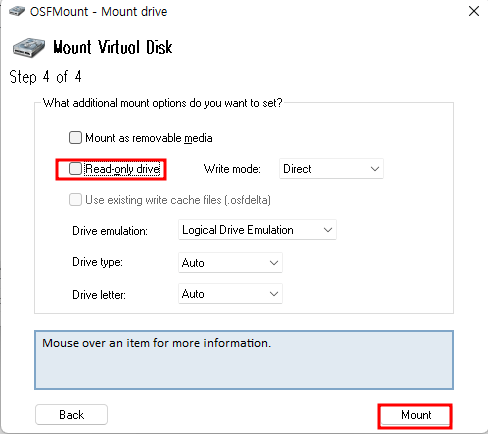
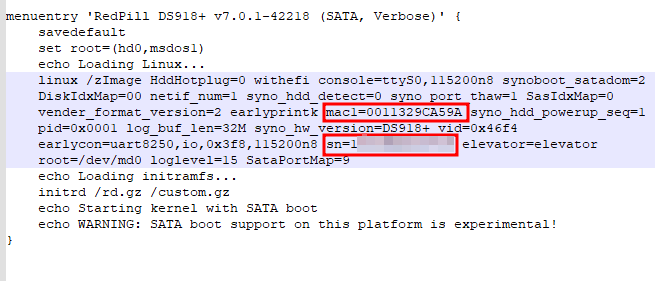
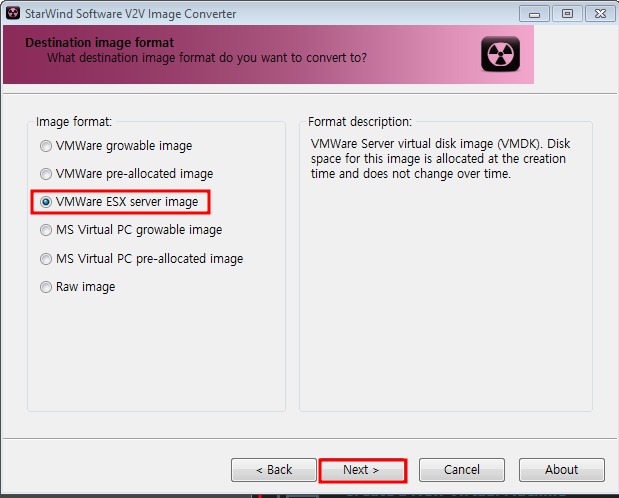
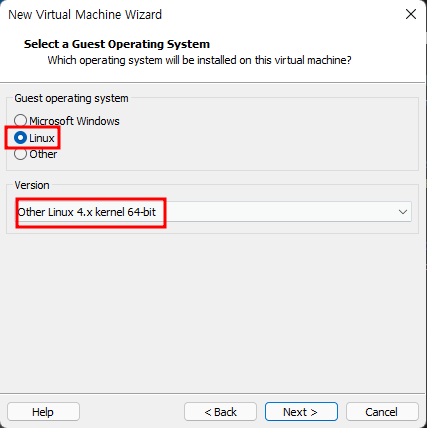
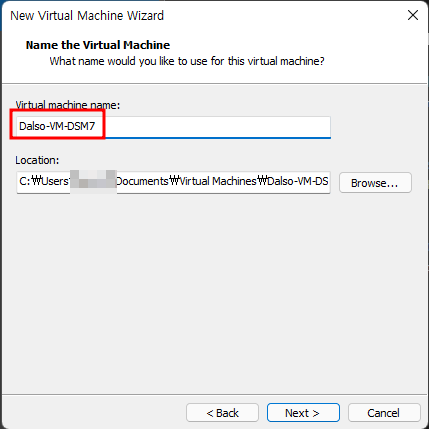
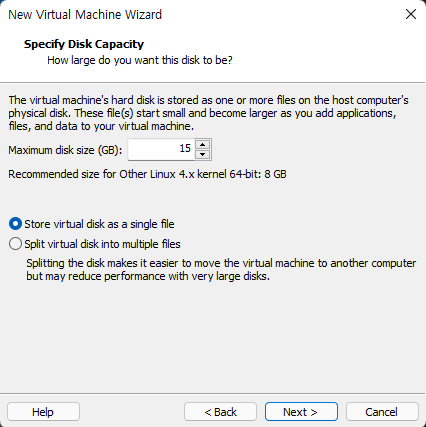
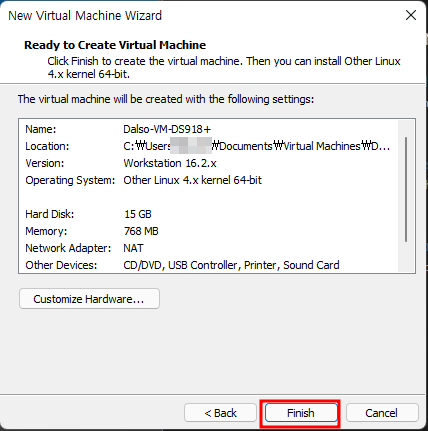
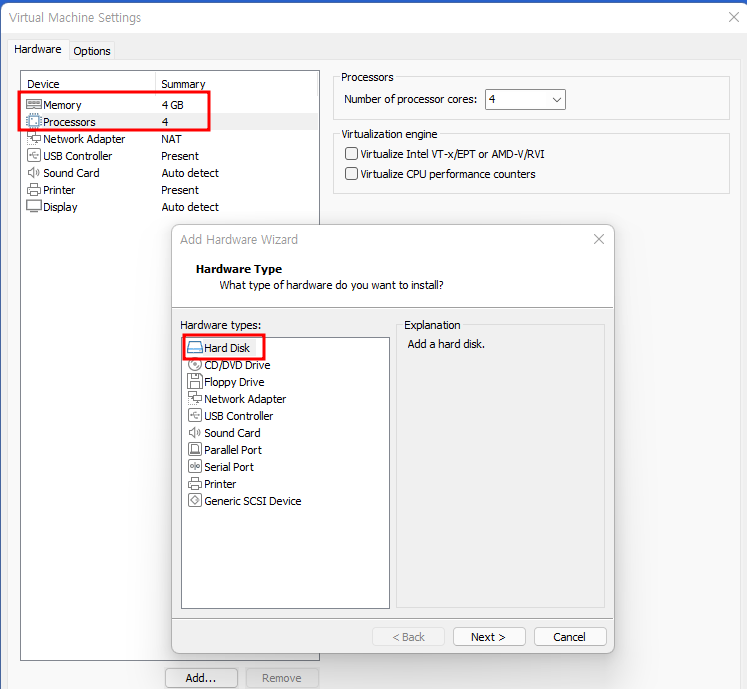
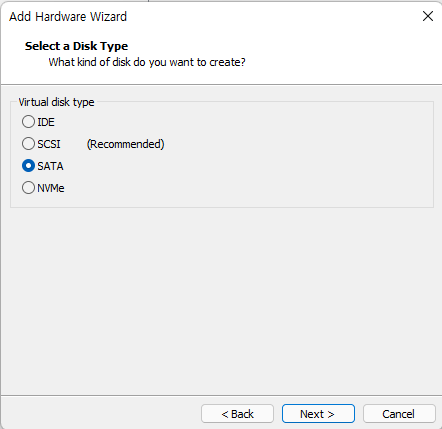
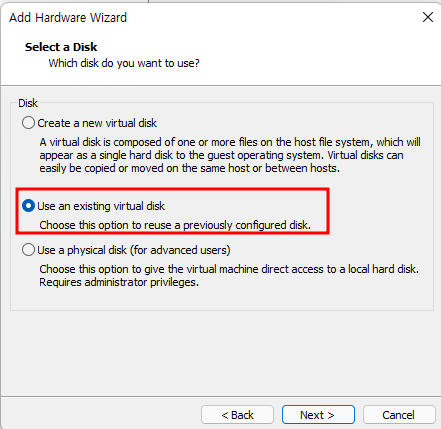
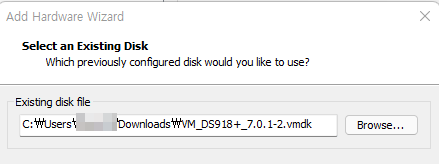
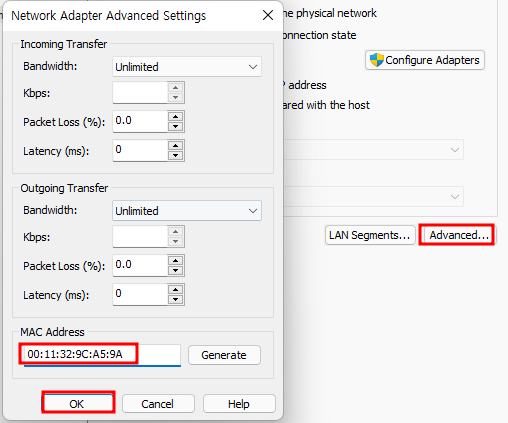
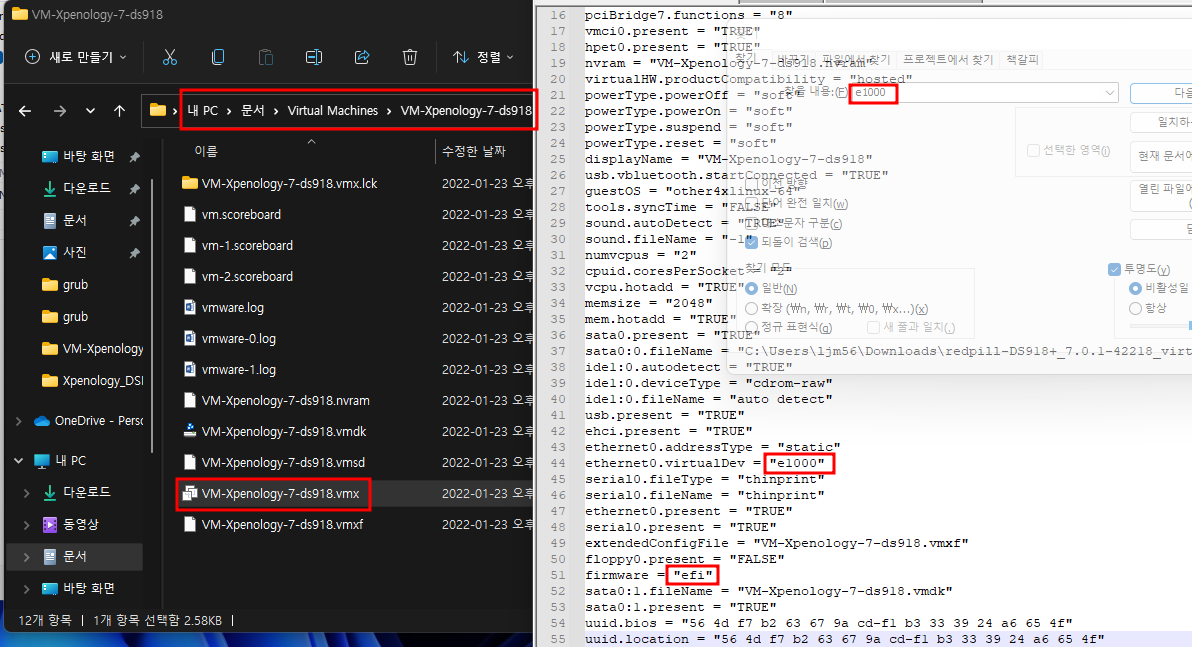
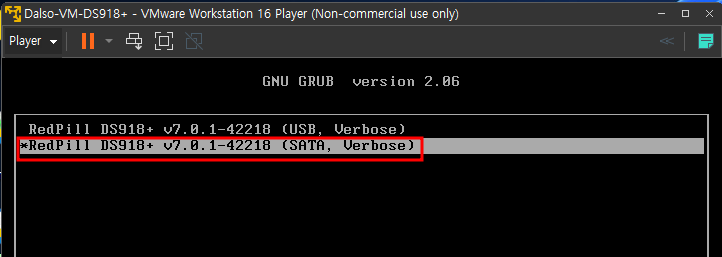
Windows OS에서 디스크 파티션을 조작할려면 [컴퓨터 관리]에 있는 [저장소] → [디스크 관리]를 사용하는 것이 일반적일 것입니다. 하지만 diskpart.exe라는 명령어를 이용해서도 똑같은 작업을 할 수 있습니다.
※ Diskpart는 파티션 작업 명령으로 데이터가 삭제되므로 중요 데이터 백업 및 확인후 사용토록 주의하시기 바랍니다.
Diskpart 란?
– Windows98이나 Windows ME에서 사용하던 Fdisk를 대체하는 파티션 툴로 동적 디스크를 지원하고, 디스크 관리 스냅인에서 지원하는 것보다 더 많은 작업을 수행할 수 있습니다. 디스크 관리 스냅인은 사용자가 실수로 데이터 손실을 초래할 수 있는 작업을 수행하지 못하도록 하지만, Diskpart를 사용하면 파티션과 볼륨을 명시적으로 제어할 수 있으며, 이런 기능 때문에 신중히 사용해 주셔야 합니다.
– 윈도우 XP, 2000, Vista, 7 이상 OS에서 사용 가능합니다. (위치 : C:\Windows\****32 폴더내 있습니다.)
Diskpart 사용 방법
1] Diskpart 모드 진입하기
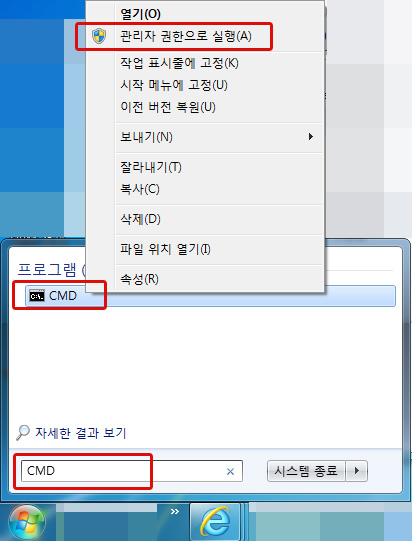
1. **** 모드로 CMD 콘솔 실행합니다.
방법 : 시작 > 프로그램 및 파일 검색(또는 Windows 검색) 창에 ‘CMD’ 입력 > CMD 항목에 마우스 오른쪽 버튼 클릭 후 ‘**** 권한으로 실행’ 선택
2. diskpart 입력 후 엔터를 칩니다.
3. DISKPART> 프롬프트 발생하면 이후 사용 가능합니다.
2] 디스크 초기화하기
Diskpart 모드 진입 상태에서 명령어를 이용하여 하드디스크의 파티션을 모두 초기화합니다.
1. list disk : 디스크목록 보기
2. select disk 1 : 초기화할 disk를 선택합니다. (“sel disk 1” 와 동일)
3. list partition : 파티션정보 확인 (“list part” 와 동일)
4. clean : 선택된 디스크의 파티션정보를 전부 초기화
5. list partition : 파티션 정보 사라짐 확인
※ 여기서 포커스란 개념이 나옵니다. select 명령을 이용해 작업하고자 하는 객체에 포커스를 주어야 합니다. select disk 1 이라고 주고 list disk 하자 disk 1 옆에 * 가 붙었습니다. 앞으로 disk 1 이 작업대상이 된 겁니다. (select disk=1이라고 해도 됩니다.)
120000M 크기(size=120000)의 주파티션(primary partition)을 만들라(create)는 명령입니다. size 지정을 안하게 되면 이용가능한 모든 용량을 잡습니다. 파티션을 1개만 잡을 때 또는 마지막 파티션을 잡을 때는 size 옵션을 생략하면 됩니다. 주파티션은 4개까지 만들 수 있고, 그 이상을 만들려면 주파티션 1개 대신 확장파티션을 잡아야 합니다. 즉, 최대 주파티션 3개 확장파티션 1개가 됩니다. 확장파티션은 디스크당 1개만 만들 수 있습니다. 확장파티션에서 원하는 개수만큼 논리드라이브를 만듭니다.
※ 확장 파티션 설정
create partition extended : 확장파티션(extended partition)을 만들라(create)는 의미입니다. size 지정이 없으면 disk의 남은 용량을 전부 이용합니다. 확장 파티션에서는 반드시 1개 이상의 논리드라이브를 지정해 주어야 합니다. create partition logical size = 250 라고 하면 250메가의 논리드라이브(partition logical)가 생성되고, create partition logical size = 100 하면 100메가의 논리드라이브(partition ligical)가 추가 생성됩니다. create partition logical 이라고만 하면 나머지 용량을 모두 잡습니다. list partition을 입력하면 선택한 디스크의 파티션 정보를 볼 수 있습니다.
※ create partition 이후 디스크 관리에서 디스크1의 파티션에 포맷과 드라이브 문자 할당이 안 되어 있습니다.
4] 파티션 포맷하기
분할된 파티션을 포맷합니다.
1. format fs=ntfs quick : 현재 선택되어 있는 파티션을 ntfs로 빠른 포맷한다.
2. list partition : 파티션 선택 확인
3. select partition 1 : 포맷할 파티션 선택
4. format fs=ntfs quick : 선택한 파티션을 ntfs로 빠른 포맷합니다.
※ 참고로 fs=fat32로 하면 FAT32로 포맷합니다. (단, 30GB 이하일 경우에만 진행해야 합니다.)
5. 디스크 관리에서 포맷 완료는 확인되나, 아직 드라이브 문자 할당은 안된 상태로 보이게 됩니다.
5] 파티션[드라이브] 문자 할당
분할된 파티션에 드라이브명을 할당합니다.
1. assign letter=x : 선택되어 있는 파티션에 X 드라이브명 할당
2. list partition : 선택된 파티션을 확인
3. select partition 2 : 문자를 할당할 파티션을 선택
4. assign letter=Z : 선택되어있는 파티션에 Z드라이브명 할당
5. 디스크1의 파티션에 드라이브명이 할당된 것을 확인할 수 있습니다.
※ assign letter=X 명령어에서, letter=X 옵션을 안쓰면 차례로 미사용 문자가 할당됩니다. list volume을 입력하면 선택한 디스크의 볼륨(드라이브명)을 확인할 수 있습니다.
6] 파티션 삭제하기
분할된 파티션을 삭제합니다.
1. 파티션 4,5,6(볼륨 3,4,5)에 각각 X:, Y:, Z: 가 할당된 파티션입니다.
2. 파티션을 삭제합니다. 볼륨으로 지정하는 경우 드라이브명이 지정되어 있다면, 드라이브명을 쓸 수 있습니다. 볼륨 번호랑 파티션 번호가 다르니 혼동하지 않도록 주의하세요.
select volume z 볼륨 z에 포커스를 맞춥니다. (select volume=z 도 같음 “=” 생략 가능)
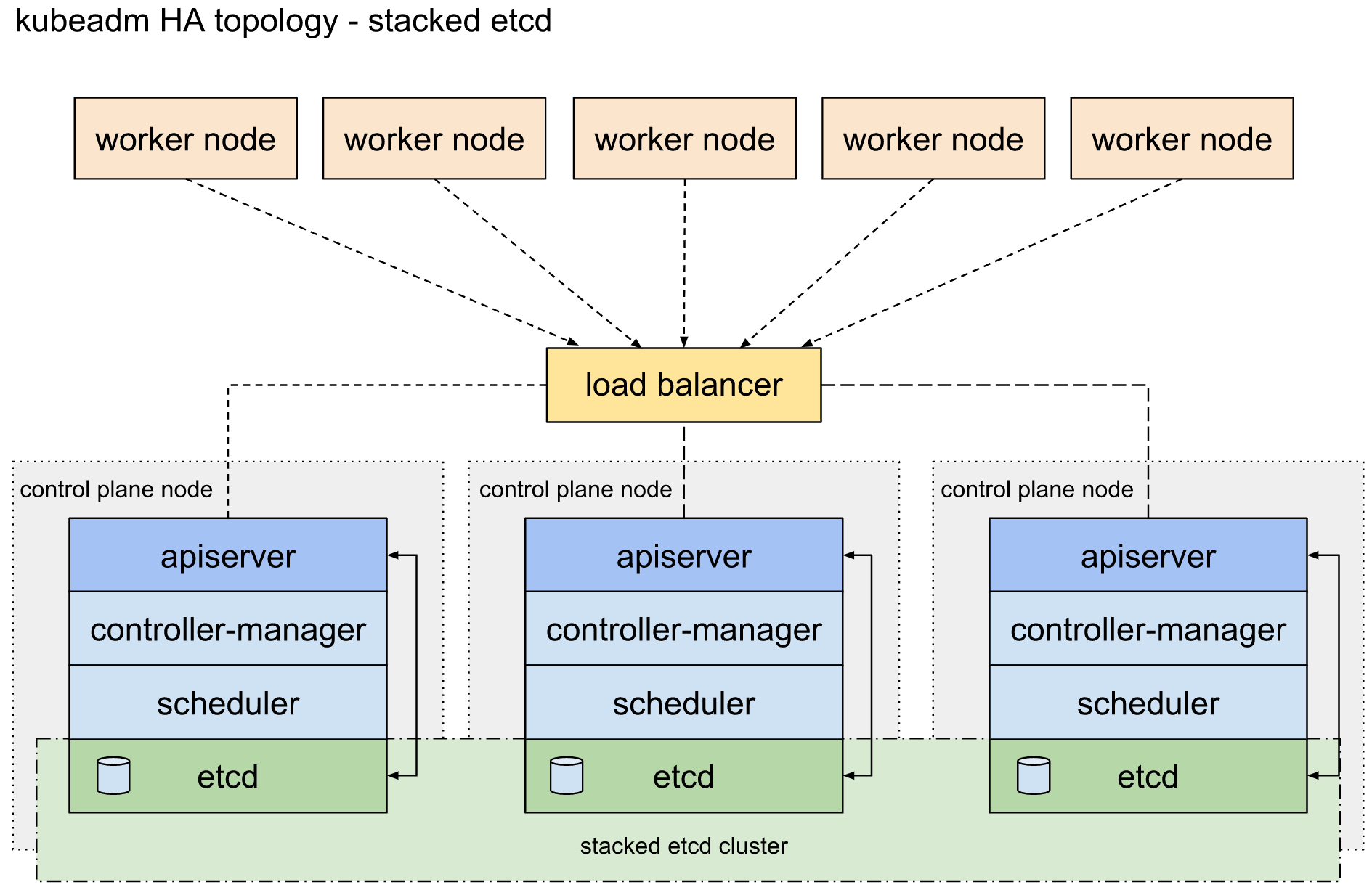
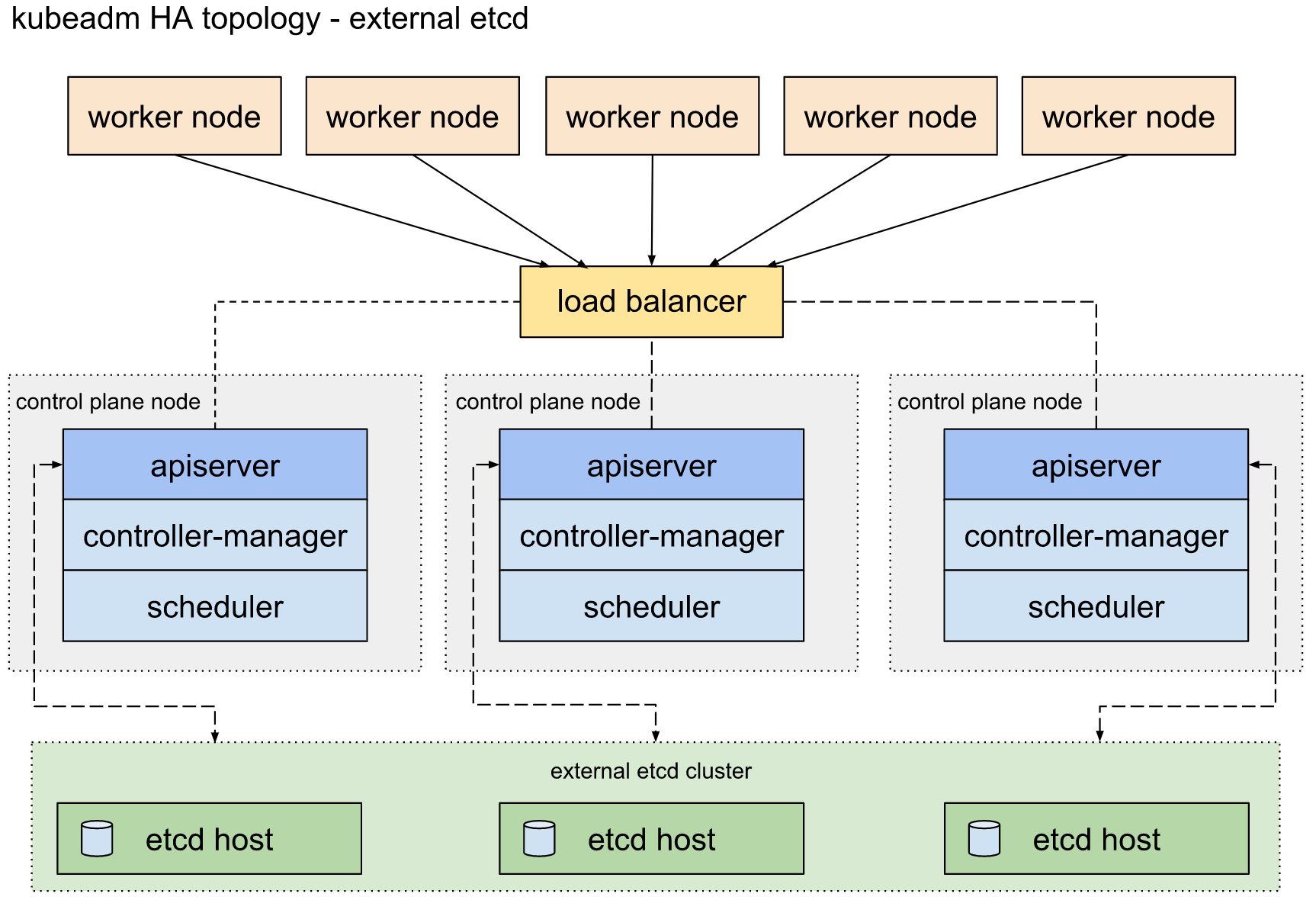
kubernetes에서 HA를 구성하는 방법으로 stacked etcd, external etcd 두가지 방법이 있다. 그림 1의 stacked etcd는 control plane node에서 etcd가 작동하는 반면, 그림 2의 external etcd는 control plane node와 etcd가 다른 노드에서 작동한다. HA를 구성하기 위해서는 쿼럼이 과반수를 초과해야만 하기 때문에 최소 3대 이상(3,5,7,…)의 노드를 필요로 한다. 이번 시간에는 stacked etcd 를 구성하는 방법에 대해 알아보고자 한다.
[그림 1] HA 토폴로지 – stacked etcd[그림 1] HA 토폴로지 – external etcd
구성환경
Ubuntu 18.04.1, Docker 19.03.8, Kubernet v1.17.4
사전 준비
Docker, Kubernet이 미리 설치 되어 있어야한다.
로드 발란서(Load Balancer)
– dns 로드 발란서 사용, apisvr 라운드로빈(round-robin) 활용, 참고로 도메인은 hoya.com
apisvr IN A 192.168.0.160
IN A 192.168.0.161
IN A 192.168.0.162
–upload-certs : control plane 인스턴스에서 공유해야 하는 인증서를 업로드(자동배포), 수동으로 인증서를 복사할 경우는 이 옵션 생략
control plane 초기화(kubeadm init)를 진행하면 아래와 같은 내용이 출력될 것이다. 아래 내용을 복사해 놓도록 한다. 이 명령어를 이용하여 클러스터에 조인(join) 할수 있다. 파란색글씨(위쪽)는 control plane 노드에서 실행, 주황색 글씨(아래)는 worker node에서 실행
You can now join any number of control-plane node by running the following command on each as a root:
kubeadm join apisvr.hoya.com:6443 –token 9vr73a.a8uxyaju799qwdjv –discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866 –control-plane –certificate-key f8902e114ef118304e561c3ecd4d0b543adc226b7a07f675f56564185ffe0c07Please note that the certificate-key gives access to cluster sensitive data, keep it secret!
As a safeguard, uploaded-certs will be deleted in two hours; If necessary, you can use kubeadm init phase upload-certs to reload certs afterward.
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join apisvr.hoya.com:6443 –token 9vr73a.a8uxyaju799qwdjv –discovery-token-ca-cert-hash sha256:7c2e69131a36ae2a042a339b33381c6d0d43887e2de83720eff5359e26aec866
참고: 인증서를 다시 업로드하고 새 암호 해독 키를 생성하려면 이미 클러스터에 연결된 control plane 노드에서 다음 명령을 사용하십시오.
shell> sudo kubeadm init phase upload-certs –upload-certs
W0322 16:20:40.631234 101997 validation.go:28] Cannot validate kube-proxy config – no validator is available
W0322 16:20:40.631413 101997 validation.go:28] Cannot validate kubelet config – no validator is available
[upload-certs] Storing the certificates in Secret “kubeadm-certs” in the “kube-system” Namespace
[upload-certs] Using certificate key:
7f97aaa65bfec1f039c4dbdf3a2073de853c708bd4d9ff9d72b776b0f9874c9d
참고 : 클러스터를 control plane 조인(join)하는 데 필요한 전체 ‘kubeadm join’ 플래그를 출력
shell> kubectl get nodes
NAME STATUS ROLES AGE VERSION
master1 Ready master 41s v1.17.4
master2 Ready master 3m59s v1.17.4
master3 Ready master 92s v1.17.4
shell>
** kubectl delete node로 control plane노드 를 제거하지 않도록 한다. 만약 kubectl delete node로 삭제하는 경우 이후 추가 되는 control plane 노드들은 HA에 추가 될수 없다. 그 이유는 kubeadm reset은 HA내 다른 control plane 노드의 etcd에서 etcd endpoint 정보를 지우지만 kubectl delete node는 HA 내의 다른 controle plane 노드에서 etcd endpoint 정보를 지우지 못하기 때문이다. 이로 인해 이후 HA에 추가되는 control plane 노드는 삭제된 노드의 etcd endpoint 접속이 되지 않기 때문에 etcd 유효성 검사 과정에서 오류가 발생하게 된다.
– control plane 노드를 kubectl delete node 로 삭제후 control plane 노드 추가시 오류 메시지
shell> kubeadm join ….. –control-plane –certyficate-key
… 생략 …
[check-etcd] Checking that the etcd cluster is healthy
error execution phase check-etcd: etcd cluster is not healthy: failed to dial endpoint https://192.168.0.159:2379 with maintenance client: context deadline exceeded
To see the stack trace of this error execute with –v=5 or higher
$ ls
config.yml dashboard docker-compose.yml registry-data stack
docker-compose up을 실행하면 위처럼 registry-data와 stack 디렉토리가 생기는걸 확인할 수 있다. registry-data 디렉토리를 registry 서비스의 /var/lib/registry 디렉토리와 마운트 시켜놓으면, registry 서비스가 중지되어도 데이터가 그대로 유지된다.
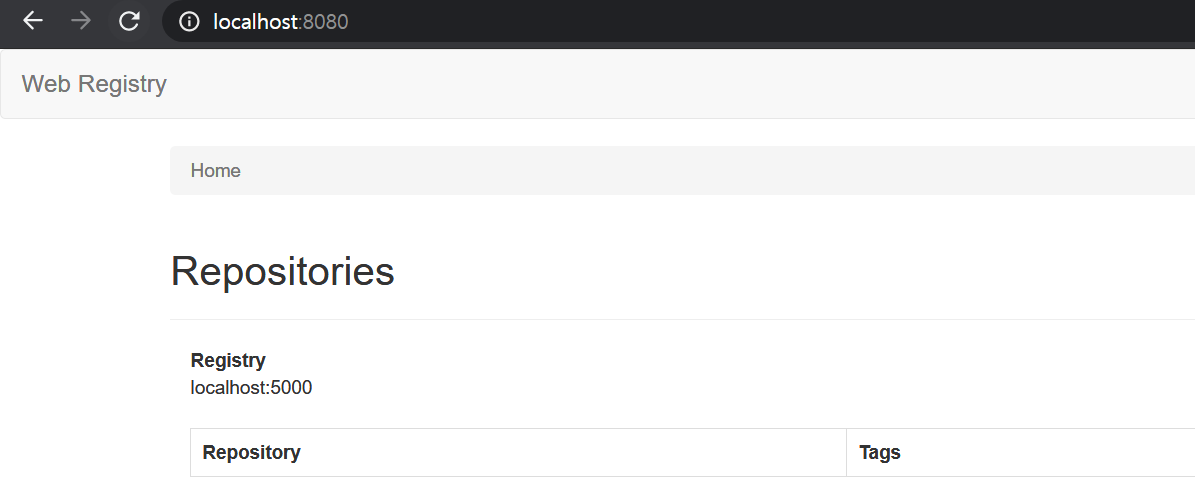
– localhost:8080 접속
registry-web 접속
registry-web에 접속하면, 현재 registry 상태를 web UI를 통해 확인할 수 있다.
private registry에 이미지 업로드
docker swarm service에 사용할 이미지를 다운로드 받고, 직접 private registry에 이미지를 업로드 해본다.
– docker pull
$ docker image pull subicura/whoami:1
위의 이미지를 받는다. 브라우저로 접속하면 hostname을 출력해주는 docker 이미지이다.
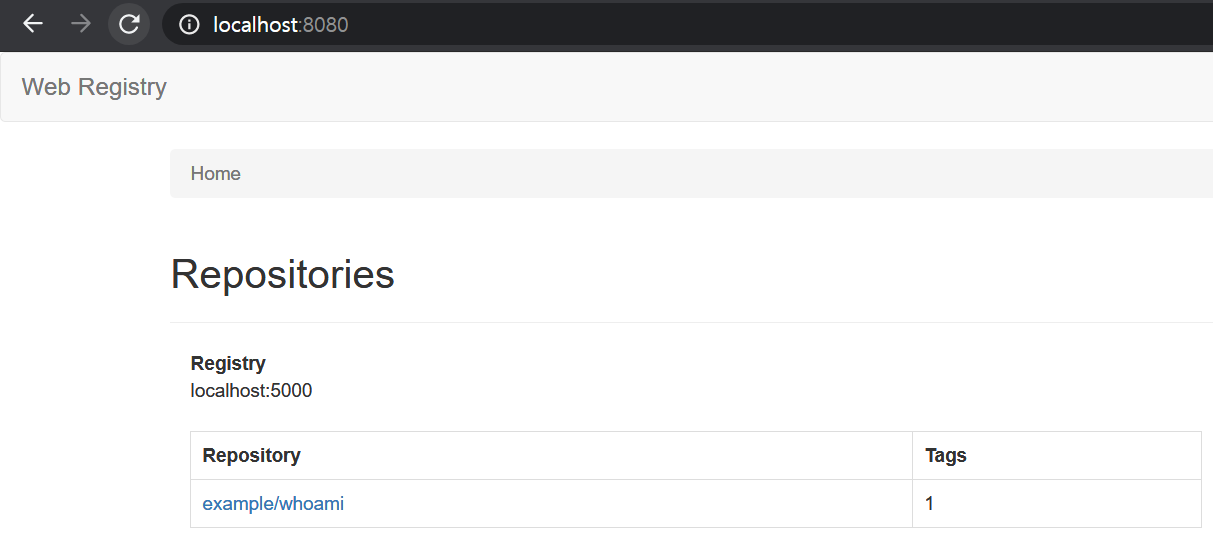
– docker tag
$ docker image tag subicura/whoami:1 localhost:5000/example/whoami:latest
private registry의 포트가 5000이므로, 위와같이 docker image tag 명령어를 통해 이미지 이름과 tag 정보를 변경한다. 이미지의 첫 항목이 image pull 진행 시, 이미지가 올라가는 도메인 정보이다.
이미지가 올라간것을 확인할 수 있다. 이제 docker swarm 노드에서 이미지를 다운받아 사용할 수 있다.
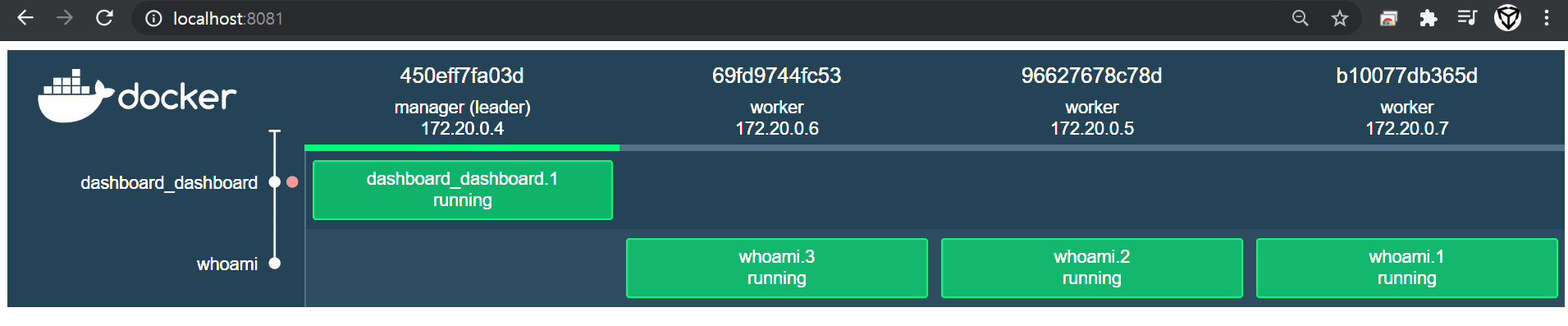
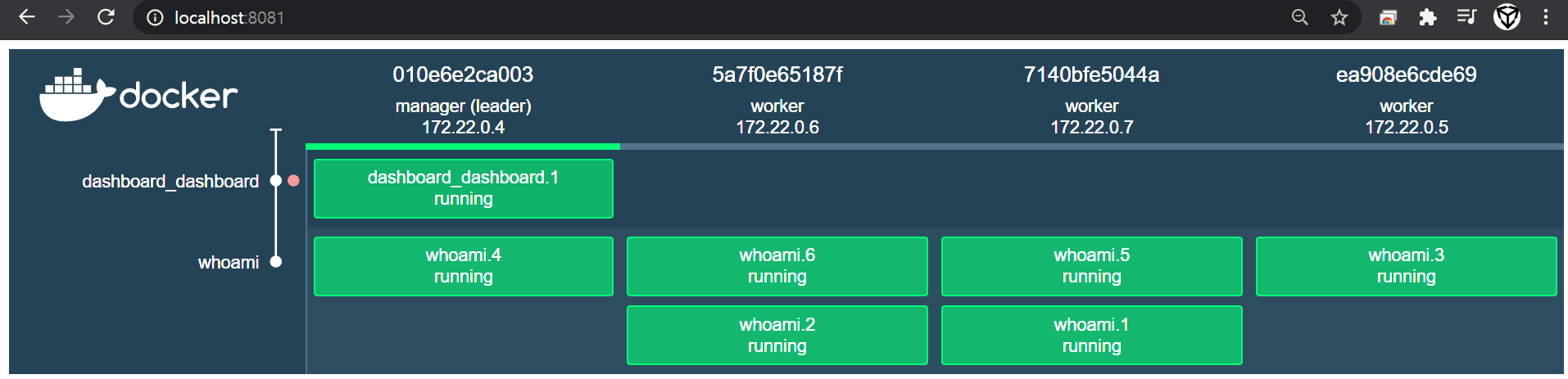
docker swarm 구성하기
– docker swarm init
$ docker exec -it manager docker swarm init
Swarm initialized: current node (5ywj85cw3tdz8ioe71v1xlyzn) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-1gxj86agzmecefcd6mwjproa96hw7e3gu0plsdhuw9110fuc1r-7q4434lsegri8la2n9qgggsrd 172.22.0.4:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
manager 컨테이너에서 docker swarm init 명령어를 입력한다. 위처럼 docker swarm join 부분 전체를 복사한다. worker 노드들에서 전부 입력하면 된다.
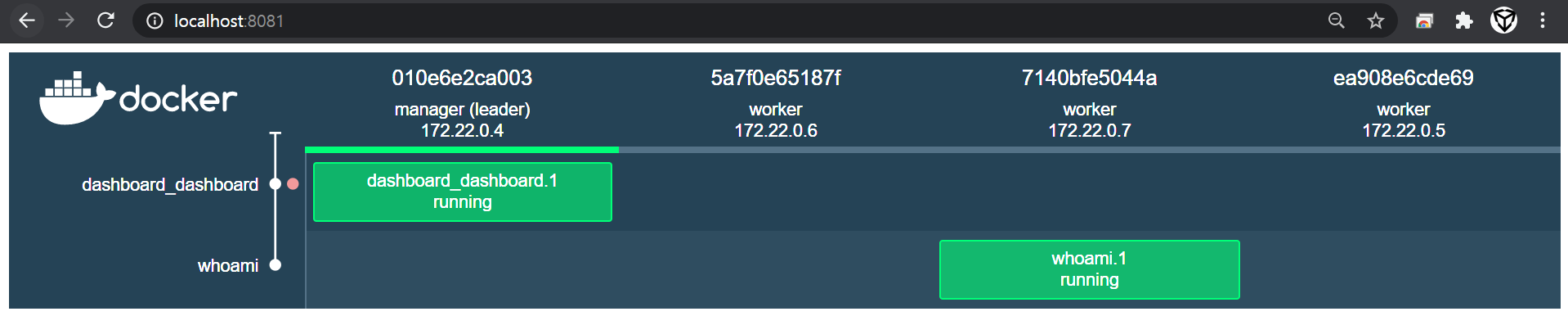
– docker swarm join
$ docker exec -it worker01 docker swarm join --token SWMTKN-1-1gxj86agzmecefcd6mwjproa96hw7e3gu0plsdhuw9110fuc1r-7q4434lsegri8la2n9qgggsrd 172.22.0.4:2377
This node joined a swarm as a worker.
$ docker exec -it worker02 docker swarm join --token SWMTKN-1-1gxj86agzmecefcd6mwjproa96hw7e3gu0plsdhuw9110fuc1r-7q4434lsegri8la2n9qgggsrd 172.22.0.4:2377
This node joined a swarm as a worker.
$ docker exec -it worker03 docker swarm join --token SWMTKN-1-1gxj86agzmecefcd6mwjproa96hw7e3gu0plsdhuw9110fuc1r-7q4434lsegri8la2n9qgggsrd 172.22.0.4:2377
This node joined a swarm as a worker.
Kubernetes는 온프레미스 서버 또는 하이브리드 클라우드 환경에서 대규모로 컨테이너화된 애플리케이션을 오케스트레이션 및 관리하기 위한 도구입니다. Kubeadm은 사용자가 모범 사례 시행을 통해 프로덕션 준비 Kubernetes 클러스터를 설치할 수 있도록 Kubernetes와 함께 제공되는 도구입니다. 이 튜토리얼은 kubeadm을 사용하여 Ubuntu 20.04에 Kubernetes 클러스터를 설치하는 방법을 보여줍니다.
Kubernetes 클러스터 배포에는 두 가지 서버 유형이 사용됩니다.
마스터 : Kubernetes 마스터는 Kubernetes 클러스터의 포드, 복제 컨트롤러, 서비스, 노드 및 기타 구성 요소에 대한 제어 API 호출이 실행되는 곳입니다.
Node : Node는 컨테이너에 런타임 환경을 제공하는 시스템입니다. 컨테이너 포드 세트는 여러 노드에 걸쳐 있을 수 있습니다.
실행 가능한 설정을 위한 최소 요구 사항은 다음과 같습니다.
메모리: 컴퓨터당 2GiB 이상의 RAM
CPU: 컨트롤 플레인 머신에 최소 2개의 CPU 가 있습니다.
컨테이너 풀링을 위한 인터넷 연결 필요(개인 레지스트리도 사용할 수 있음)
클러스터의 머신 간 전체 네트워크 연결 – 개인 또는 공용입니다.
Ubuntu 20.04에 Kubernetes 클러스터 설치
My Lab 설정에는 3개의 서버가 있습니다. 컨테이너화된 워크로드를 실행하는 데 사용할 하나의 컨트롤 플레인 머신과 두 개의 노드. 예를 들어 HA용 제어 평면 노드 3개 를 사용하여 원하는 사용 사례 및 부하에 맞게 노드를 더 추가할 수 있습니다 .
서버 유형
서버 호스트 이름
명세서
주인
k8s-master01.computingforgeeks.com
4GB 램, 2vcpus
노동자
k8s-worker01.computingforgeeks.com
4GB 램, 2vcpus
노동자
k8s-worker02.computingforgeeks.com
4GB 램, 2vcpus
1단계: Kubernetes 서버 설치
Ubuntu 20.04에서 Kubernetes 배포에 사용할 서버를 프로비저닝합니다. 설정 프로세스는 사용 중인 가상화 또는 클라우드 환경에 따라 다릅니다.
systemd cgroup 드라이버를 사용하려면 에서 plugins.cri.systemd_cgroup = true 를 설정 /etc/containerd/config.toml하십시오. kubeadm을 사용할 때 kubelet 용 cgroup 드라이버를 수동으로 구성하십시오.
--control-plane-endpoint : 모든 제어 평면 노드에 대한 공유 끝점을 설정합니다. DNS/IP일 수 있음
--pod-network-cidr : 포드 네트워크 추가 기능을 설정하는 데 사용됨 CIDR
--cri-socket : 런타임 소켓 경로를 설정하기 위해 컨테이너 런타임이 둘 이상인 경우 사용
--apiserver-advertise-address : 이 특정 제어 평면 노드의 API 서버에 대한 광고 주소 설정
....
[init] Using Kubernetes version: v1.22.2
[preflight] Running pre-flight checks
[WARNING Firewalld]: firewalld is active, please ensure ports [6443 10250] are open or your cluster may not function correctly
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Using existing ca certificate authority
[certs] Using existing apiserver certificate and key on disk
[certs] Using existing apiserver-kubelet-client certificate and key on disk
[certs] Using existing front-proxy-ca certificate authority
[certs] Using existing front-proxy-client certificate and key on disk
[certs] Using existing etcd/ca certificate authority
[certs] Using existing etcd/server certificate and key on disk
[certs] Using existing etcd/peer certificate and key on disk
[certs] Using existing etcd/healthcheck-client certificate and key on disk
[certs] Using existing apiserver-etcd-client certificate and key on disk
[certs] Using the existing "sa" key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/admin.conf"
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/kubelet.conf"
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/controller-manager.conf"
[kubeconfig] Using existing kubeconfig file: "/etc/kubernetes/scheduler.conf"
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0611 22:34:23.276374 4726 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0611 22:34:23.278380 4726 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 8.008181 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.21" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node k8s-master01.computingforgeeks.com as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node k8s-master01.computingforgeeks.com as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: zoy8cq.6v349sx9ass8dzyj
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
You can now join any number of control-plane nodes by copying certificate authorities
and service account keys on each node and then running the following as root:
kubeadm join k8s-cluster.computingforgeeks.com:6443 --token sr4l2l.2kvot0pfalh5o4ik \
--discovery-token-ca-cert-hash sha256:c692fb047e15883b575bd6710779dc2c5af8073f7cab460abd181fd3ddb29a18 \
--control-plane
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join k8s-cluster.computingforgeeks.com:6443 --token sr4l2l.2kvot0pfalh5o4ik \
--discovery-token-ca-cert-hash sha256:c692fb047e15883b575bd6710779dc2c5af8073f7cab460abd181fd3ddb29a18
$ kubectl cluster-info
Kubernetes master is running at https://k8s-cluster.computingforgeeks.com:6443
KubeDNS is running at https://k8s-cluster.computingforgeeks.com:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/bgppeers.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/blockaffinities.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/clusterinformations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/felixconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/globalnetworksets.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/hostendpoints.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamblocks.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamconfigs.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ipamhandles.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/ippools.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/kubecontrollersconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networkpolicies.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/networksets.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/apiservers.operator.tigera.io created
customresourcedefinition.apiextensions.k8s.io/imagesets.operator.tigera.io created
customresourcedefinition.apiextensions.k8s.io/installations.operator.tigera.io created
customresourcedefinition.apiextensions.k8s.io/tigerastatuses.operator.tigera.io created
namespace/tigera-operator created
Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
podsecuritypolicy.policy/tigera-operator created
serviceaccount/tigera-operator created
clusterrole.rbac.authorization.k8s.io/tigera-operator created
clusterrolebinding.rbac.authorization.k8s.io/tigera-operator created
deployment.apps/tigera-operator created
.....
installation.operator.tigera.io/default created
apiserver.operator.tigera.io/default created
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.21" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
제어 플레인에서 아래 명령을 실행하여 노드가 클러스터에 합류했는지 확인합니다.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01.computingforgeeks.com Ready master 10m v1.22.2
k8s-worker01.computingforgeeks.com Ready <none> 50s v1.22.2
k8s-worker02.computingforgeeks.com Ready <none> 12s v1.22.2
$ kubectl get nodes -o wide
Prometheus는 Kubernetes 클러스터의 고급 메트릭 기능에 액세스할 수 있는 완전한 솔루션입니다. Grafana는 Prometheus 데이터베이스에 수집 및 저장되는 메트릭의 분석 및 대화형 시각화에 사용됩니다. Kubernetes 클러스터에서 전체 모니터링 스택을 설정하는 방법에 대한 완전한 가이드가 있습니다.
이 글에서는 기본적인 Docker Registry 설치법에 대해 다룰 것이다. 정말 자세한 내용은 공식 홈페이지를 참조하면 된다. Docker Registry란 Docker Image를 관리하는 Docker Hub 같은 Respository를 말한다. 개별적으로 Docker Image를 관리 할 일이 생기면 필수라고 생각된다. Docker Registry를 설치하기 위해서, docker와 docker-compose가 필요하다. 설치는 아래 글을 참고하자.
간단한 설치
공식홈페이지에 보면 아래처럼 단 한 줄로 Registry를 설치 할 수 있다고 나와있다.
$ docker run -d -p 5000:5000 registry:2.6$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
860c11dc6921 registry:2.6 "/entrypoint.sh /e..." 48 seconds ago Up 47 seconds 0.0.0.0:5000->5000/tcp brave_ptolemy
기본 설정대로 사용하면 제약사항이 너무 많다. 꼭 필요하다고 생각되는 부분만 변경해보도록 하겠다.
log
로그는 공식 홈페이지를 보고 입맛에 맞게 설정하면 된다. 지금 단계에서 크게 중요하지 않다.
storage
기본 설정대로면 container안에 디스크에 Docker Image가 저장된다. 이렇게되면 docker registry가 삭제되면 데이터가 같이 날아가게되므로, 설정은 그대로 두고 host에 있는 디렉토리를 mount 해줄 필요가 있다. 혹은 cloud storage를 사용하면 좋은데 대표적인 예로 AWS S3가 있다. 다른 옵션을 더 보고싶으면 공식 홈페이지 문서를 참고하자.
기본 설정대로면 캐쉬를 메모리에 하도록 되어있다. 이는 쓸데 없이 메모리를 사용하게 된다고 생각이 되는데, 다른 옵션으로 redis를 사용 할 수 있다. 캐쉬를 redis로 사용하기 위해서는 redis를 실행하고 설정을 따로 해줘야하는데, redis image를 사용하도록하자.
storage 부분이 redis 설정까지 추가해 이렇게 변경된다. redis addr에 redis:6379를 쓴 것은 redis를 docker container로 실행하고 link로 연결해 줄 것이기 때문이다.
기본 설정대로면 Docker Registry에 접근하기 위해서 그 어떤 인증도 필요하지 않다. Docker Registry V2부터 3rd party 인증시스템을 도입 할 수 있도록 JWT Token Base 인증 서버를 별도로 구현 할 수 있다. 이 부분은 여기서 함께 다루기엔 너무 복잡하므로 상대적으로 간단한 Basic Authorization을 이용하여 인증 시스템을 설정해보도록 하자.
설정을 살펴보면 realm, path를 지정하도록 되어있다. realm은 원하는 값을 넣어주고 path에는 .htpasswd 파일 경로를 넣어준다. docker registry에서 사용 할 .htpasswd 파일은 아래 명령어를 이용해 만들 수 있다. 아이디가 admin, 비밀번호가 1234인 경우이다.
자세히 하려면 봐야 할 설정이 더 있겠지만, 정말 기본적인 설정은 끝났다. 이제 docker-compose.yml을 작성하고 디플로이를 하자.
version:3services:registry:image:registry:2.6volumes:
- /var/lib/registry:/var/lib/registry# host filesystem을 mount
- ./config.yml:/etc/docker/registry/config.yml:ro # 설정 파일 변경
- ./.htpasswd:/etc/docker/registry/.htpasswd:ro # htpasswd mountlinks:
- redis:redis # cache에 사용 할 redis container 연결ports:
- 5000:5000# 5000번을 이용해 통신depends_on:
- redis # redis가 실행된 후, registry가 실행된다.redis:image:redis:3.0.7