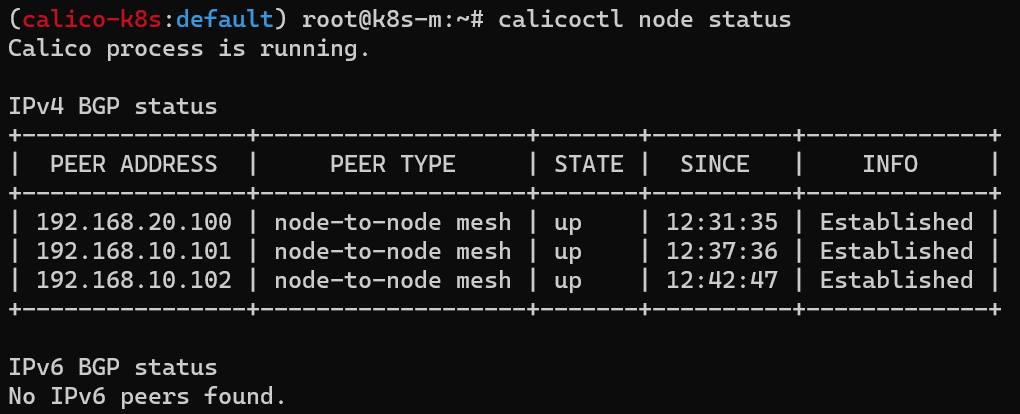
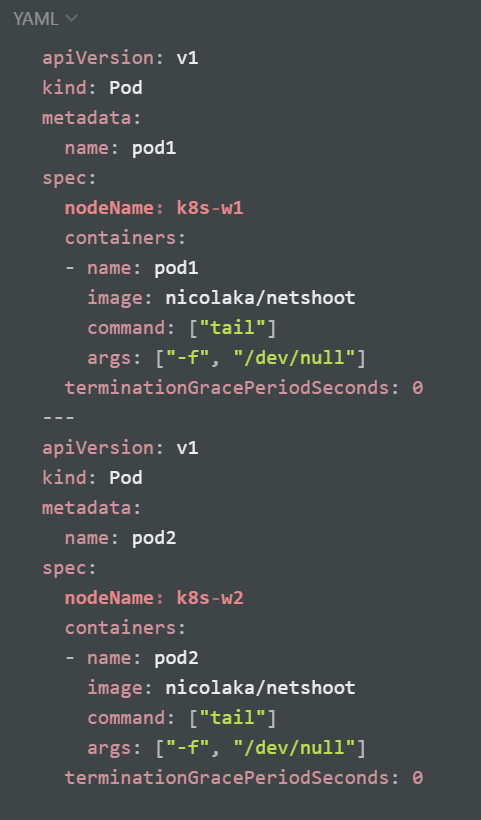
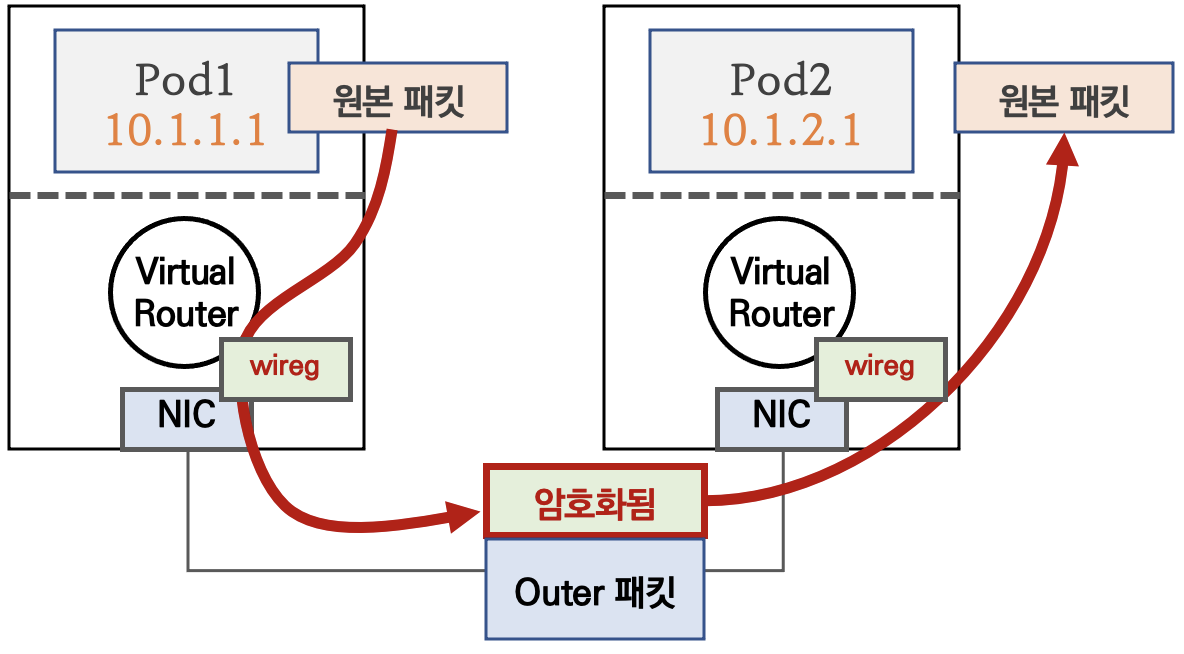
작업스케줄러(schtasks)를 cmd로 입력하는 방법
Microsoft Docs Windows 2008 server , Windows command help, etc / schtasks
▣ 시간 단위 작업
30분마다 실행되는 작업
schtasks /create /tn “back up” /tr \\data\task01.bat /sc minute /mo 30
참고 : /sc minute인 경우 /mo의 유효값은 1-1439분이다.
매일 오전 9시부터 18시이전까지 60분마다 실행되는 작업
schtasks /create /tn “back up” /tr task01.bat /sc minute /mo 60 /st 09:00 /et 18:00 /k
참고 : /k는 /et 또는 /du 시간이 되면 작업을 중지한다.
/k는 onstart, onlogon, onidle, onevent는 해당되지 않는다.
2018년 6월 1일부터 12시간단위마다 실행되는 작업
schtasks /create /tn check /tr %userprofile%\desktop\schedule.txt /sc hourly /mo 12 /sd 2018/06/01
참고 : /sc hourly인 경우 /mo의 유효값은 1-23시간이다.
/sd : startdate는 yyyy/mm/dd의 한국 날짜 형식이다.
매 시간 50분에 실행되는 작업
schtasks /create /tn “My Schedule” /tr MySchedule.txt /sc hourly /st 00:50
참고 : /hourly에서 /mo가 생략 되면 기본값은 1이다.
명령입력 현재시간이 00:53분이었다면 다음날에 00:50에 명령이 실행된다.
3시간 간격으로 자정부터 10시간 동안 반복 작업
schtasks /create /tn “My Program” /tr “C:\Program\MyProgram.exe” /sc hourly /mo 3 /st 00:00 /du 0010:00
참고 : 오전 12시, 오전 3시, 오전 6시 , 오전9시에 실행된다. 지속시간이 10시간이므로 오후 12시에는
실행되지 않고 다음날 오전 12시에 실행된다.
/k를 사용하여 작업시간 이후에 중지 할 수 있으나 지속시간이 길지 않으면 굳이 중지할 필요가 없다.
▣ 일 단위 작업
매일 오전 9시에 2020년 12월 31일까지 실행되는 작업
schtasks /create /tn “My Program” /tr C:\Program\MyProgram.exe /sc daily /st 09:00 /ed 2020/12/31
참고 : /sc daily인 경우 /mo가 생략되면 기본값은 1이다. /sc daily에서 /mo의 유효값은 1-365일이다.
2018년 6월 1일부터 5일마다 오후 6시에 실행되는 작업
schtasks /create /tn “My Program” /tr C:\Program\MyProgram.exe /sc daily /mo 5 /sd 2018/06/01 /st 18:00
사용자가 로그온 되어 있을때 10일마다 실행되는 대화형 작업
schtasks /create /tn “My Script” /tr MyScript.vbs /sc daily /mo 10 /it
참고 : “다음 사용자계정으로 실행”되는 (RU)계정으로 로그온 되어 있는 있을때만 실행 (/it)
▣ 주 단위 작업
6주마다 실행되는 작업
schtasks /create /tn “My Program” /tr c:\programs\myprogram.exe /sc weekly /mo 6 /s Server03 /u Administrator1
참고 : /sc weekly /mo의 기본값은 1(주)이다. /sc weekly에서 /mo의 유효값은 1-52주이다.
/d day 매개변수가 생략되면 월요일부터 실행
/s 연결할 원격시스템 지정
/u 사용자의 관리자계정 권한을 지닌 Adiministrator1 계정으로 지정
격주마다 월요일에 실행되는 작업
schtasks /create /tn “My prog” /tr c:\prg\myprog.exe /sc weekly /mo 2 /d MON
참고 : /mo 2 격주 간격
/sc weekly /d 매개변수의 유효값은 MON, TUE, WED, THU, FRI, SAT, SUN
▣ 월 단위 작업
매달 1일에 실행되는 작업
schtasks /create /tn “My Prg” /tr myprg.exe /sc monthly
참고 : /sc monthly 에서 /d 매개변수의 유효값은 1-31일이다. /d 매개변수가 생략되면 기본값 1이 적용된다.
/sc monthly에서 /mo 매개변수의 유효값은 1-12 또는 First, Second, Third, Fourth, Last, Lastday이다.
/mo 매개변수가 생략되면 기본값 1이 적용된다.
3개월마다 1번씩 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly /mo 3
참고 : 3월 ,6월, 9월, 12월 에 1번씩 1일에 작업실행
/d 매개변수가 생략되었으므로 기본값 1일이 적용된다.
격월의 25일에 09:00시간에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly /mo 2 /d 25 /st 09:00 /sd 2018/06/01 /ed 2025/05/31
참고 : /sc monthly에서 /mo 매개변수가 2이므로 격월로 작업실행
/d 25 25일에 작업 실행
/sd는 start date, /ed는 end date를 지정
/et가 생략되면 시작시간과 상관없이 00:00이 기본값이다.
▣ 요일 단위 작업
매주 월요일부터 금요일에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc weekly /d MON,TUE,WED,THU,FRI
매주 금요일에 실행 되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc weekly /d FRI
참고 : /se weekly에서 /mo는 작업을 실행할 간격(주)이며 생략되면 기본값 1이므로 매주 작업 실행
/d *(와일드카드) 는 일일작업실행의 의미와 같다.
4주마다 월요일과 금요일에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc weekly /mo 4 /d MON,FRI
▣ 한달 중 특정 주 단위 작업
매월 셋째주 월요일에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly /mo Third /d MON
참고 : /sc monthly에서 /mo 매개변수를 1~12 또는 First, Second, Third, Fourth를 선택할 수 있다.
예를 들어 /mo 2 이면 격월이란 의미로 2,4,6,8,10,12월에 해당되고 /d 매개변수는 1~31일까지
지정이 가능하다.
반면에 /mo SECOND로 지정하면 둘째주라는 의미이며 /d 매개변수는 MON, TUE, WED, THU,
FRI, SAT, SUN로 지정이 가능하다.
/sc /monthly /mo last /d sat : 매월 마지막 토요일
– /mo last 에는 /d 매개변수가 반드시 필요하며 /d 매개변수에는 1~31이 아닌 MON, TUE, WED,
THU, FRI, SAT, SUN로 지정해야 한다.
/sc /monthly /mo lastday /m Jan, Feb 1월 2월 마지막 일
– /mo lastday에는 /m 매개변수가 반드시 필요하며 유효값에는 JAN, FEB, MAR, APR, MAY,
JUN, JUL, AUG, SEP, OCT, NOV, DEC. 와일드카드 “*”가 있다.
1월과 7월의 첫번째 월요일에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly /mo FIRST /d MON /m JAN,JUL
참고 : /sc monthly에서 /m이 생략되면 매월 실행
▣ 특정 일 단위 작업
매월 1일에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly
참고 : /sc monthly에서 /m이 없으면 매월 실행, /d가 없으면 기본값은 1이다.
6월 1일과 7월 1일 오후 6시에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly /d 1 /m JUN,JUL /st 18:00
매월 말일에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly /mo lastday /m *
참고 : /sc monthly /mo lastday에서는 반드시 /m 매개변수가 필요하다.
5,6,7월의 마지막 일 18:00에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly /mo lastday /m MAY,JUN, JUL /st 18:00
▣ 한번만 필요한 작업
한번 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc once /sd 2018/06/01 /st 00:00
참고 : 한번만 실행되는 작업의 /sc 매개변수는 once이다.
/sd 매개변수는 선택사항이며 /st 매개변수는 필수사항이다.
▣ 시스템이 시작될 때 작업
시스템이 시작 될때 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc onstart /sd 2018/05/13
참고 : 시스템이 시작할 때 실행되는 작업의 /sc 매개변수는 onstart이다.
/sd 매개변수는 선택사항이며 기본값은 현재 날짜이다.
▣ 로그온 할 때 작업
로그온 할 때 실행 되는 작업
schtasks /create /tn “Virus Check3” /tr “cmd /k cd \”c:\Program Files\Windows Defender\” & MpCmdRun.exe -Scan -scantype 2″ /sc onlogon
참고 : 로그온 할 때 실행되는 작업의 /sc 매개변수는 onlogon이다.
/sd 매개변수는 선택사항이며 기본값은 현재 날짜이다.
/s 매개변수는 연결할 원격시스템이며 생략되면 로컬시스템이 기본값이다.
▣ 시스템이 유휴상태일 때 작업
시스템이 유휴상태일 때 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc onidle /i 10
참고 : 시스템이 유휴상태(사용자 사용이 없는 상태)
/i 매개변수는 유휴상태 대기 시간을 설정하며 유효값은 1~999분이다.
위 구문은 사용자입력이 10분동안 없으면 작업이 실행된다.
▣ 시스템 이벤트가 게시될 때 작업
특정 이벤트가 채널에 게시될때 마다 실행되는 작업
schtasks /create /tn “Event Check” /tr “Msg Admin01 계정이 변경되었습니다.” /sc onevent /ec Security /MO “*[System[Provider[@Name=’Microsoft-Windows-Security-Auditing’] and EventID=4738]]”
참고 : /sc onevent 에서 /ec는 event channel이며 유효값은 Application, Security, Setup, System 이다.
이벤트 쿼리 스트링에서는 반드시 대문자, 소문자 구별을 해야 한다.
이벤트 쿼리 스트링부분은 다음과 같이 간략하게 줄일 수 있다.
/MO *[System/EventID=4738]
▣ 지금 작업
지금부터 몇분 후에 한번 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc once /st 14:18 /sd 2018/05/13
참고 : 지금실행이라는 옵션은 없지만 현재시간으로부터 몇분 후에 한번 실행되는 작업을 만들 수 있다.
/st 매개변수는 필수사항이고 /sd 매개변수는 선택사항이다.
▣ 다른 권한으로 작업
로컬시스템에서 관리자권한으로 실행되는 작업
schtasks /create /tn “My Prg” /tr myprg.exe /sc weekly /d FRI /ru Admin01
참고 : 관리자권한(Admin01)으로 실행되는 작업을 만드려면 /ru 매개변수가 필요하다.
만약 명령을 입력하는 현재의 계정이 표준계정이라면 암호를 입력하는 메시지가 표시되며
암호를 입력해야만 한다.
이러한 암호는 /rp 매개변수로 처음부터 입력할 수 있으며 선택사항이다.
입력하는 계정이 관리자 계정에서는 암호가 필요하지 않다.
원격 시스템에서 다른 권한으로 3일마다 실행되는 작업
schtasks /create /tn “My Prg” /tr myprg.exe /sc daily /mo 3 /s office04 /u office04\Admin01 /ru Domain01\UserAcnt03
Type the password for office04\Admin01:********
Please enter the run as password for Domain01\UserAcnt03: ********
SUCCESS: The scheduled task “My Prg” has successfully been created.
참고 : /s 매개변수는 원격시스템이며
/u 매개변수는 원격시스템에서 작업권한이 있는 계정을 지정 – 작업예약 계정
/ru 작업을 실행할 때 사용되는 계정 지정 – 작업실행 계정
/ru 매개변수가 생략되면 /u 매개변수의 계정으로 실행
특정 사용자가 로그온 되어 있는 경우에만 매주 월요일 오후 5시에 실행되는 작업
schtasks /create /tn “My Prg” /tr myprg.exe /sc weekly /d MON /st 17:00 /s System10 /u Domain3\Admin03 /ru System10\Admin01 /it
참고 : System10\Admin01계정이 로그온되어 있는 경우에만 매주 금요일 오전 4시에 작업을 실행.
/it 매개변수는 System10\Admin01계정이 로그온되어 있는 경우에만 작업이 실행되는 옵션이다.
interactive전용(/it)속성이 있는 작업을 식별하려면 상세 쿼리(/Query/v)를 사용. /it 옵션이 포함된
작업의 상세 조회 표시에서 로그온 모드 필드의 값은 대화형만 가진다.
schtasks /query /v
시스템 권한으로 매월 7일에 실행되는 작업
schtasks /create /tn “My Prg” /tr c:\prg\myprg.exe /sc monthly /d 7 /ru System
참고 : /ru System(또는/ru “”)매개 변수(시스템보안 컨텍스트)가 필요하며 /rp 매개 변수가 유효하지 않는다.
/ru시스템 작업에서 암호를 사용하지 않으므로 /rp 매개 변수를 생략한다.
시스템 계정에 대화형 로그온 권한이 없으므로 사용자는 시스템 사용 권한으로 실행되는 프로그램
또는 작업을 보거나 상호 작용할 수 없다.
/ru 매개 변수는 작업을 예약하는 데 사용되는 권한이 아니라 작업이 실행되는 사용 권한을 결정.
/ru 매개 변수 값에 관계 없이 관리자(administrator)만 작업을 예약할 수 있다.
시스템 권한으로 실행되는 작업을 식별하려면 세부 쿼리(/query/v)를 사용.
시스템 실행 작업의 상세 조회 표시에서 “다음 계정으로 실행” 필드의 값은
NTAUTHORITY\SYSTEM이고 로그온 모드 필드의 값은 백그라운드 값이다.
원격 컴퓨터에서 시스템권한으로 매일 아침 8시에 실행되는 작업
schtasks /create /tn “My Prg” /tr myprg.exe /sc daily /st 08:00 /s computer01 /u Admin01 /ru System
참고 : /tr 매개 변수를 사용하여 myprg프로그램의 원격 복사본을 지정.
/sc 매개 변수를 사용하여 일일 작업을 지정하고 /mo 매개 변수를 생략하여 기본 값이 1(매일)으로
구성한다.
/u 매개 변수를 사용하여 원격 시스템에서 작업을 예약할 수 있는 권한이 있는 계정을 지정.
/ru 매개 변수를 사용하여 시스템 계정에서 작업을 실행하도록 지정.
/ru 매개 변수가 없으면 /u 에서 지정한 계정 권한으로 작업이 실행된다.
2개 이상의 프로그램이 실행되는 작업
schtasks /create /tn “security check” /tr c:\secuchk.bat /sc onlogon /ru Domain3\Admin01
참고 : 기본적으로 /tr 에서는 하나의 프로그램만 실행된다.
2개 이상의 프로그램을 실행하는 작업을 하려면 메모장에 프로그램을 나열하고 배치파일
(secuchk.bat)로 저장
예 : c:\Windows\System32\wf.msc
c:\Windows\Sytem32\secpol.msc
로그온 할때마다 관리자계정 권한으로 방화벽과 로컬보안정책이 동시에 실행된다.
원격 시스템에서 15일마다 실행되는 작업
schtasks /create /tn “My Prg” /tr “c:\program files\programs\myprg.exe” /sc daily /mo 15 /s server01
참고 : 로컬 현재 사용자는 원격 시스템의 관리자이므로 작업 예약에 대한 대체 권한을 제공하는
/u 매개 변수는 필요하지 않는다.
원격 컴퓨터에서 작업을 예약할 때는 모든 매개 변수가 원격 컴퓨터를 참조한다. /tr r매개 변수로
지정된 실행 파일은 원격 시스템에 있는 실행파일의 복사본을 참조한다.
참고 : 원격 시스템에서 실행되도록 작업을 예약하려면 다음 조건을 충족해야 한다.
◈ 작업을 예약할 수 있는 권한이 있어야 한다. 따라서 원격 시스템의 관리자 그룹에 속한 계정으로
로컬 시스템에서 로그온 하거나 원격 시스템의 관리자 자격 증명을 제공하려면 /u 매개 변수를
사용해야 한다.
◈ 로컬 및 원격 컴퓨터가 동일한 도메인에 있거나 원격 컴퓨터 도메인이 신뢰하는 도메인에
있는 경우에만 /u 매개 변수를 사용할 수 있다. 그렇지 않으면 원격 시스템이 지정된 사용자 계정을
인증할 수 없고 해당 계정이 관리자 그룹의 구성원인지 확인할 수 없다.
◈ 원격 컴퓨터에서 실행할 수 있는 충분한 권한이 있어야 한다. 기본적으로 작업은 로컬 컴퓨터의
현재 사용자 권한으로 실행되거나 /u 매개 변수를 사용하는 경우 /u 매개 변수로 지정된 계정의
사용 권한으로 실행된다. 그러나 /ru 매개 변수를 사용하여 다른 사용자 계정이나 시스템 사용
권한으로 작업을 실행할 수도 있다.
사용자가 원격 컴퓨터에서 3시간 마다 명령을 예약하는 경우
schtasks /create /tn “My Prg” /tr “c:\program files\programs\myprg.exe” /sc hourly /mo 3 /s server01 /u Domain1\admin01 /p N28$sp4X /ru server01\user04 /rp MyPw!9aD
참고 : 작업을 예약하려면 관리자 권한이 필요하므로 명령은 /u및 /p매개 변수를 사용하여 사용자의 관리자 계정 (Reskits도메인의 관리자 11)의 자격 증명을 제공한다. 기본적으로 이러한 권한은 작업를 실행하는 데도 사용된다.
그러나 작업을 실행하는 데 관리자 권한이 필요하지 않으므로 명령에는 /u및 /rp매개 변수가 포함되어 기본 값을 재정의하고 원격 시스템에서 사용자의 비 관리자 계정 권한으로 작업을 실행한다.
사용자가 원격 컴퓨터에서 매월 마지막 일에 명령을 예약하는 경우
schtasks /create /tn “My Prg” /tr “c:\program files\programs\myprg.exe” /sc monthly /mo LASTDAY /m * /s server2 /u business1\admin01
참고 : 로컬 현재 사용자(user01)는 원격 시스템의 관리자가 아니므로 명령은 /u 매개 변수를
사용하여 사용자의 관리자 계정(business도메인의 관리자 11)의 자격 증명을 제공하여 작업을 예약한다.
관리자 계정 권한은 작업을 예약하고 작업을 실행하는데 사용된다.
명령에 /p (비밀 번호)매개 변수가 포함되어 있지 않기 때문에 schtasks는 비밀 번호를 묻는 메시지를 표시한다.
그런 다음 성공 메시지와 경고를 표시한다.