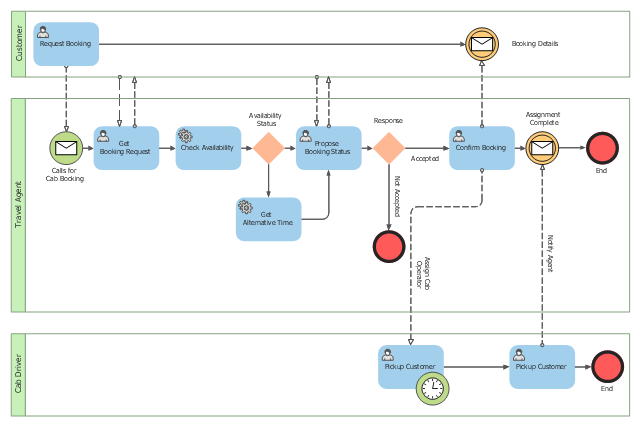
여기에서는 BPMN 2.0 사양에서 제공하는 기본적인 업무 프로세스 모델링 요소에 대해서 살펴보기로 한다. 다음 컬럼에서 이들 BPMN 모델링 요소를 사용하여 어떻게 업무 프로세스를 모델링하는가에 대해 살펴보게 될 것이다.
BPMN 2.0 개요
BPMN 2.0은 목적에 따라 다음과 같은 3가지 수준의 업무 프로세스 모델링을 지원한다.
· 서술 수준(descriptive level)
· 분석 수준(analytic level)
· 실행 수준(executable level)
서술 수준(descriptive level) 모델링은 업무 프로세스를 가시화 또는 시각화(visualization)하는 것을 목적으로 한다. 이것이 뭐 그리 대단하겠느냐고 생각할 지 모르겠지만 비즈니스 프로세스를 가시화한다는 것은 기본이면서도 아주 중요한 문제다. 사실 많은 기업이나 기관에서도 전사적인 업무 프로세스 모델을 보유하고 있는 경우는 드믈다. 대부분의 기업이나 기관에서 업무와 업무의 처리 흐름은 오직 담당자 또는 시스템을 개발한 개발자의 머리속에만 존재한다. 좀 더 나은 경우는 이것이 업무 매뉴얼에 서술되어 있는 경우이다. 그러나 이 또한 시간이 지나가면서 실제 업무 프로세스는 바뀌고 업무 매뉴얼과 일치하지 않는 경우가 발생하게 마련이다. 기업이나 기관에 표준이라고 할 수 있는 가시적으로 정의되어 있는 업무 프로세스가 없다보니 문제가 발생하거나 업무 프로세스가 변경될 때마다 사람의 기억에 의존하여 사안마다 다른 일관성 없는 해결 방안이 나올 수 밖에 없다. 이것이 누적되면 기업이나 기관의 업무 처리 방법은 복잡하며 일관성을 유지할 수 없게 되며, 이런 상황에서 합리적인 문제 해결 결론에 도달하기는 어렵게 된다. 따라서 기업이나 기관에 소속되어 있는 모든 사람들이 확실하게 이해할 수 있는 표준 업무 프로세스를 정의하고 이것을 유지 관리하는 일은 매우 중요한 일이 된다.
다음 단계의 분석 수준(analytic level) 모델링은 업무 효율성 제고를 위해 업무 프로세스를 모델링하는 것을 목적으로 한다. 이 수준에서의 업무 프로세스 모델링은 현행 프로세스(as-is process)를 정의하고, 현행 프로세스를 분석하여 개선할 수 있는 부분을 찾아 여러 개의 후보 프로세스(candidate process)를 모델링한 후에 이들 프로세스를 ABC(Activity Based Cost) 기반으로 시뮬레이션(simulation)을 수행하여 이들 중 최적의 프로세스를 찾아 최종 프로세스(to-be process)로 정의하는 일련의 과정들로 구성된다. 이 수준의 업무 프로세스 모델링은 현행 업무 프로세스를 개선하고자 할 때 필요하다.
마지막으로 실행 수준(executable level) 모델링은 BPM(Business Process Management) 기반으로 업무 프로세스를 실행하는 것을 목적으로 한다. 정의된 업무 프로세스 모델은 그대로 BPMS(Business Process Management Suite)가 제공하는 프로세스 실행 엔진(process execution engine)에 의하여 실행된다. BPMN 1.x까지 BPMN 모델은 BPEL(Business Process Execution Language)로 변환되어 BPEL 엔진에 의해 실행되었지만 BPMN 2.0부터는 에러가 많은 BPEL로의 변환 과정을 거지치 않아도 직접 프로세스 실행 엔진에 의해 BPMN 모델을 실행할 수 있게 되었다.
서술 수준 또는 분석 수준에서 프로세스 모델링을 수행하는 것도 의미있는 일이지만, 특히 실행 수준에서 프로세스를 모델링하고 그 프로세스 모델을 BPMS 상에서 실행하는 일은 매우 중요한 의미를 갖는다. 업무적으로는 업무 환경의 변화에 대하여 업무 담당자 스스로 민첩한 대응 능력을 갖게 된다는 것을 의미하며, 기술적으로는 프로세스 중심적인 시스템 구축으로 애플리케이션으로부터 프로세스와 업무 규칙을 분리함으로써 시스템의 변화 요구에 대하여 민첩한 대응 능력을 갖게 된다는 것이다. BPM 기반의 이점에 대해서는 다음에 상세히 설명하도록 한다.
각 프로세스 모델링 수준에 따라 업무 분석가나 프로세스 개발자가 사용하는 세부적인 BPMN 2.0 모델링 요소도 달라질 수 있다. 예를 들어 서술 수준에서는 업무 분석가가 업무 프로세스의 전반적인 흐름을 표현하는데 적당한 비교적 간단한 모델링 요소만을 사용하여 모델링할 수 있다. 그러나 분석 수준에서 업무 프로세스를 분석하고 시뮬레이션하기 위해서는 복잡한 모델링 요소들을 잘 활용하여 정확하게 업무 프로세스를 모델링해야 할 필요가 있다. 마찬가지로 실행 수준에서도 BPMS가 지원하고 추가로 제공하는 기능을 잘 활용하여 업무 프로세스를 상세하게 설계해야 한다.
여기에서는 업무 분석가가 서술 수준에서 업무 프로세스를 모델링하는데 필요한 BPMN 2.0 표기법에 대해서만 살펴보기로 한다.
BPMN 2.0 모델링 요소는 다음과 같이 분류된다.
· 플로우(flow)
· 참가자(participant)
· 데이터(data)
· 커넥터(connector)
· 아티팩트(artifact)
플로우(flow)
플로우는 업무 프로세스의 행위를 정의한다. BPMN은 다음과 같은 3종류의 플로우 객체를 정의한다.
· 이벤트(event) : ‘어떤 일이 발생했다’는 신호(signal)
· 활동(activity) : 프로세스에서 수행된 작업(work)
· 게이트웨이(gateway) : 라우팅 로직(routing logic)
이벤트(event)
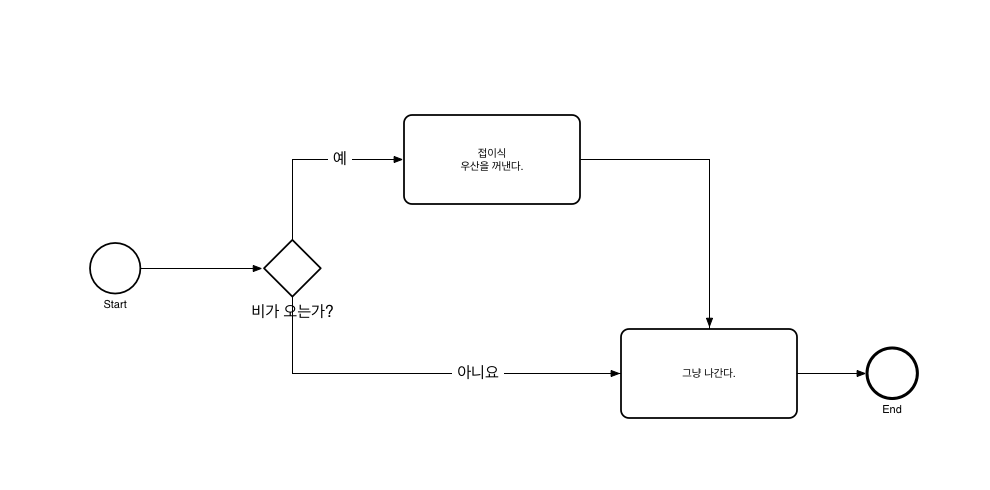
이벤트는 프로세스 실행 과정에서 발생하여 정상적인 흐름에 영향을 주는 것을 말한다. 업무 프로세스는 항상 이벤트로 시작하여 이벤트로 끝난다. 즉, 시작 이벤트(start event)가 발생할 때 프로세스 실행이 시작되고, 프로세스 흐름이 끝나면 끝 이벤트(end event)가 발생한다. 시작 이벤트는 이벤트를 받지만 끝 이벤트는 이벤트를 발생시킨다. 다시말해 시작 이벤트는 이벤트 리스너(event listener)로서 이벤트 정보를 처리하여 특정한 행위를 계속 수행한다. 그러나 끝 이벤트는 이벤트 전송자(event transmitter)로서 이벤트 정보를 생성하여 전송한다.
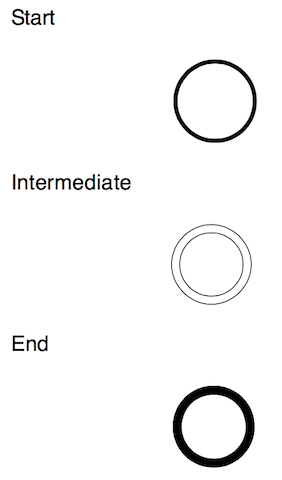
시작 이벤트는 다음과 같이 선이 가는 원형으로 표현된다.

[그림.1 시작 이벤트]
위의 표기법은 일반적인 시작 이벤트(non start event)를 표현한다. 이것은 시작 이벤트로서 이벤트가 어떻게 발생하는지를 명시하지 않는다. 어떤 방식으로 이벤트를 발생시키는 지를 명시하고 싶다면 원 안에 내부 심볼을 표현한다. 만약 메시지를 받을 때 시작 이벤트가 발생하는 메시지 시작 이벤트(message start event)는 다음과 같은 내부 심볼을 갖는다.

[그림.2 메시지 시작 이벤트]
특정 시간에 시작 이벤트를 발생시키는 타이머 시작 이벤트(timer start event)는 다음과 같은 내부 심볼을 갖는다.

[그림.3 타이머 시작 이벤트]
프로세스 흐름이 끝날 때 발생되는 끝 이벤트는 다음과 같이 선이 굵은 원형으로 표현된다.

[그림.4 끝 이벤트]
시작 이벤트와 마찬가지로 위 표기법은 일반적인 끝 이벤트(non end event)를 표현한다. 즉, 프로세스 흐름이 끝날 때 어떤 종류의 끝 이벤트가 발생시키는 지를 명시하지 않는다. 만약 프로세스 흐름이 끝날 때 메시지 이벤트를 발생시킨다면 메시지 끝 이벤트(message end event)를 사용한다. 메시지 끝 이벤트는 다음과 같은 내부 심볼을 갖는다.

[그림.5 메시지 끝 이벤트]
만약 실행되고 있는 모든 프로세스 흐름을 즉시 종료시키고 싶다면 다음과 같은 내부 심볼로 표현되는 종료 끝 이벤트(terminate end event)를 사용한다.

[그림.6 종료 끝 이벤트]
활동(activity)
활동(activity)이란 업무 프로세스 안에서 실행되는 작업을 나타내는 일반적인 용어로서 다음과 같은 3가지 유형의 활동이 있다.
· 작업(task)
· 서브 프로세스(sub process)
· 활동 호출(call activity)
작업(task)이란 완전히 수행되거나 아니면 전혀 수행되지 않는 원소적(atomic) 단위 활동을 말한다. 따라서 작업은 한 번에 한 장소에서 수행될 수 있는 일이어야 한다. 작업은 다음과 같이 모서리가 둥근 직사각형의 형태의 표기법을 갖는다. 내부에는 수행되는 작업을 표시하는 텍스트가 표시된다.
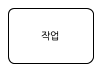
[그림.7 작업]
위의 표기법은 추상적인 작업(abstract task)을 표현한다. 추상적인 작업은 프로세스 실행에는 영향을 주지 않고 프로세스를 명확하게 이해하기 위해서 사용한다. 구체적인 작업의 내부 행위를 명시하고 싶다면 작업의 유형을 지정해야 한다. 만약 화면에서 정보를 입력하는 것과 같이 사용자가 수행하는 작업을 명시하고 싶다면 사용자 작업(user task)를 사용한다. 사용자 작업은 다음과 같은 내부 심볼을 갖는다.

[그림.8 사용자 작업]
또한 웹 서비스(web services)나 소프트웨어 솔루션과 같은 외부 서비스(external service)를 실행하는 작업을 수행한다면 서비스 작업(service task)를 사용한다. 서비스 작업은 다음과 같은 내부 심볼을 갖는다.

[그림.9 서비스 작업]
서브 프로세스(sub process)란 프로세스 안에서 내부의 세부 실행 흐름을 포함하는 활동으로, 서브 프로세스는 다음과 같은 유형을 갖는다.
· 포함(embedded)
· 재사용(reusable)
· 트랜잭션(transaction)
· 이벤트(event)
· 특별(ad-hoc)
여기에서는 이들 유형의 서브 프로세스 중에서 포함과 재사용 서브 프로세스에 대해서만 다루기로 한다.
포함 서브 프로세스(embedded sub process)는 부모 프로세스(parent process) 내부에 포함되는 서브 프로세스를 말한다. 포함 서브 프로세스는 작업과 마찬가지로 모서리가 둥근 사각형으로 표현되며 펼쳐진 형태로 표현될 수 있고, 축소된 형태로 표현될 수도 있다. 펼쳐진 형태로 표현될 때는 – 내부 심볼과 함께 다음과 같이 표현된다.
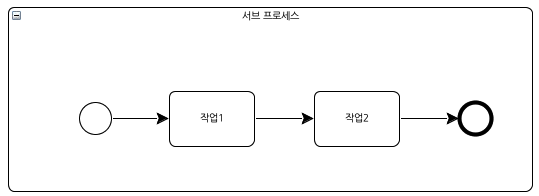
[그림 10.펼쳐진 서브 프로세스]
펼쳐진 형태로 포함 서브 프로세스가 부모 서브 프로세스 내부에 직접 표현된다면 세부 프로세스 흐름을 이해하기는 좋지만 아무래도 전체 프로세스 다이어그램을 복잡하게 만든다. 이 경우에는 다음과 같이 축소된 형태로 표현하여 다이어그램을 단순하게 만들 수 있다. 축소된 서브 프로세스에는 + 내부 심볼이 표현된다.

[그림 11.축소된 서브 프로세스]
재사용 서브 프로세스(reusable sub process)는 다른 여러 부모 프로세스에서 재사용할 수 있도록 정의된 프로세스를 말한다. 포함 서브 프로세스는 하나의 부모 프로세스 내부에 직접 포함되지만, 재사용 서브 프로세스는 부모 프로세스와는 별도의 다이어그램에 표현된다. 또한 포함 서브 프로세스가 단 하나의 부모 프로세스에만 종속되어 포함되지만, 재사용 서브 프로세스는 여러 부모 프로세스에서 재사용될 수 있다. 그러니까 재사용 서브 프로세스는 여러 부모 프로세스에 공통적인 활동의 흐름을 표현하는데 적당하다. 서브 프로세스는 다음과 같이 별도의 다이어그램으로 표현된다.

[그림 12.서브 프로세스]
부모 프로세스 다이어그램에서 이와 같은 재사용 서브 프로세스를 호출하여야 할 때는 활동 호출(call activity)를 사용한다. 재사용 서브 프로세스를 호출하는 활동 호출은 작업과는 달리 굵은 선으로 표현되며 축소된 서브 프로세스와 같이 + 내부 심볼을 갖는다.
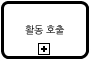
[그림 13.활동 호출]
게이트웨이(gateway)
프로세스는 다양한 대체 흐름이나 동시 흐름을 포함할 수 있다. 게이트웨이(gateway)는 이러한 프로세스 흐름을 분할하고 분할된 흐름을 다시 병합하는 일을 통제한다. 게이트웨이는 다음과 같이 마름모 꼴로 표현된다.

[그림 14.게이트웨이]
게이트웨이의 가장 일반적인 유형이 배타적(XOR) 게이트웨이이다. 배타적 게이트웨이는 조건에 따라 프로세스 흐름을 배타적으로 분할하고, 배타적으로 분할된 프로세스 흐름을 병합한다. 배타적 분할은 마치 프로그래밍 언어에서 if 문이나 switch 문을 사용하는 것과 같다. 조건에 따라 어느 하나의 흐름으로 분할되는 것이다. 배타적 병합은 배타적 분할로 분할된 프로세스 흐름을 병합하는 역할을 한다. 그림 14의 게이트웨이는 배타적 게이트웨이를 표현한다. 즉, 배타적 게이트웨이는 기본적인 게이트웨이트인 셈이다. 배타적 게이트웨이는 다음과 같이 구체적인 내부 심볼을 가질 수 있다.

[그림 15.배타적 게이트웨이]
분할된 모든 프로세스 흐름이 동시에 흘러간다면 병렬 게이트웨이(parallel gateway)를 사용한다. 배타적 게이트웨이가 분할된 흐름 중 하나만 흘러간다면, 병렬 게이트웨이는 분할된 모든 흐름이 동시에 흘러간다는 점에서 대조를 이룬다. 병렬 게이트웨이로 분할된 프로세스 흐름은 병렬 게이트웨이로 병합되어야 한다. 병렬 게이트웨이는 다음과 같은 내부 심볼을 갖는다.

[그림 16.병렬 게이트웨이]
참가자(participant)
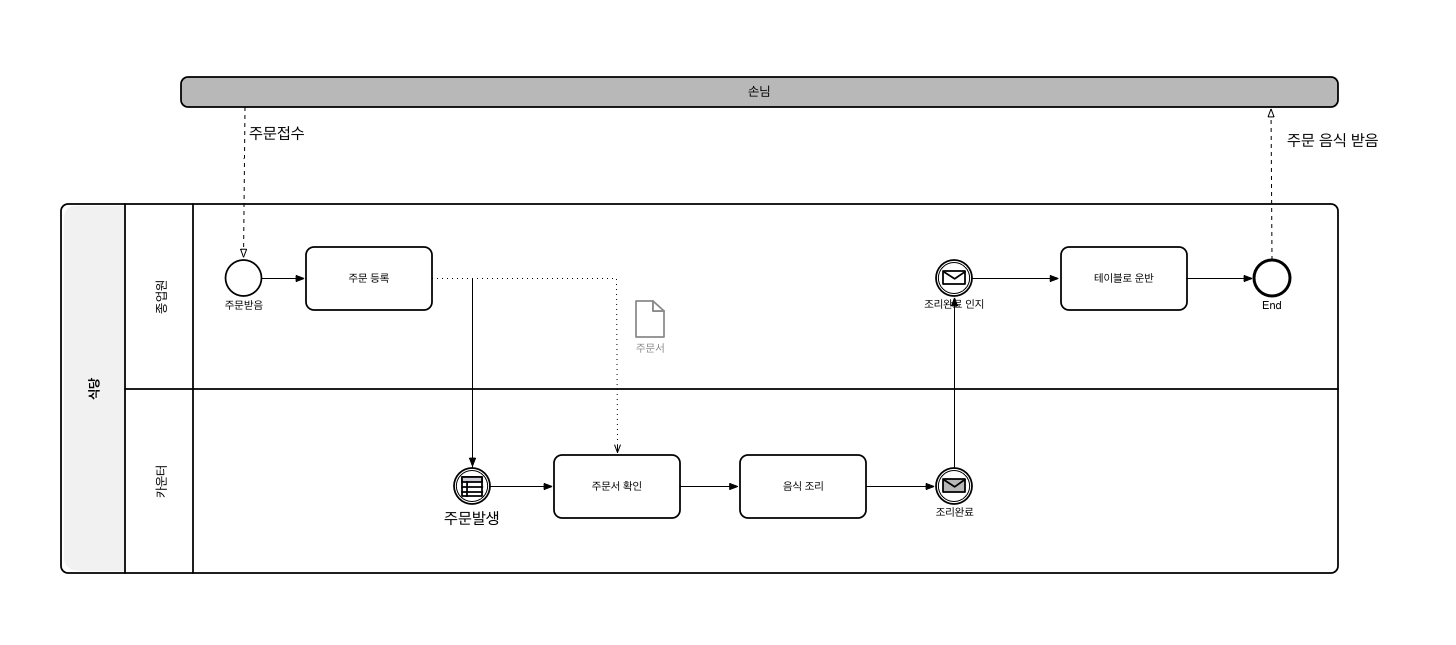
참가자란 프로세스 안에 있는 활동을 실행하거나 실행할 책임을 갖는 업무 실체(business entity)를 말한다. 참가자는 회사와 같은 조직(organizational unit)일 수도 있고 어떤 일을 수행하는 역할(role)일 수도 있다. BPMN에서 참가자는 풀(pool)로 표현된다. 풀은 다음과 같이 라벨(label)을 갖는 모서리가 각진 사각형으로 표현된다. 레이블에는 참가자의 이름이 표시된다.

[그림 17.풀]
풀은 일반적으로 위의 그림과 같이 수평으로 표시되지만 수직으로 표시될 수도 있다. 하나의 프로세스 다이어그램은 여러 풀을 포함할 수 있다. 만약 프로세스 다이어그램이 하나의 풀만을 포함한다면 일반적으로 풀은 표현하지 않는다.
비즈니스 프로세스는 하나의 조직 내의 여러 역할을 수행하는 참가자에 의해 실행될 수 있다. 이들 역할은 풀에 포함되는 레인(lane)으로 표현된다. 레인은 풀 안에 포함되며 라벨을 갖는 직사격형으로 표현된다.

[그림 18.레인]
풀 안에 레인이 하나만 있다면 일반적으로 레인은 생략된다. 풀과 레인은 수영장을 생각하면 쉽게 이해할 수 있다. 하나의 수영장에는 여러 개의 풀이 있고, 하나의 풀에는 여러 레인이 있다. 그러나 수영장과는 달리 하나의 레인이 하위에 여러 레인을 포함할 수도 있다.
풀과 레인에는 다음과 같이 조직 또는 역할이 수행하는 프로세스의 활동 흐름이 표현된다.

[그림 19.활동 흐름]
데이터(data)
데이터(data)는 프로세스 흐름에서 처리되는 데이터 구조와 정보를 표현하며, 다음과 같은 4가지 데이터 모델 요소를 사용할 수 있다.
· 데이터 객체(data object)
· 입력 데이터(data input)
· 출력 데이터(data output)
· 데이터 저장소(data store)
데이터 객체(data object)는 프로세스 흐름 안에서 처리되는 일반적인 데이터 항목을 표현하며 다음과 같이 표현된다.

[그림 20.데이터 객체]
프로세스 흐름을 실행하는 동안에 변경되는 데이터 객체의 상태는 다음 그림과 같이 대괄호([ ]) 안에 표시한다.
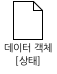
[그림 21.데이터 객체 상태]
활동을 수행하는데 필요한 데이터 객체라면 해당 데이터 객체를 입력 데이터(data input)로 표현할 수 있다. 입력 데이터는 다음과 같은 내부 심볼을 갖는다.

[그림 22.입력 데이터]
활동을 수행한 결과 데이터 객체가 생성되었다면 해당 데이터 객체를 출력 데이터(data output)으로 표현할 수 있다. 출력 데이터는 다음과 같은 내부 심볼을 갖는다.

[그림 23.출력 데이터]
처리하는 데이터가 데이터베이스와 같은 정보 시스템에 있다면 다음과 같이 데이터 저장소(data store)를 사용할 수 있다.

[그림 24.데이터 저장소]
커넥터(connector)
프로세스 모델은 프로세스 처리 흐름을 표현해야 하므로 플로우 객체들을 연결할 수 있는 연결 객체(connecting object)가 필요하며, BPMN 2.0에서는 다음과 같은 4가지 연결 객체를 제공한다.
· 시퀀스 플로우(sequence flow)
· 메시지 플로우(message flow)
· 데이터 연관(data association)
· 연관(association)
시퀀스 플로우(sequence flow)는 화살표를 사용하여 프로세스 다이어그램에서 플로우 객체의 실행 순서를 표시한다. 시퀀스 플로우는 다음과 같이 실선의 화살표로 표시된다.

[그림 25.시퀀스 플로우]
시퀀스 플로우는 같은 풀(pool) 안에 정의된 플로우 객체 사이의 실행 흐름에만 사용할 수 있다. 풀 사이에 또는, 서로 다른 풀 안에 있는 플로우 객체 사이에는 메시지 플로우(message flow)를 사용해야 한다. 메시지 플로우는 점선의 빈 촉 화살표로 표시된다.

[그림 26. 메시지 플로우]
메시지 플로우는 다음과 같이 풀을 연결하는데 사용할 수 있다.
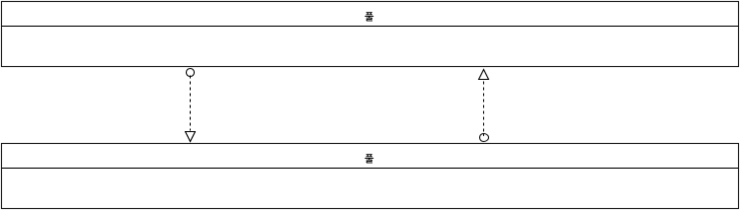
[그림 27.풀 연결]
또는 다음과 같이 서로 다른 풀에 있는 플로우 객체를 연결하는데 사용된다.
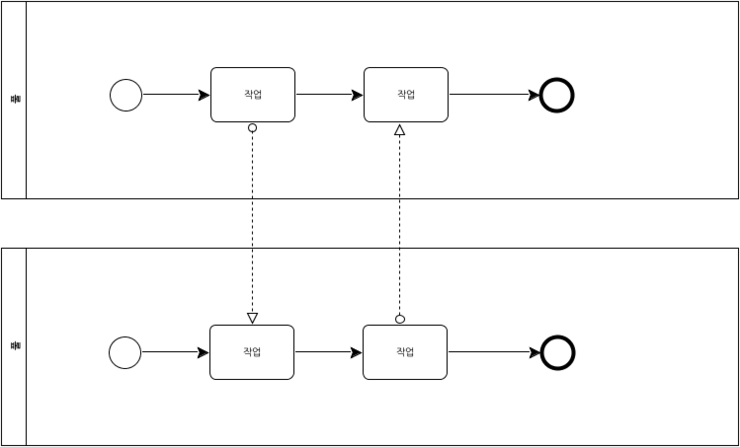
[그림 28.풀 사이의 플로우 객체 연결]
메시지 플로우에 전달되는 정보를 포함하는 데이터 구조 즉, 메시지(message)를 추가할 수 있다. 상호작용의 초기에 전달되는 메시지 즉, 초기 메시지(initializing message)는 다음과 같이 표시된다.

[그림 29.초기 메시지]
상호작용에서 반환되는 메시지 즉, 비초기 메시지(non-initializing message)는 다음과 같이 표시된다.

[그림 30.반환(비초기) 메시지]
이들 메시지는 메시지 플로우에 부착되어 메시지 플로우를 통하여 어떤 메시지가 전달되는 지를 표시할 수 있다. 다음 그림은 풀을 연결하는 메시지 플로우에 메시지가 부착된 결과를 보여준다.
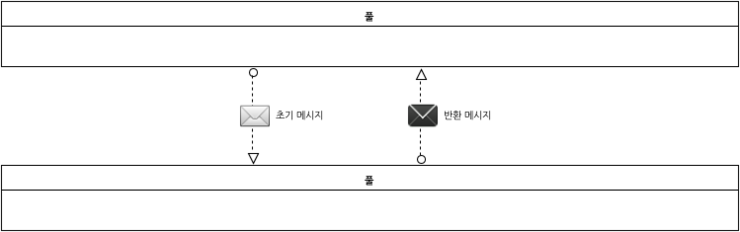
[그림 31.풀 연결 메시지 플로우에 메시지 부착]
다음 그림은서로 다른 풀에 있는 플로우 객체를 연결하는 메시지 플로우에 메시지가 부착된 결과를 보여준다.
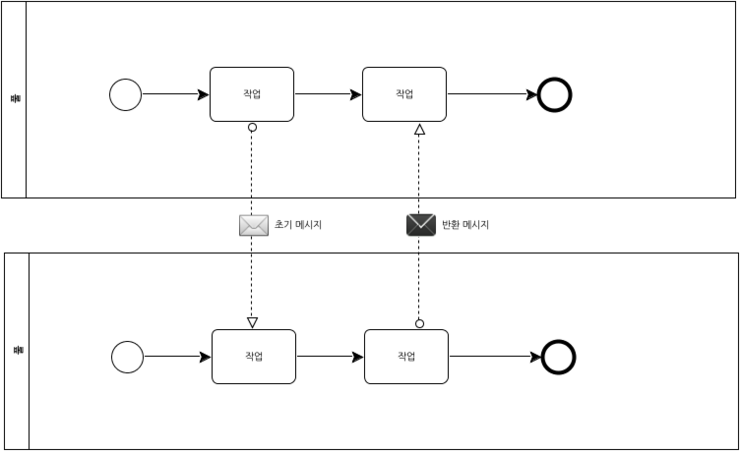
[그림 32. 풀 사이의 플로우 객체 연결 메시지 플로우에 메시지 부착]
데이터 연관(data association)은 데이터 객체와 활동의 입출력 사이에 데이터를 이동시키는데 사용된다. 데이터 연관은 다음과 같이 점선 화살표로 표시된다.
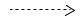
[그림 33.데이터 연관]
다음 그림은 입력 데이터가 작업에 제공되는 것을 표현한다.
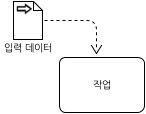
[그림 34.입력 데이터 연관]
다음 그림은 작업으로부터 출력 데이터가 생성되는 것을 표현한다.
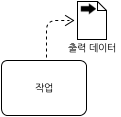
[그림 35.출력 데이터 연관]
다음 그림은 데이터 객체가 두 작업 사이에 전달되는 것을 표현한다.
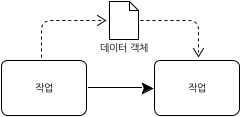
[그림 36.데이터 객체 연관]
다음 그림은 데이터 저장소를 통하여 두 작업 사이에 데이터가 이동하는 것을 표현한다.
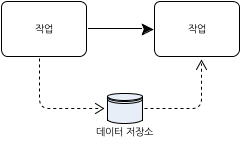
[그림 37.데이터 저장소 연관]
연관(association)에 대해서는 아티팩트(artifact) 절에서 살펴보기로 한다.
아티팩트(artifact)
아티팩트(artifact)는 프로세스 실행에 영향을 미치지 않고 프로세스 다이어그램에만 표현하는 구문적인 정보를 말한다. BPMN 2.0은 다음 2가지 아키팩트를 제공한다.
· 주석(annotation)
· 그룹(group)
주석(annotation)은 텍스트로 표현된 설명이다. 주석은 다음과 같이 표현된다.

[그림 38.주석]
주석은 모델 요소에 부착되며, 이때 주석과 모델 요소를 연결하는 커넥터를 연관(association)이라고 한다. 연관은 다음과 같이 점선으로 표현된다.
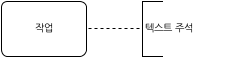
[그림 39.주석 연관]
그룹(group)은 일련의 모델 요소의 그룹에 어떤 특별한 의미를 부여하기 위해 사용되는 시각적인 표현이다. 그룹은 다음과 같은 모서리가 둥근 사각형 점선으로 표현된다.

[그림 40.그룹]












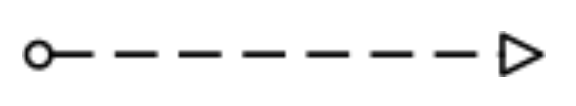














 버튼으로 신규 호스트 전용 어댑터를 생성한다.
버튼으로 신규 호스트 전용 어댑터를 생성한다.
 )을 클릭하여 아래와 같이 IP 주소를 확인한다.
)을 클릭하여 아래와 같이 IP 주소를 확인한다.


