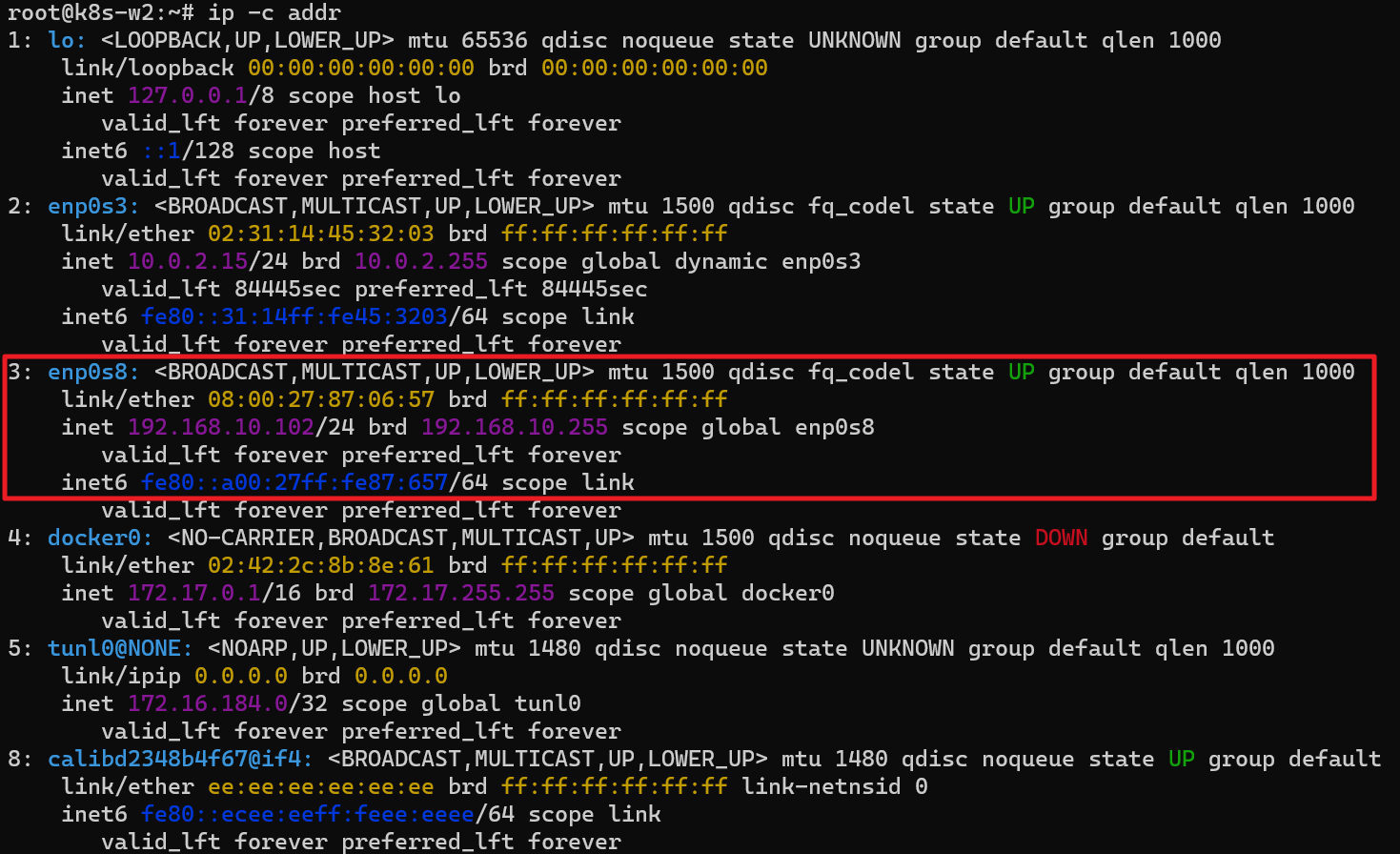
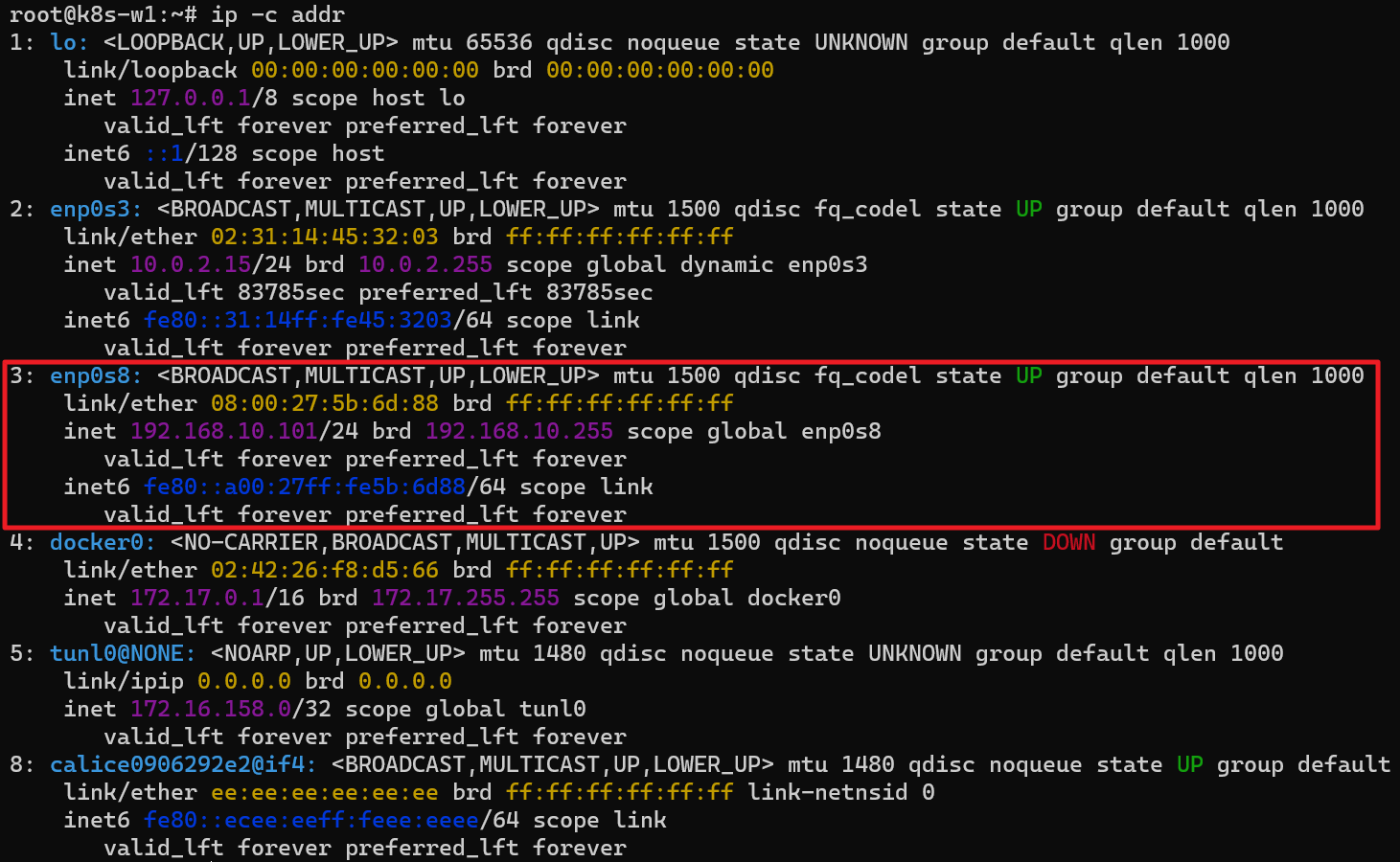
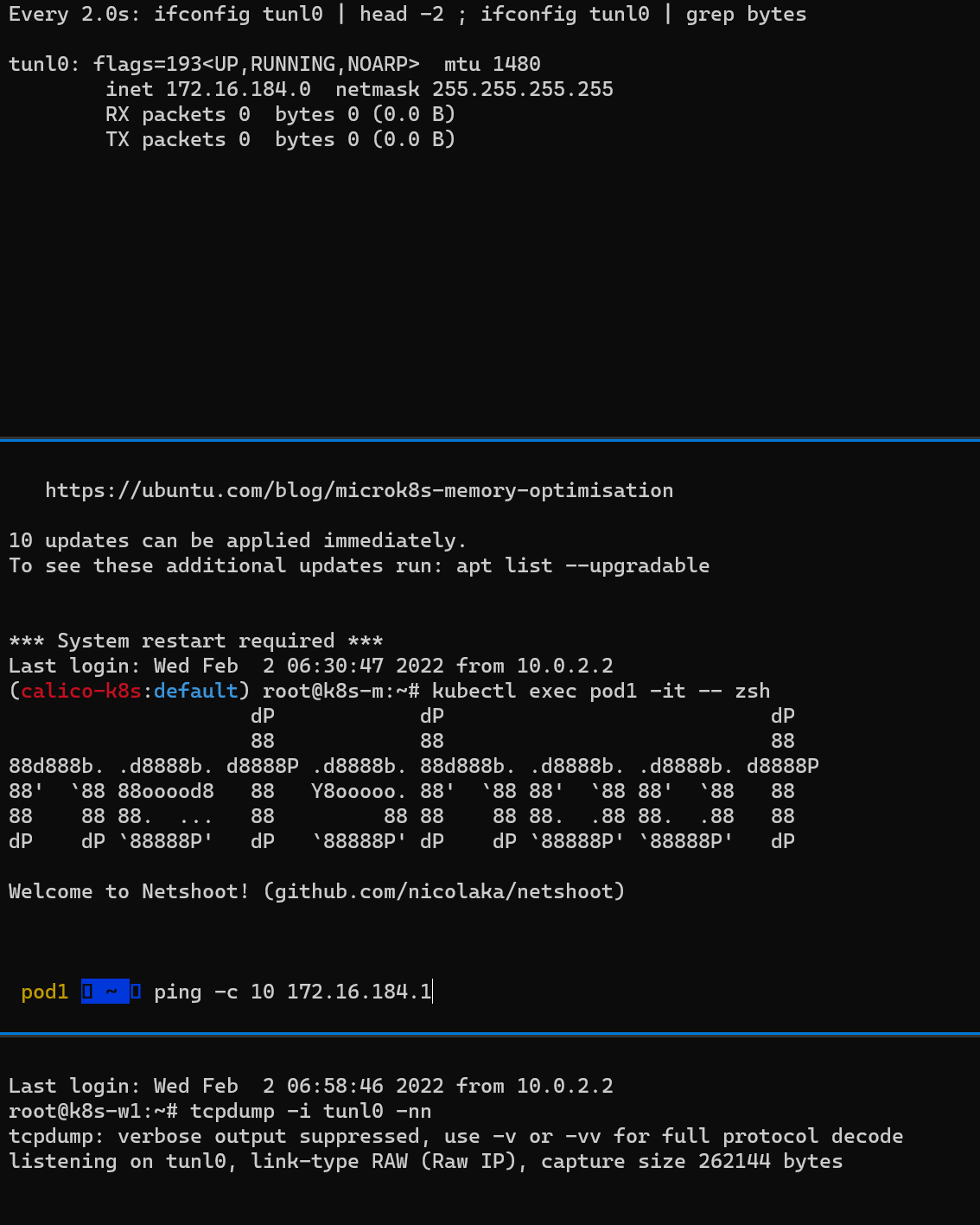
워커 노드(k8s-w1, w2)의 tunl0 정보 확인
터널 인터페이스가 IP에 할당되어 있음
MTU는 1480 (칼리코 사용 시 파드의 인터페이스도 기본 MTU 1480 사용)
현재 TX/RX 카운트는 0 –> 잠시 후, 오버레이 통신시 카운트 값이 증가할 것
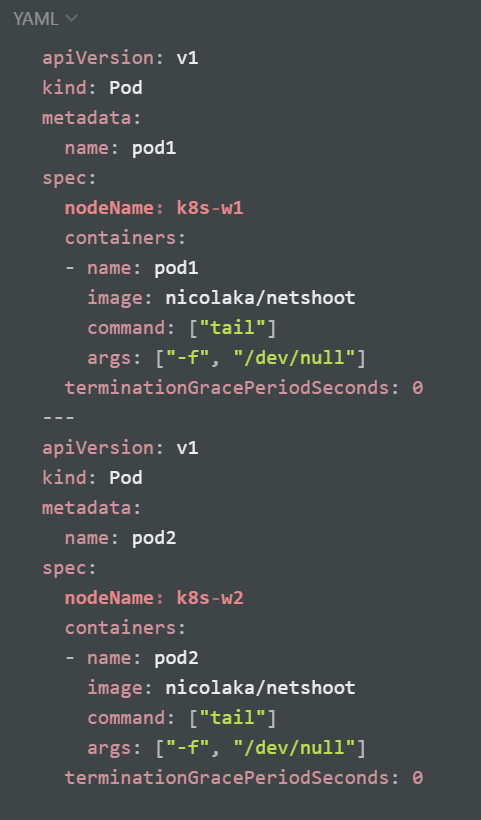
마스터 노드에서 워커 노드(k8s-w1, w2) 대상으로 각각 파드 1개씩 생성
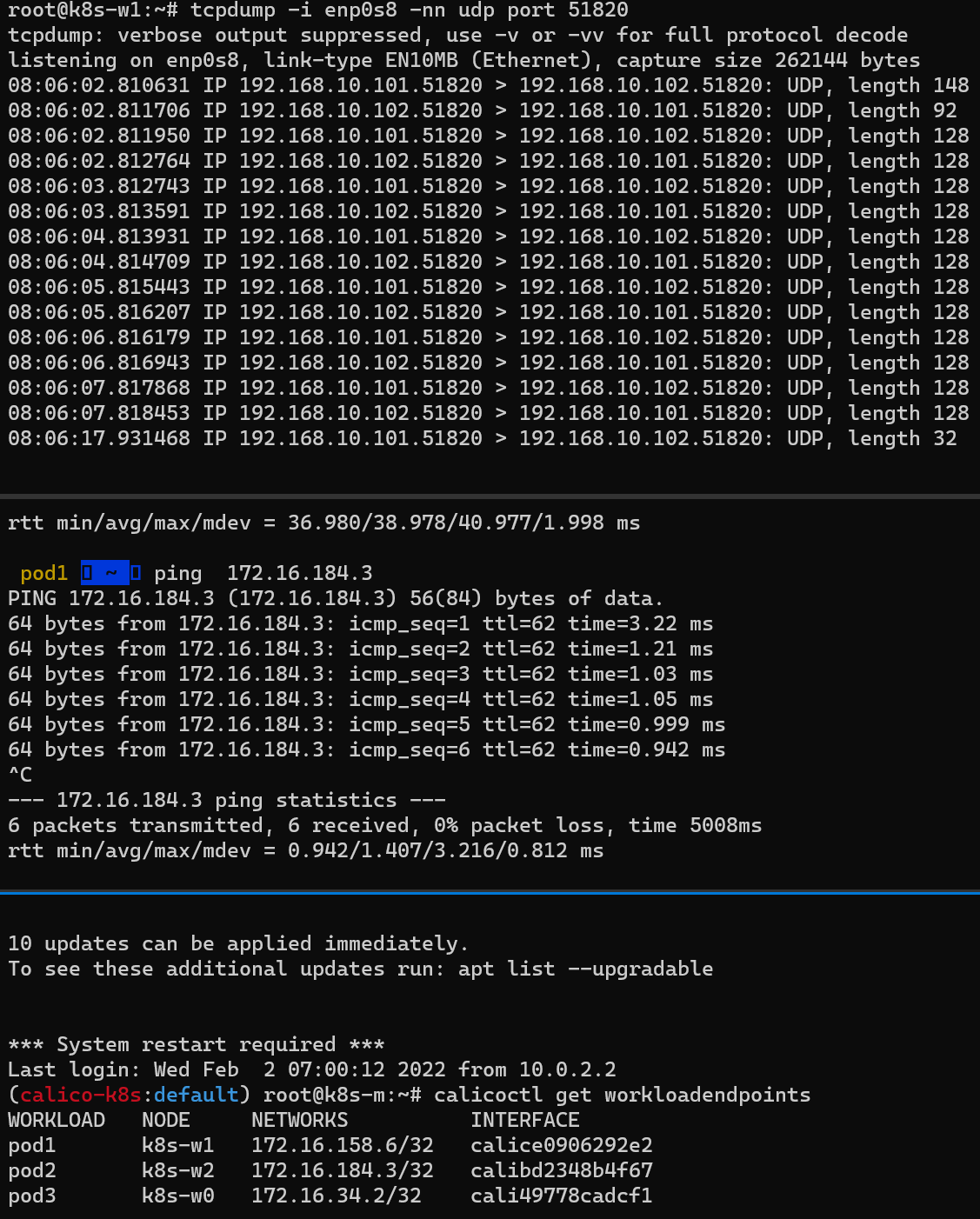
calicoctl 명령어를 이용하여 생성된 파드의 엔드포인트 확인
각 노드에서 파드 간 통신을 처리하는 라우팅 정보 확인
k8s-w1(172.16.158.4/32) 노드에서 w2(172.16.184.0) 노드 대역에 통신하려면 192.168.10.102를 거쳐야 한다는 것을 확인할 수 있다.
반대로 w2(172.16.184.1/32) 노드에서 w1(172.16.158.0) 노드 대역에 통신하려면 192.168.10.101를 거쳐야 한다.
다른 노드 파드 간 통신이 어떻게 실행되는지 확인 ⇒ IPIP
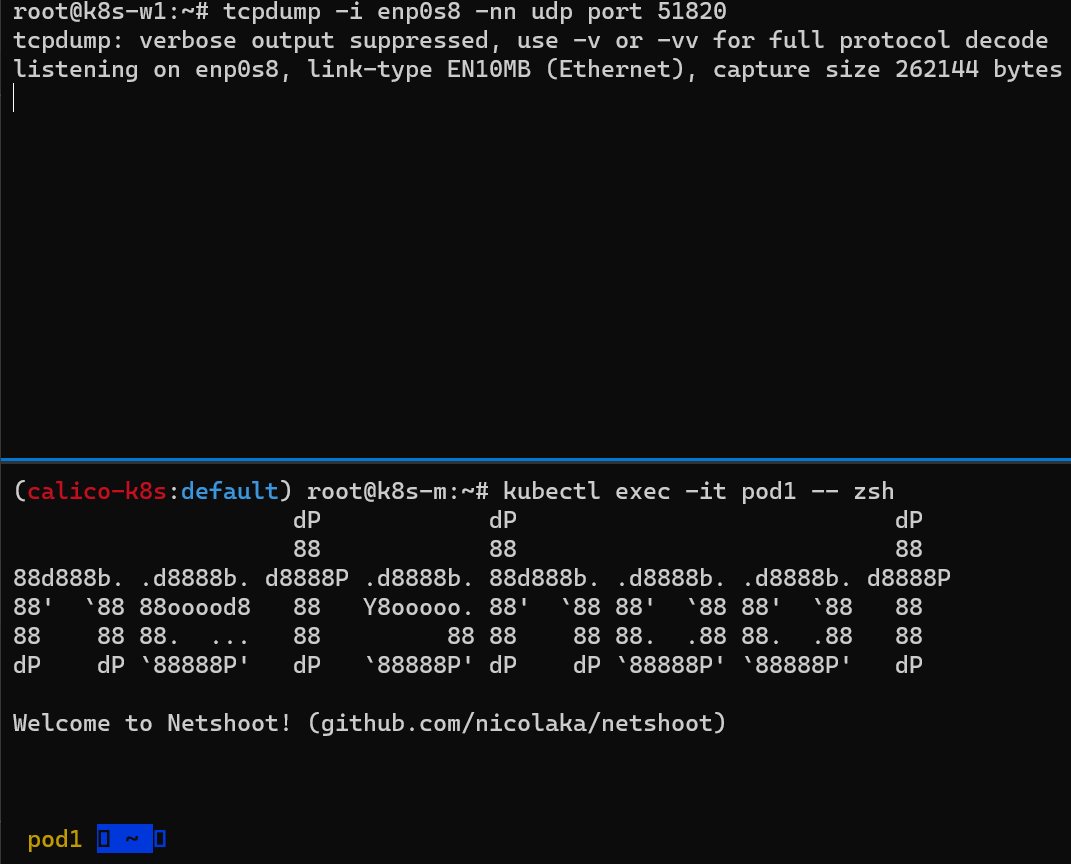
(상) Pod2가 속한 노드(k8s-w2)에 tunl0 인터페이스 TX/RX 패킷 카운트 모니터링 세팅
(중) 마스터 노드에서 Pod1 Shell 접속 후, Pod2로 Ping 통신 테스트 준비
(하) Pod1이 속한 노드(k8s-w1)에서 패킷 덤프 세팅: tunl0 – 터널 인터페이스에 파드간 IP 패킷 정보를 확인할 수 있음
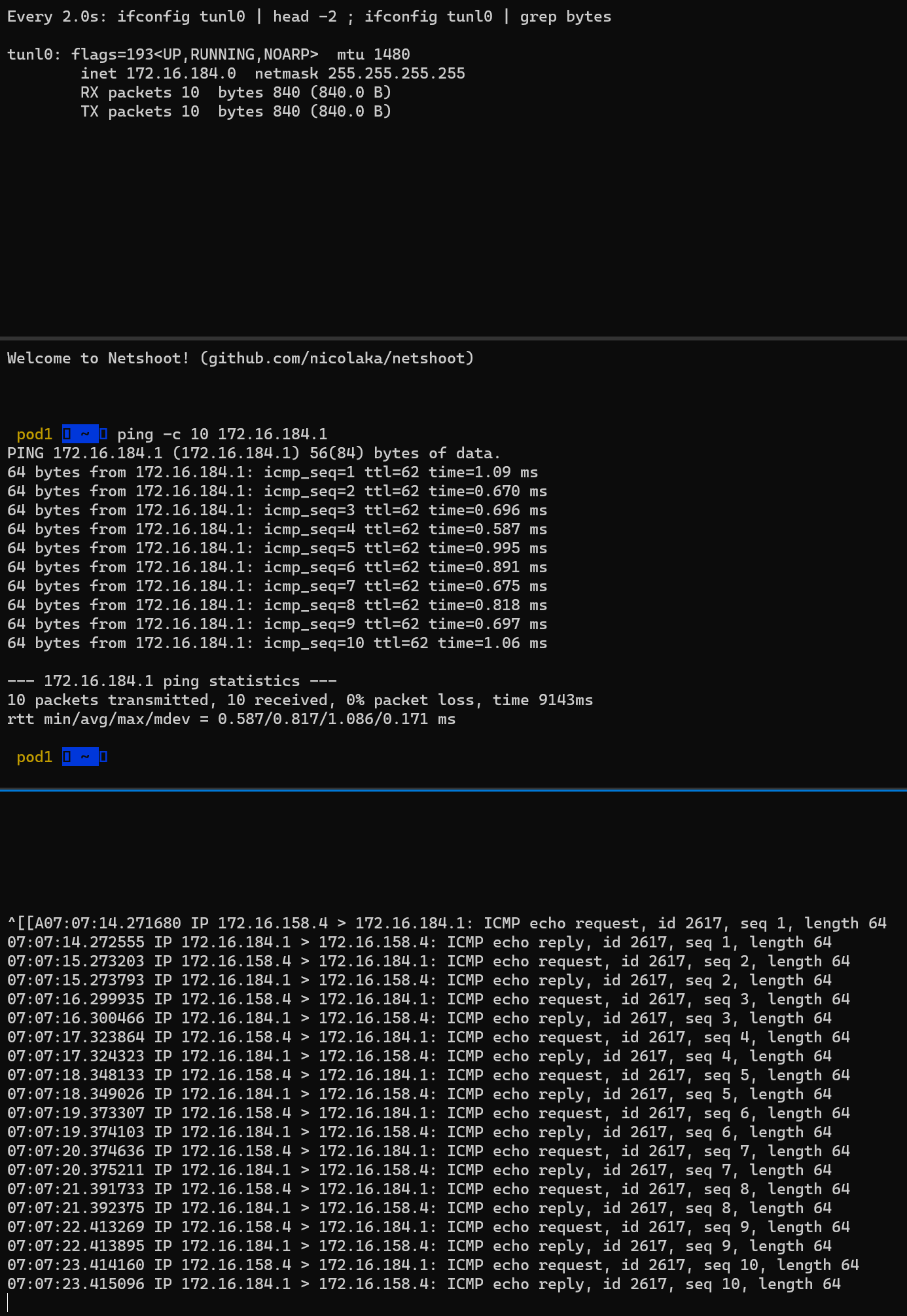
결과
(중) Pod1 –> Pod2로 정상 통신 확인
(상) tunl0 인터페이스의 TX/RX 패킷 카운트가 각각 10개로 증가
(하) 실제 통신을 하게 되는 파드 간 IP 패킷 정보 확인
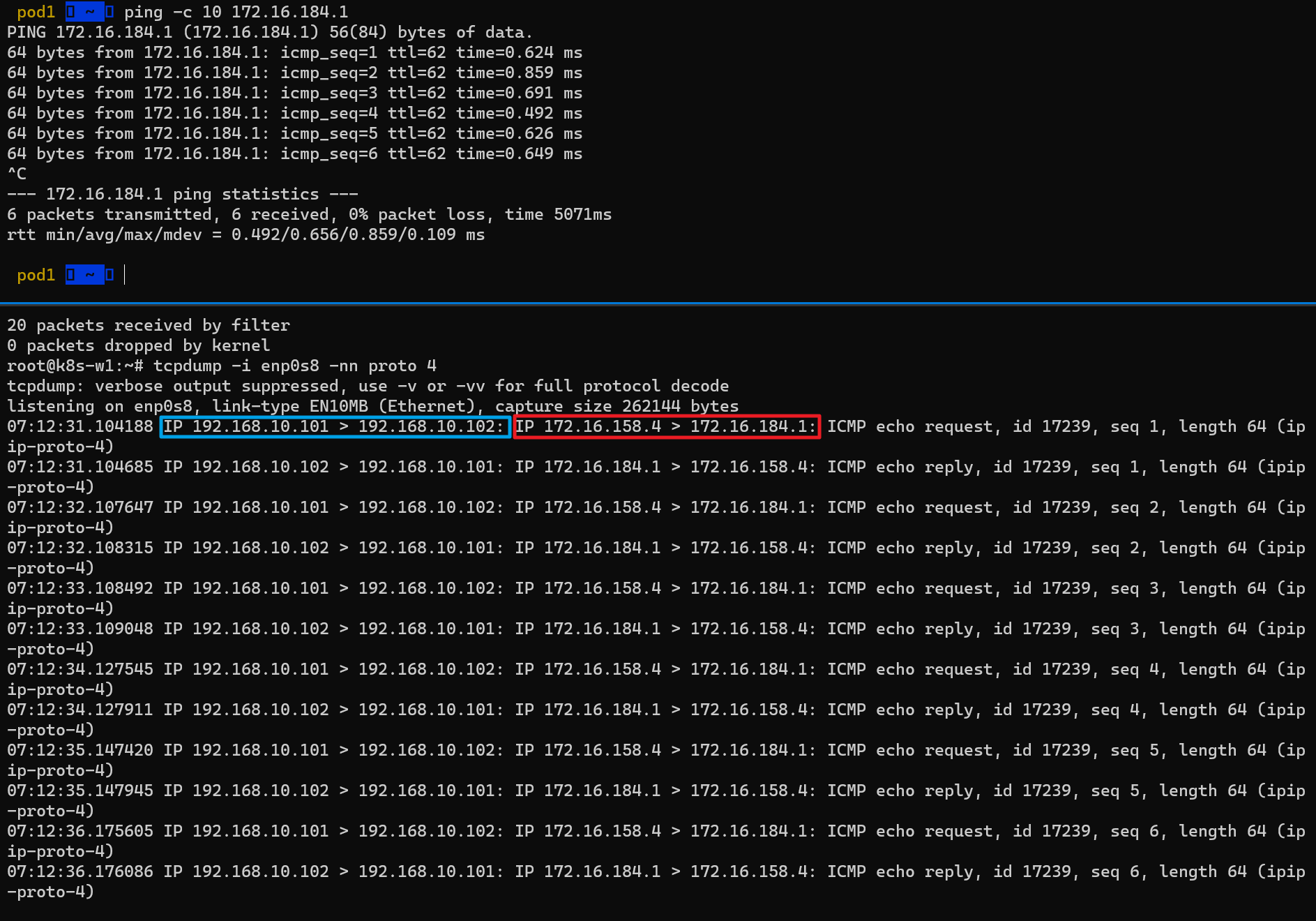
실제로 오버레이 통신을 하고 있는지 확인하기 위해 패킷덤프 명령어를 아래와 같이 수정하여 Ping 통신을 다시 하였고, 결과적으로 IP Outer(파란색 박스) 헤더 정보 안쪽에 Inner(빨간색 박스) 헤더가 1개 더 있음을 확인할 수 있다.
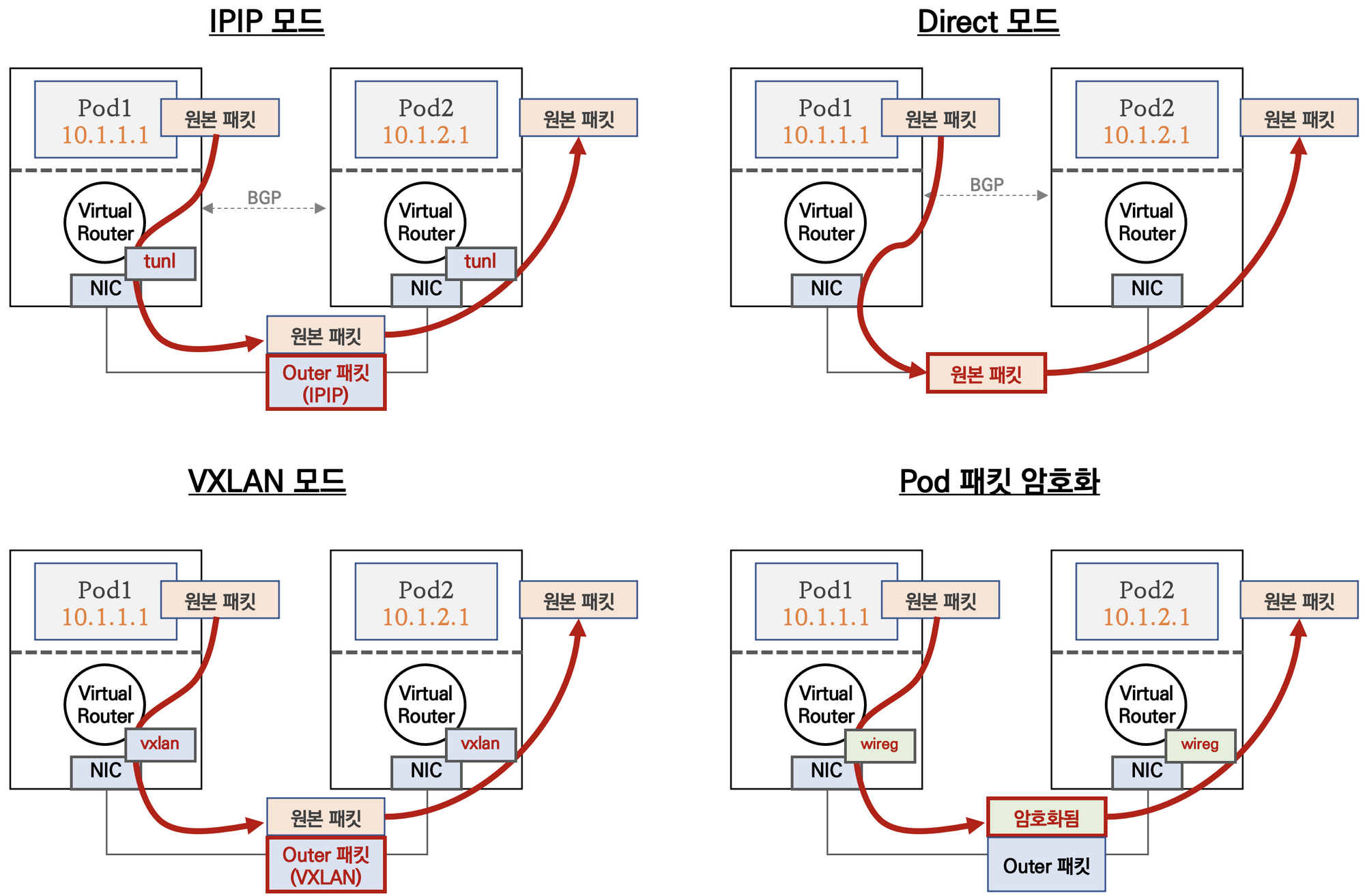
Calico 네트워크 모드
Calico Mode 요약
칼리코는 다양한 네트워크 통신 방법을 제공한다.
IPIP 모드
파드 간 통신이 노드와 노드 구간에서는 IPIP 인캡슐레이션을 통해 이루어진다.
단, Azure 네트워크에서는 IPIP 통신이 불가능하기 때문에 대신 VXLAN 모드를 사용한다고 한다.
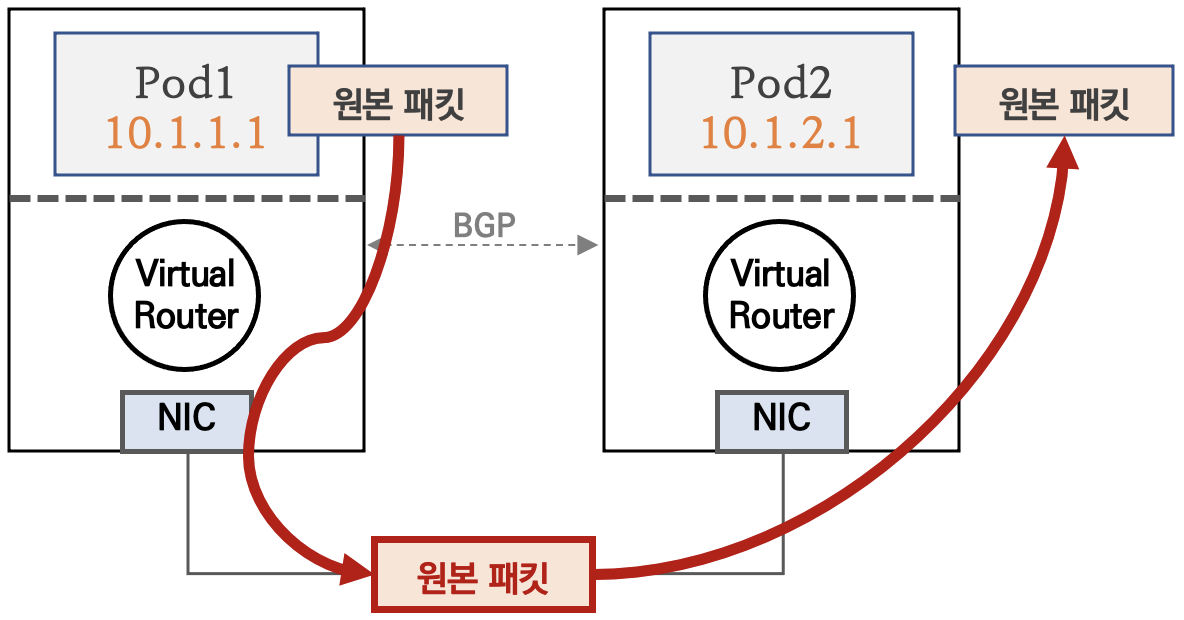
Direct 모드
파드 통신 패킷이 출발지 노드의 라우팅 정보를 보고 목적지 노드로 원본 패킷 그대로 전달된다.
단, 클라우드 사업자 네트워크 사용 시, NIC에 매칭되지 않는 IP 패킷은 차단되니 NIC의 Source/Destination Check 기능을 Disable해야 정상 통신 가능 (AWS 문서 링크)
BGP 연동
Kubernetes 클러스터 내부 네트워크와 IDC 내부망 네트워크 간 직접 라우팅도 가능
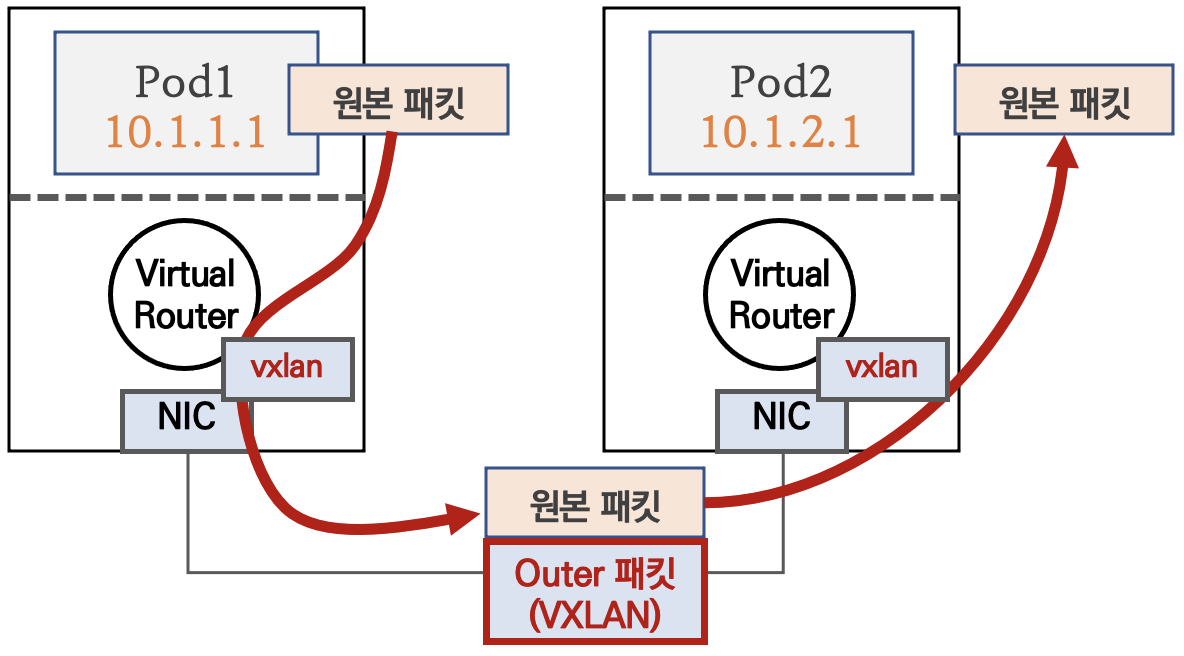
VXLAN 모드
파드 간 통신이 노드와 노드 구간에서는 VXLAN 인캡슐레이션을 통해서 이루어진다.
다른 노드 간의 파드 통신은 vxlan 인터페이스를 통해 L2 프레임이 UDP – VXLAN에 감싸져 상대 노드로 도달 후 vxlan 인터페이스에서 Outer헤더를 제거하고 내부의 파드와 통신하게 된다.
BGP 미사용, VXLAN L3 라우팅을 통해서 동작한다.
UDP를 사용하므로 Azure 네트워크에서도 사용 가능하다.
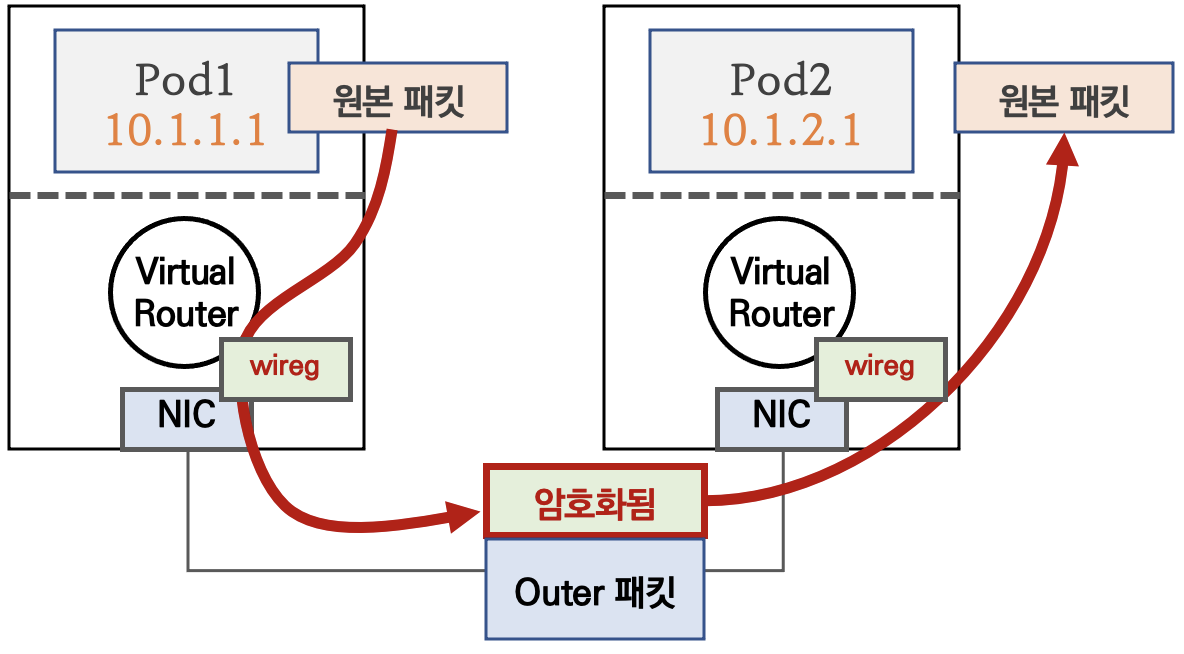
Pod 패킷 암호화(네트워크 레벨)
Calico의 다양한 네트워크 모드 환경 위에서 WireGuard 터널을 자동 생성 및 파드 트래픽을 암호화하여 노드 간 전달한다.
Yaml 파일에 간단하게 추가하는 것만으로도 네트워크 레벨의 패킷 암호화를 설정할 수 있다.
이제 이미지도 준비되었고, yaml 파일만 생성하여 기동해보면 된다.
도커와는 다르게 쿠버네티스의 경우에는 쿠버네티스 클러스터 내에서 동작하기 때문에 생성된 컨테이너의 IP 또한 클러스터 내의 CNI 네트워크 대역으로 할당된다.
그렇기 때문에 외부에서 해당 컨테이너에 접근하여 서비스를 호출하려면 Service를 통해 가능하다. AWS나 GCP같은 Public Cloud의 경우에는 Service에서 LoadBalnancer를 제공하여 외부로 노출할 IP를 할당 받지만, 우리가 테스트하는 방식과 같이 Baremetal(On-Premise) 환경에서는 LoadBalancer 기능이 없다. 그래서 LoadBalancer타입을 지원하게끔 하기 위해 MetalLB라는 놈을 사용해주어야 한다.
=================================
metallb.yaml 파일을 이용하여 파드와 기타 등등의 서비스를 실행한다.
이후, metallb-system 네임스페이스에 있는 리소스들을 조회해본다.
=================================
root@master:~/yaml# kc get all -n metallb-system
NAME READY STATUS RESTARTS AGE
pod/controller-675d6c9976-d5k57 1/1 Running 0 9s
pod/speaker-h4l8n 1/1 Running 0 9s
pod/speaker-rm54l 1/1 Running 0 9s
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
daemonset.apps/speaker 2 2 2 2 2 beta.kubernetes.io/os=linux 9s
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/controller 1/1 1 1 9s
NAME DESIRED CURRENT READY AGE
replicaset.apps/controller-675d6c9976 1 1 1 9s
이제 3-Tier환경의 컨테이너를 생성할 차례다.
yaml 파일의 경우 아래와 같다.
모든 항목들을 세세히 설명할 수는 없고 하나씩 찾아보면 기본적인 설정(포트/환경변수)만 되어있음을 볼 수 있다.
이 글에서는 가볍게 구성해보는 것이기 때문에 다음 글에서 좀 더 yaml 문법이나 파라미터 값을 공부해보아야 겠다.
$ kubectl apply -f deploy/kubernetes/
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
deployment.apps/metrics-server created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
중간에 metrics.k8s.io라는 API가 생성되어 Api server에 등록된 것을 확인할 수 있습니다.
$ kubectl apply -f autoscaler.yaml
horizontalpodautoscaler.autoscaling/php-apache created
hpa커맨드를 통해 현재 hpa에 감지되는 시스템 부하정도와 관리하는 pod의 개수를 확인할 수 있습니다.
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 1 18s
아직은 서버로 어떠한 요청도 하지 않았기 때문에, 현재 cpu소비량은 0%임을 알 수 있습니다. (TARGET은 deployment에 의해 제어되는 pod들의 평균을 뜻합니다.)
부하테스트
부하가 증가함에 따라 오토스케일러가 어떻게 반응하는지 살펴보겠습니다.
창을 하나 더 띄워서 php-apache 서비스에 무한루프 쿼리를 전송합니다.
$ kubectl run -it--rm load-generator --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ #
/ # while true; do wget -q -O- http://php-apache.default.svc.cluster.local; done
OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!OK!...
1~2분 지난 뒤에 hpa커맨드로 부하상태를 살펴보면 TARGET의 수치가 높아진 것을 확인할 수 있습니다.
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 248%/50% 1 10 1 9m7s
그리고 deployment 컨트롤러를 확인해보면 pod의 replica수가 5개까지 늘어난 것을 확인할 수 있습니다.
$ kubectl get deploy php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 5/5 5 5 12m
busybox컨테이너를 띄운 터미널에서 Ctrl+C로 부하 발생을 중단시키고, 몇 분 후에 결과를 확인합니다.
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
php-apache Deployment/php-apache 0%/50% 1 10 5 11m
cpu의 사용량이 0%까지 떨어졌고, deployment의 pod replica수도 1개로 줄어든 것을 확인할 수 있습니다.
$ kubectl get deploy php-apache
NAME READY UP-TO-DATE AVAILABLE AGE
php-apache 1/1 1 1 19m
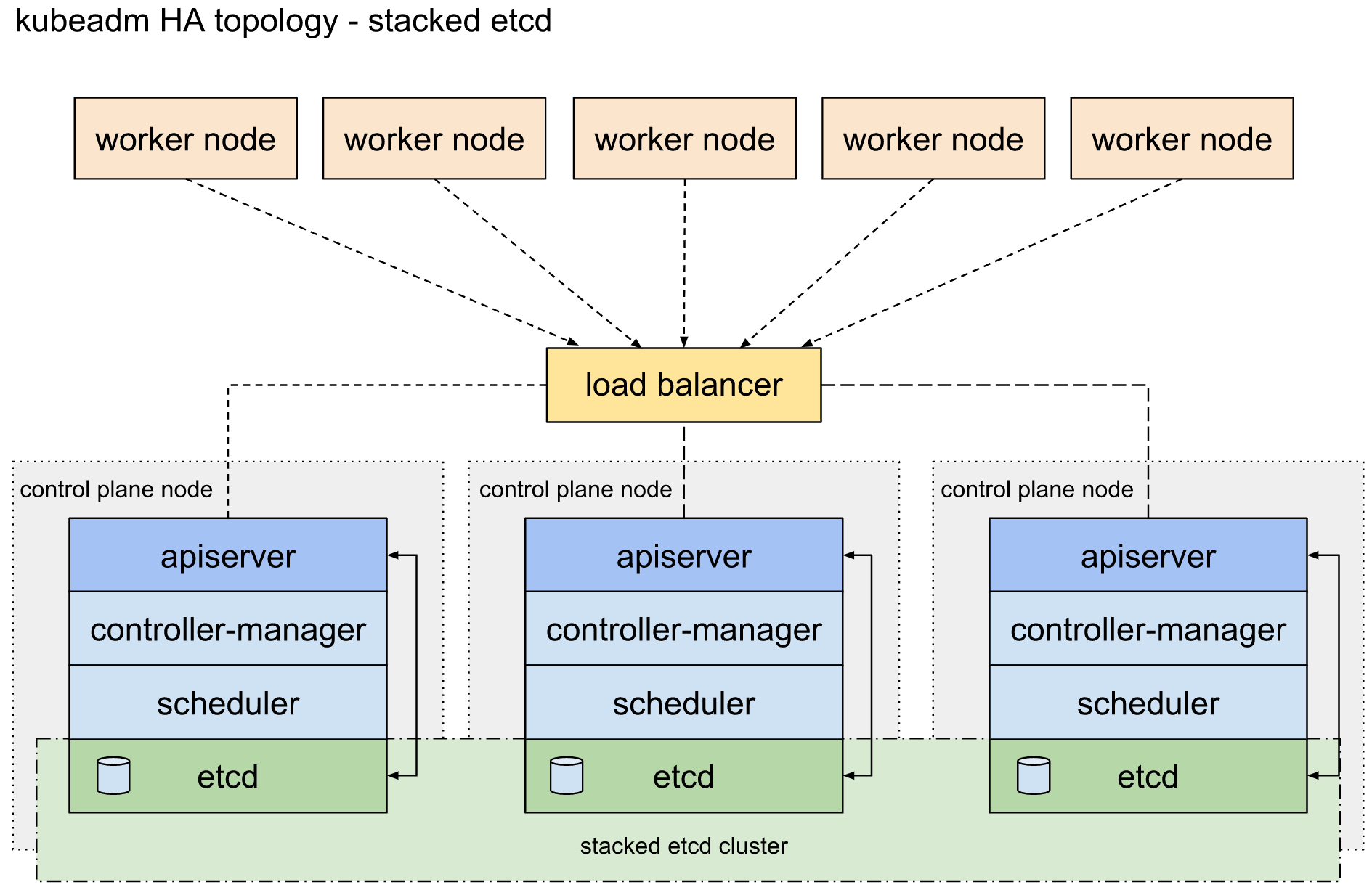
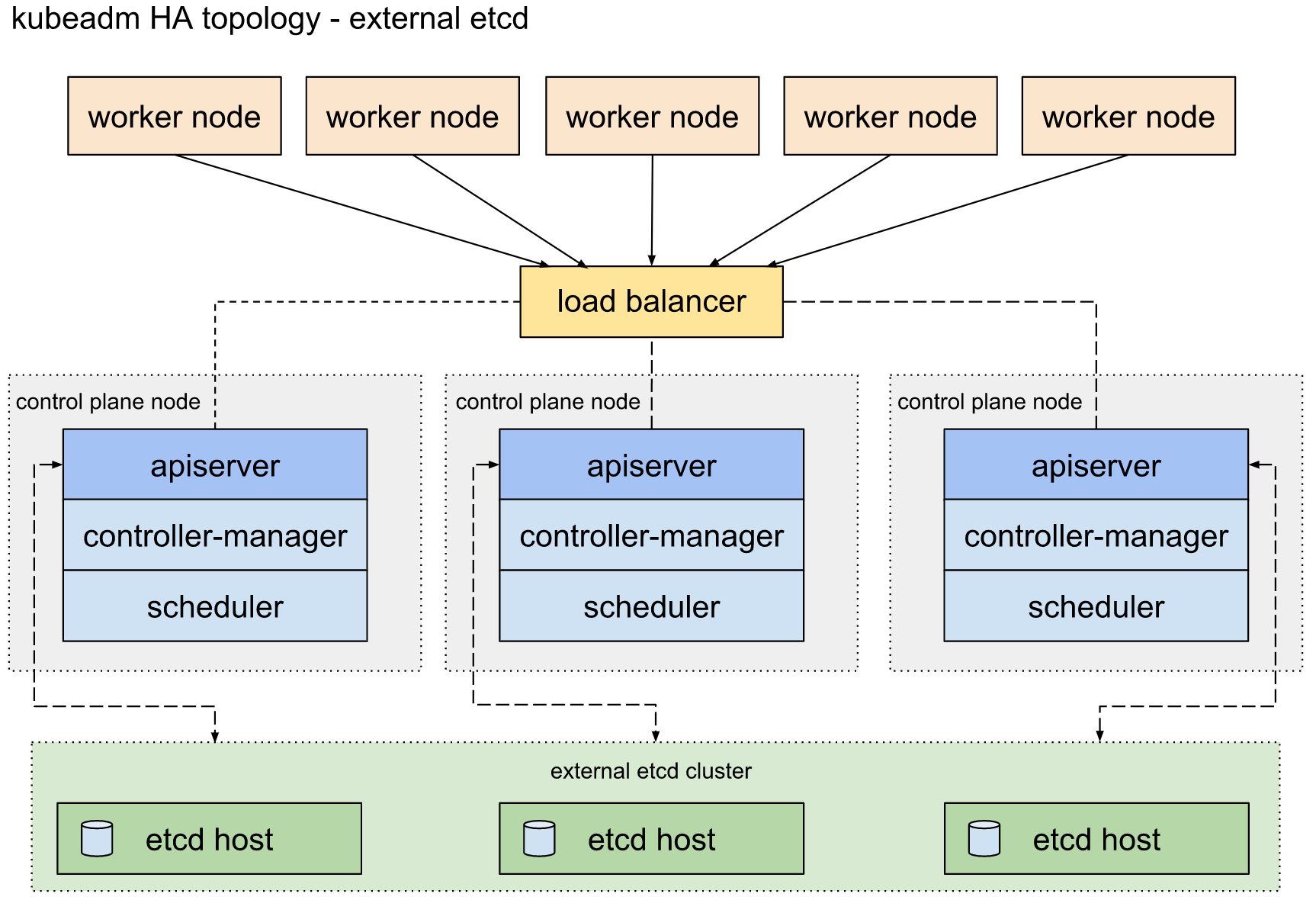
kubernetes에서 HA를 구성하는 방법으로 stacked etcd, external etcd 두가지 방법이 있다. 그림 1의 stacked etcd는 control plane node에서 etcd가 작동하는 반면, 그림 2의 external etcd는 control plane node와 etcd가 다른 노드에서 작동한다. HA를 구성하기 위해서는 쿼럼이 과반수를 초과해야만 하기 때문에 최소 3대 이상(3,5,7,…)의 노드를 필요로 한다. 이번 시간에는 stacked etcd 를 구성하는 방법에 대해 알아보고자 한다.
[그림 1] HA 토폴로지 – stacked etcd[그림 1] HA 토폴로지 – external etcd
구성환경
Ubuntu 18.04.1, Docker 19.03.8, Kubernet v1.17.4
사전 준비
Docker, Kubernet이 미리 설치 되어 있어야한다.
로드 발란서(Load Balancer)
– dns 로드 발란서 사용, apisvr 라운드로빈(round-robin) 활용, 참고로 도메인은 hoya.com
apisvr IN A 192.168.0.160
IN A 192.168.0.161
IN A 192.168.0.162
–upload-certs : control plane 인스턴스에서 공유해야 하는 인증서를 업로드(자동배포), 수동으로 인증서를 복사할 경우는 이 옵션 생략
control plane 초기화(kubeadm init)를 진행하면 아래와 같은 내용이 출력될 것이다. 아래 내용을 복사해 놓도록 한다. 이 명령어를 이용하여 클러스터에 조인(join) 할수 있다. 파란색글씨(위쪽)는 control plane 노드에서 실행, 주황색 글씨(아래)는 worker node에서 실행
You can now join any number of control-plane node by running the following command on each as a root:
kubeadm join apisvr.hoya.com:6443 –token 9vr73a.a8uxyaju799qwdjv –discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 –control-plane –certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use kubeadm init phase upload-certs to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join apisvr.hoya.com:6443 –token 9vr73a.a8uxyaju799qwdjv –discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866
참고: 인증서를 다시 업로드하고 새 암호 해독 키를 생성하려면 이미 클러스터에 연결된 control plane 노드에서 다음 명령을 사용하십시오.
shell> sudo kubeadm init phase upload-certs –upload-certs
W0322 16:20:40.631234 101997 validation.go:28] Cannot validate kube-proxy config – no validator is available
W0322 16:20:40.631413 101997 validation.go:28] Cannot validate kubelet config – no validator is available
[upload-certs] Storing the certificates in Secret “kubeadm-certs” in the “kube-system” Namespace
[upload-certs] Using certificate key:
7f97aaa65bfec1f039c4dbdf3a2073de853c708bd4d9ff9d72b776b0f9874c9d
참고 : 클러스터를 control plane 조인(join)하는 데 필요한 전체 ‘kubeadm join’ 플래그를 출력
shell> kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 41s v1.17.4
master2 Ready master 3m59s v1.17.4
master3 Ready master 92s v1.17.4
shell>
** kubectl delete node로 control plane노드 를 제거하지 않도록 한다. 만약 kubectl delete node로 삭제하는 경우 이후 추가 되는 control plane 노드들은 HA에 추가 될수 없다. 그 이유는 kubeadm reset은 HA내 다른 control plane 노드의 etcd에서 etcd endpoint 정보를 지우지만 kubectl delete node는 HA 내의 다른 controle plane 노드에서 etcd endpoint 정보를 지우지 못하기 때문이다. 이로 인해 이후 HA에 추가되는 control plane 노드는 삭제된 노드의 etcd endpoint 접속이 되지 않기 때문에 etcd 유효성 검사 과정에서 오류가 발생하게 된다.
– control plane 노드를 kubectl delete node 로 삭제후 control plane 노드 추가시 오류 메시지
shell> kubeadm join ….. –control-plane –certyficate-key
… 생략 …
[check-etcd] Checking that the etcd cluster is healthy
error execution phase check-etcd: etcd cluster is not healthy: failed to dial endpoint https://192.168.0.159:2379 with maintenance client: context deadline exceeded
To see the stack trace of this error execute with –v=5 or higher
Kubernetes는 온프레미스 서버 또는 하이브리드 클라우드 환경에서 대규모로 컨테이너화된 애플리케이션을 오케스트레이션 및 관리하기 위한 도구입니다. Kubeadm은 사용자가 모범 사례 시행을 통해 프로덕션 준비 Kubernetes 클러스터를 설치할 수 있도록 Kubernetes와 함께 제공되는 도구입니다. 이 튜토리얼은 kubeadm을 사용하여 Ubuntu 20.04에 Kubernetes 클러스터를 설치하는 방법을 보여줍니다.
Kubernetes 클러스터 배포에는 두 가지 서버 유형이 사용됩니다.
마스터 : Kubernetes 마스터는 Kubernetes 클러스터의 포드, 복제 컨트롤러, 서비스, 노드 및 기타 구성 요소에 대한 제어 API 호출이 실행되는 곳입니다.
Node : Node는 컨테이너에 런타임 환경을 제공하는 시스템입니다. 컨테이너 포드 세트는 여러 노드에 걸쳐 있을 수 있습니다.
실행 가능한 설정을 위한 최소 요구 사항은 다음과 같습니다.
메모리: 컴퓨터당 2GiB 이상의 RAM
CPU: 컨트롤 플레인 머신에 최소 2개의 CPU 가 있습니다.
컨테이너 풀링을 위한 인터넷 연결 필요(개인 레지스트리도 사용할 수 있음)
클러스터의 머신 간 전체 네트워크 연결 – 개인 또는 공용입니다.
Ubuntu 20.04에 Kubernetes 클러스터 설치
My Lab 설정에는 3개의 서버가 있습니다. 컨테이너화된 워크로드를 실행하는 데 사용할 하나의 컨트롤 플레인 머신과 두 개의 노드. 예를 들어 HA용 제어 평면 노드 3개 를 사용하여 원하는 사용 사례 및 부하에 맞게 노드를 더 추가할 수 있습니다 .
서버 유형
서버 호스트 이름
명세서
주인
k8s-master01.computingforgeeks.com
4GB 램, 2vcpus
노동자
k8s-worker01.computingforgeeks.com
4GB 램, 2vcpus
노동자
k8s-worker02.computingforgeeks.com
4GB 램, 2vcpus
1단계: Kubernetes 서버 설치
Ubuntu 20.04에서 Kubernetes 배포에 사용할 서버를 프로비저닝합니다. 설정 프로세스는 사용 중인 가상화 또는 클라우드 환경에 따라 다릅니다.
systemd cgroup 드라이버를 사용하려면 에서 plugins.cri.systemd_cgroup = true 를 설정 /etc/containerd/config.toml하십시오. kubeadm을 사용할 때 kubelet 용 cgroup 드라이버를 수동으로 구성하십시오.
--control-plane-endpoint : 모든 제어 평면 노드에 대한 공유 끝점을 설정합니다. DNS/IP일 수 있음
--pod-network-cidr : 포드 네트워크 추가 기능을 설정하는 데 사용됨 CIDR
--cri-socket : 런타임 소켓 경로를 설정하기 위해 컨테이너 런타임이 둘 이상인 경우 사용
--apiserver-advertise-address : 이 특정 제어 평면 노드의 API 서버에 대한 광고 주소 설정
....
[init] Using Kubernetes version: v1.22.2
[preflight] Running pre-flight checks
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Using existing ca certificate authority
[certs] Using existing apiserver certificate and key on disk
[certs] Using existing apiserver-kubelet-client certificate and key on disk
[certs] Using existing front-proxy-ca certificate authority
[certs] Using existing front-proxy-client certificate and key on disk
[certs] Using existing etcd/ca certificate authority
[certs] Using existing etcd/server certificate and key on disk
[certs] Using existing etcd/peer certificate and key on disk
[certs] Using existing etcd/healthcheck-client certificate and key on disk
[certs] Using existing apiserver-etcd-client certificate and key on disk
[certs] Using the existing "sa" key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/admin.conf"
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/scheduler.conf"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0611 22:34:23.276374 4726 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0611 22:34:23.278380 4726 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 8.008181 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.21" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s-master01.computingforgeeks.com as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-master01.computingforgeeks.com as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: zoy8cq.6v349sx9ass8dzyj
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join k8s-cluster.computingforgeeks.com:6443 --token sr4l2l.2kvot0pfalh5o4ik \
--discovery-token-ca-cert-hash sha256:c692fb047e15883b575bd6710779dc2c5af8073f7cab460abd181fd3ddb29a18 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-cluster.computingforgeeks.com:6443 --token sr4l2l.2kvot0pfalh5o4ik \
--discovery-token-ca-cert-hash sha256:c692fb047e15883b575bd6710779dc2c5af8073f7cab460abd181fd3ddb29a18
$ kubectl cluster-info
Kubernetes master is running at https://k8s-cluster.computingforgeeks.com:6443
KubeDNS is running at https://k8s-cluster.computingforgeeks.com:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/kubecontrollersconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/apiservers.operator.tigera.io created
customresourcedefinition.apiextensions.k8s.io/imagesets.operator.tigera.io created
customresourcedefinition.apiextensions.k8s.io/installations.operator.tigera.io created
customresourcedefinition.apiextensions.k8s.io/tigerastatuses.operator.tigera.io created
namespace/tigera-operator created
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/tigera-operator created
serviceaccount/tigera-operator created
clusterrole.rbac.authorization.k8s.io/tigera-operator created
clusterrolebinding.rbac.authorization.k8s.io/tigera-operator created
deployment.apps/tigera-operator created
.....
installation.operator.tigera.io/default created
apiserver.operator.tigera.io/default created
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.21" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
제어 플레인에서 아래 명령을 실행하여 노드가 클러스터에 합류했는지 확인합니다.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01.computingforgeeks.com Ready master 10m v1.22.2
k8s-worker01.computingforgeeks.com Ready <none> 50s v1.22.2
k8s-worker02.computingforgeeks.com Ready <none> 12s v1.22.2
$ kubectl get nodes -o wide
Prometheus는 Kubernetes 클러스터의 고급 메트릭 기능에 액세스할 수 있는 완전한 솔루션입니다. Grafana는 Prometheus 데이터베이스에 수집 및 저장되는 메트릭의 분석 및 대화형 시각화에 사용됩니다. Kubernetes 클러스터에서 전체 모니터링 스택을 설정하는 방법에 대한 완전한 가이드가 있습니다.
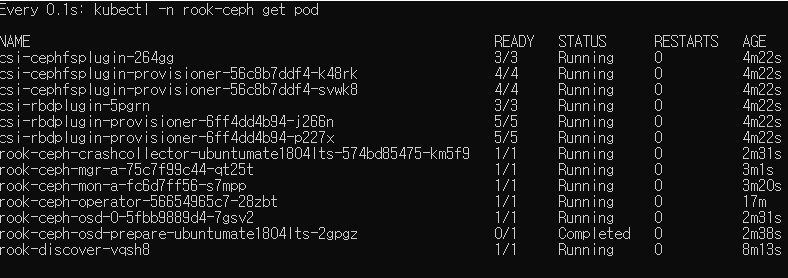
설치에 필요한 도구로 Rook을 사용할 예정입니다. Rook은 오픈소스 클라우드 네이티브 스토리지 오케스트레이터로, 클라우드 네이티브 환경과 기본적으로 통합할 수 있는 다양한 스토리지 솔루션 세트에 대한 플랫폼, 프레임 워크 및 지원합니다. Rook을 통해 Ceph 가상스토리지를 구성하고 공유 파일 시스템을 적용하도록 하겠습니다.
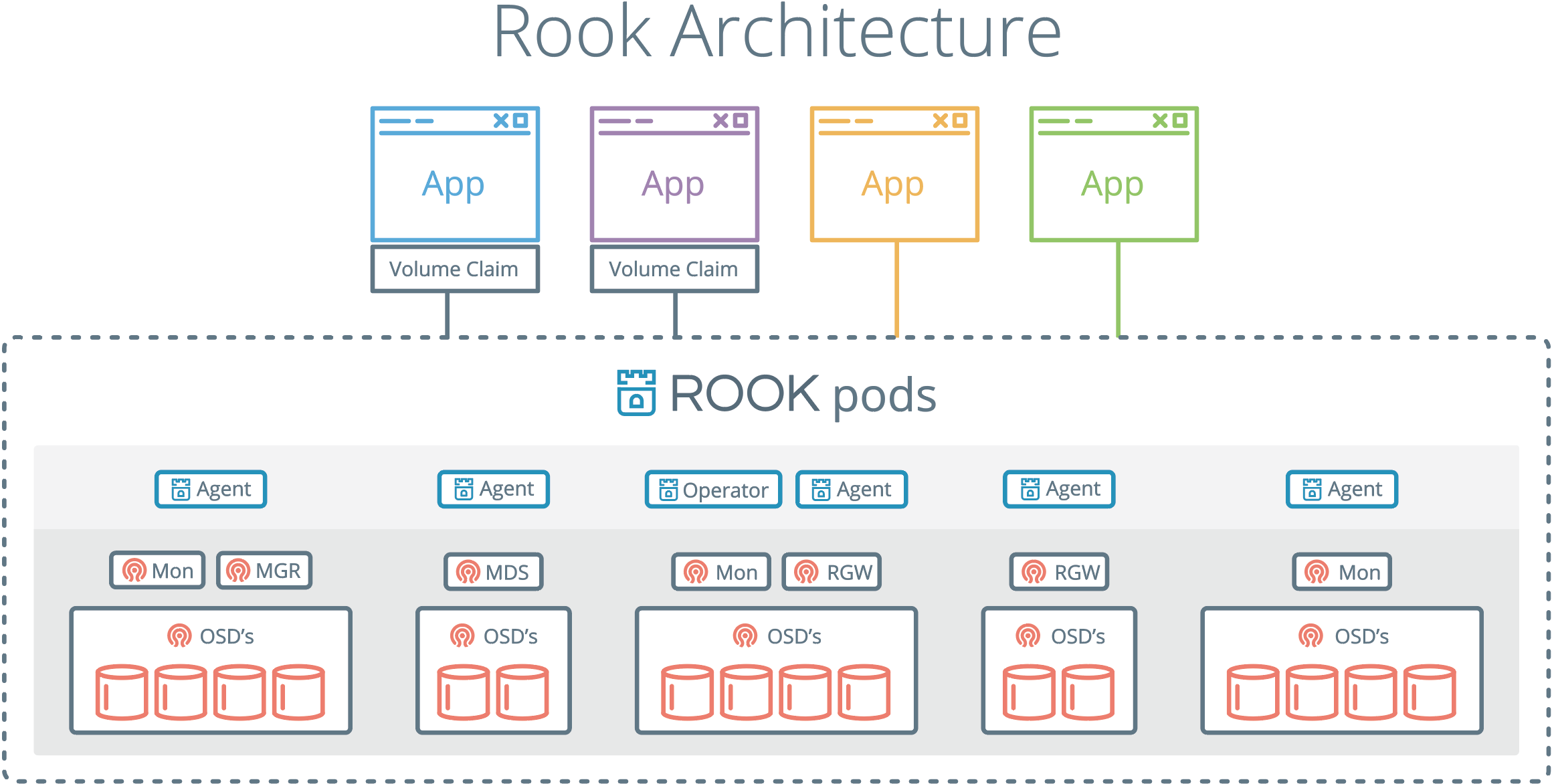
Rook 구성도
Rook은 쿠버네티스 POD에서 실행되며, Ceph, EdgeFS등 가상솔루션을 POD로 배포하여 관리하는 도구입니다. agent를 통해 Ceph, EdgeFS등 가상솔루션을 관리하고, OSD를 통해 데이터를 영구저장합니다.
Ceph vs EdgeFS
Rook에서 제공하는 가상스토리지는 EgdeFS와 Ceph 외에도 다양하게 지원하지만 안정적인 버전은 아래 두가지만 지원합니다.
EdgeFS: 데이터베이스처럼 대용량 스토리지가 필요할때 사용됩니다.
Ceph: 공유 확장에 특화되어 있는 스토리지가 필요할때 사용됩니다.
공유나 확장에 특화되어 있는 Ceph를 설치하도록 하겠습니다.
Ceph 스토리지 유형
Ceph는 Block, Object, File 기반으로 데이터를 사용할 수 있습니다. 각 유형에 따라서 사용하는 기능에 차이가 있습니다.
Block Stroage: 단일 POD에 storage 제공합니다.
Object Storage: 애플리케이션이 쿠버네티스 클러스터 내부 또는 외부에서 액세스 할수있느 데이터를 IO 할수있고, S3 API를 스토리지 클러스터에 노출을 제공합니다.
Shared Stroage: 여러 POD에서 공유할 수있는 파일 시스템기반 스토리지입니다.
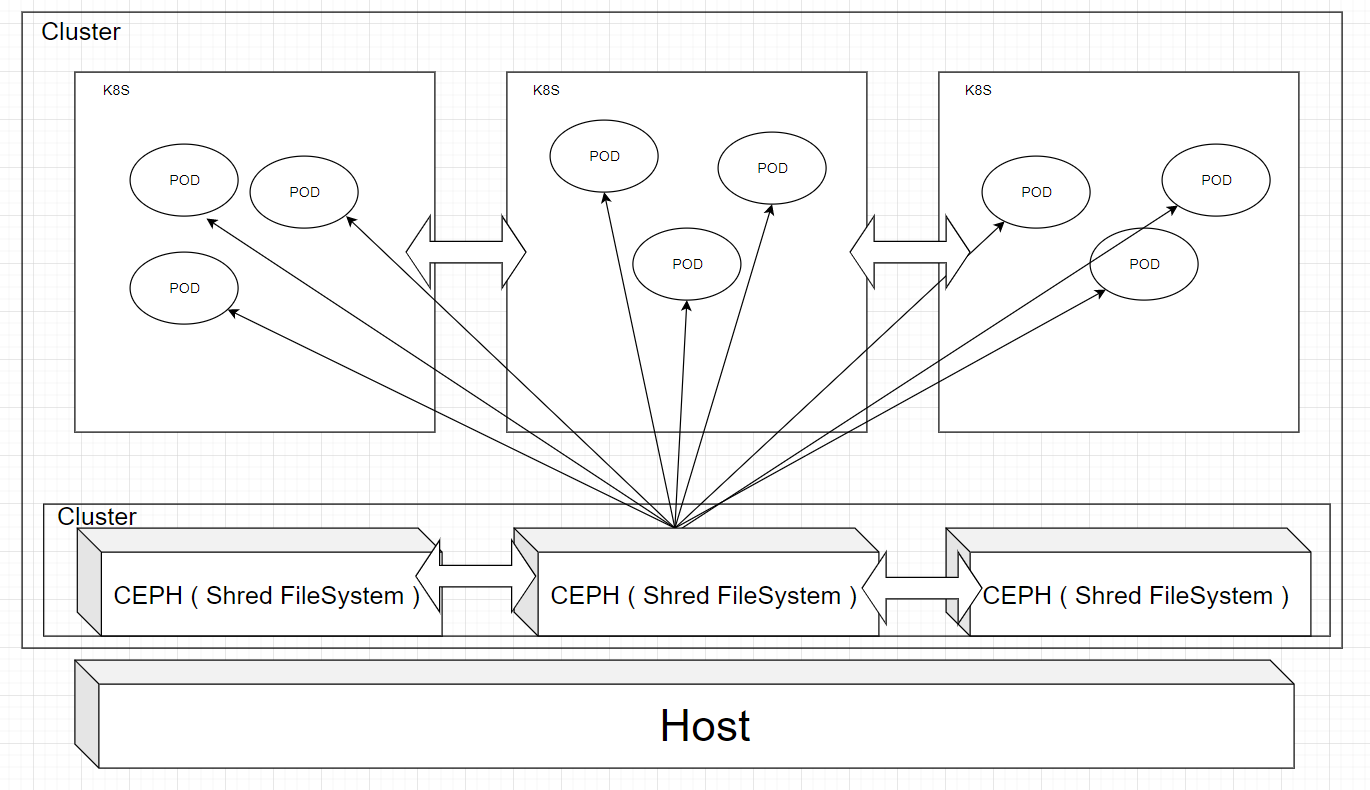
Shared Storage 구성도
이번에 설치해볼 Shared Storage 구성입니다. Ceph 클러스터에 데이터를 저장하고 Ceph를 통해 POD들과 데이터가 공유가 됩니다.
쿠버네티스는 마스터 노드에 내부적으로 API-SERVER를 가지고 있어 마스터 노드를 통해 워커 노드로 통신이 전달됩니다. 대량에 통신량이 발생하게 되면 마스터 노드는 부하를 많이 받아 장애 발생 가능성이 커지게 됩니다. 마스터 노드를 고가용성 클러스터로 연결하게 되면 통신량을 분산시킬 수 있고, 일부가 마스터 노드에서 장애가 발생시 워커 노드의 운영 시스템에는 영향을 줄일 수 있습니다.
최초 클러스터를 진행하게 되면 노드의 상태는 NotReady 입니다. 가상네트워크를 적용하게 되면 약 1 ~ 3분 소요되고 Ready 상태로 변경되게 됩니다. 이것으로 가상네트워크 적용이 완료 되었습니다.
$ kubectl get node
nginx 배포 해보기
nginx pod 3개를 배포하는 명령어입니다.
kubectl run --image=nginx --port 80 --replicas=3 nginx-app
아래 명령어를 통해 nginx-app 배포된 노드를 보면 node1 ~ 3 골고루 배포되어 있는걸 확인할 수 있습니다.
kubectl get pod -o wide
정리
이번에 쿠버네티스 고가용성 클러스터를 서버에 구축해보았습니다. 쿠버네티스 버전 1.6 이후 부터는 인증서배포 자동화, 클러스터 연결하는 방법이 간편하게 변경되었습니다. 이전 버전에서는 클러스터 구성하기위해선 복잡한 과정과 설정파일을 만들어야 했지만 이제는 간단하게 명령어 한줄만 입력하면 클러스터에 연결/해지를 하도록 변경되었습니다. 자유로운 노드 할당은 자원 낭비없이 효율적으로 관리하는데 장점이 될 것으로 보여집니다.