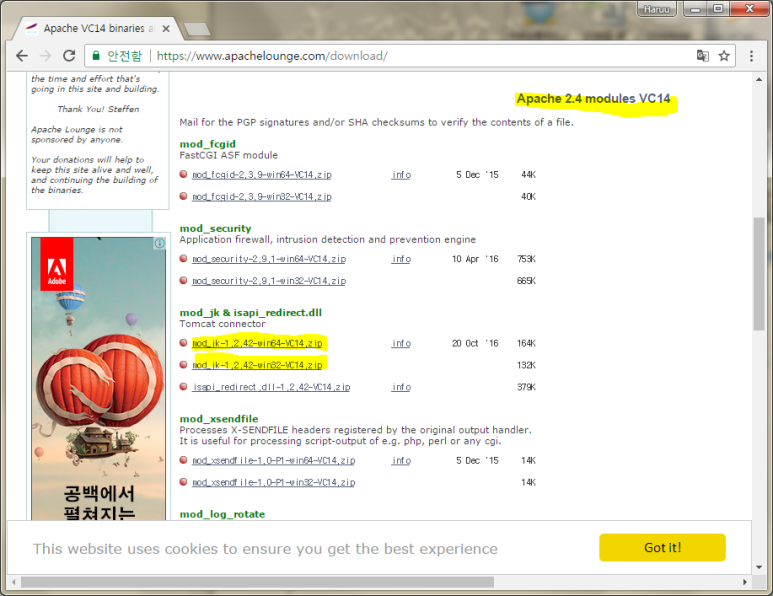
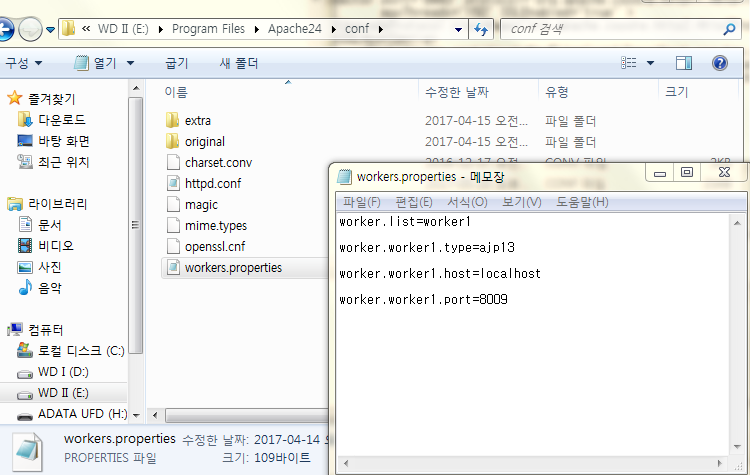
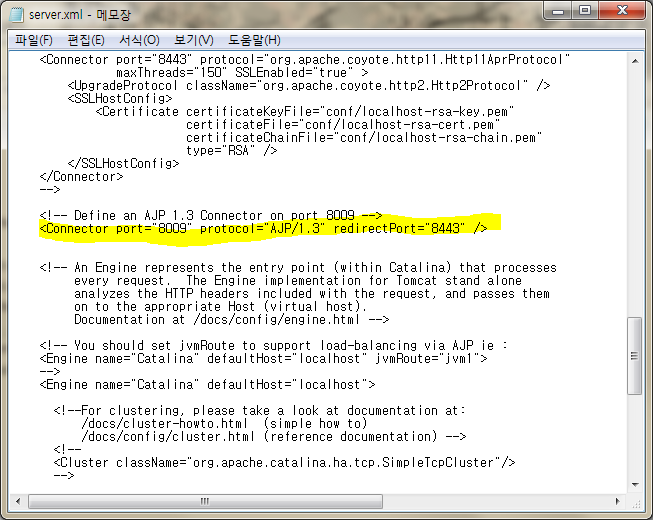
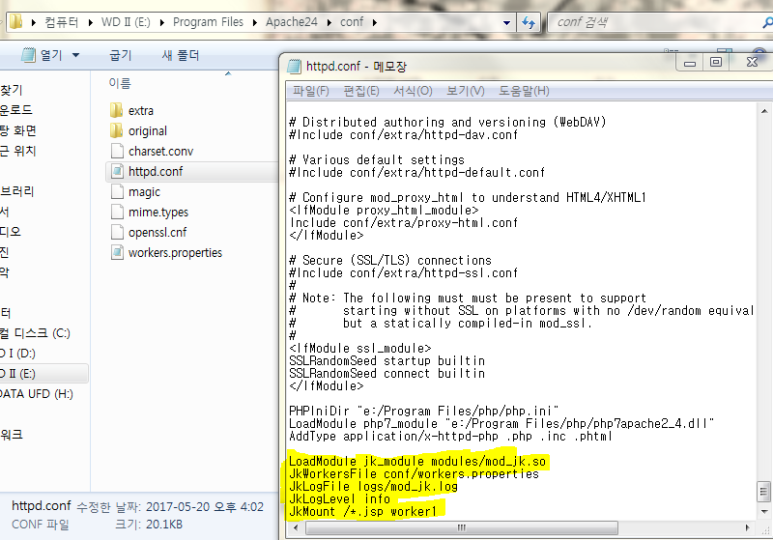
JSONP는 한 웹페이지에서 도메인이 다른 웹페이지로 데이터를 요청할 때 사용하는 자바스크립트 개발 방법론입니다.
기본적으로 웹 브라우저는 도메인이 다른 웹 페이지로는 Ajax 등의 방법으로 접근하지 못하게 제한하고 있는데, 이것을 동일출처원칙(Same-origin policy)이라고 합니다. 그러나 실무에서는 부득이 다른 도메인에 연결된 서버로 데이터를 요청해야만 하는 상황을 만나게 됩니다. JSONP는 바로 이러한 경우에 동일출처원칙을 회피하는 일종의 편법 입니다.
JSONP는 동일출처원칙을 회피하기 위해 <script> 요소를 이용합니다. 본래 자바스크립트에서는 Ajax를 비롯한 어떠한 방법으로도 직접 다른 도메인의 웹페이지로 데이터를 요청할 수 없습니다. 그러나 <script> 요소는 도메인이 다른 스크립트 파일이라 하더라도 임베드할 수 있기 때문에, 이 성질을 이용하는 것입니다.
국내 웹에서 JSONP에 대해 검색을 하면, jQuery를 사용하여 간편하게 JSONP를 구현한 방법을 소개하는 포스팅이 주류를 이루고 있습니다. 이 방법은 Ajax를 구현할 때와 유사한 방식으로 쉽고 간편하게 JSONP를 구현할 수 있게 해주지만, 한편으로는 JSONP의 기본원리에 대해서는 소홀하게 만드는 양면성을 가지고 있습니다.
금번 포스팅에서는 JSONP의 기본원리를 설명하기 위하여, 순수 자바스크립트로 JSONP를 구현한 예제코드를 소개합니다. 또한 Ajax와의 비교를 통해 JSONP의 효용과 한계에 대해서 짚어볼 것입니다. 마지막으로 실무에서 활용하기 좋은 jQuery에서의 JSONP 구현방법까지 살펴보고 나면 글을 마치게 될 것입니다.
예제코드 개요
회원명부에서 이름으로 검색하는 웹페이지를 작성하려고 합니다. 그런데 한 가지 문제가 있습니다. 메인 웹 서버에는 a.epiloum.net 도메인이 연결되어 있는데 반해, 회원명부 DB는 b.epiloum.net 도메인에 연결된 서버에 있다는 것입니다. 동일출처원칙으로 인하여 일반적인 방법으로는 a.epiloum.net의 웹페이지가 b.epiloum.net에 있는 웹페이지를 호출할 수는 없습니다.
(이러한 상황을 타개하는 가장 간편한 방법은, a.epiloum.net에서 b.epiloum.net의 DB를 접근할 수 있도록 접근권한을 조정하는 것입니다. 하지만 웹 서버와 DB 서버가 여러 대로 분산되어 있는 대형 웹 서비스라면, 이것 또한 녹록치 않을 것입니다.)
위와 같은 상황을 JSONP를 통하여 극복해보도록 하겠습니다. 이 예제는 PHP + MySQL 환경을 기준으로 하며, DB 서버로 사용하는 b.epiloum.net에도 웹 서버가 설치되어 있다고 가정할 것입니다.
클라이언트측 예제코드 – http://a.epiloum.net/index.html
아래는 JSONP로 데이터를 요청할 검색화면 웹페이지의 예제코드입니다. 이 소스코드 파일은 a.epiloum.net라는 도메인 아래에 위치할 것입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
<!DOCTYPE html><html lang="ko"><head><title>JSONP Sample Code</title><meta charset="utf-8"><script type="text/javascript">function find(){ var j = document.createElement('script'); var s = encodeURIComponent(document.getElementById('str').value); var u = 'http://b.epiloum.net/find.php?callback=loadList&s=' + s; j.setAttribute('src', u); j.setAttribute('type', 'text/javascript'); document.getElementsByTagName('body')[0].appendChild(j); return false;}function loadList(arr){ var o = document.getElementById('list'); var l; while(o.childNodes.length) { o.removeChild(o.lastChild); } for(var i=0; i<arr.length; i++) { l = document.createElement('li'); l.appendChild(document.createTextNode(arr[i])); o.appendChild(l); }}</script></head><body><input id="str" type="text" size="50" /><input id="btn" type="button" value="입력" onclick="return find()" /><ul id="list"></ul></body></html> |
실제로 코드를 웹 서버에 올려 접속해보시면, 텍스트 입력란과 버튼이 표시된 화면을 볼 수 있습니다. 텍스트 입력란에 적당한 텍스트를 입력하고 버튼을 누르면, find()라는 자바스크립트 함수가 실행될 것입니다. 이 함수는 새로운 <script> 요소를 생성하여 <body> 요소 아래에 추가하는 역할을 합니다.
여기서 주목할 것은 <script>의 src 속성인데요, URL의 도메인이 현재 도메인과는 다른 b.epiloum.net임을 확인할 수 있습니다. GET 파라메터 또한 확인해두셔야 하는데요. callback이라는 파라메터에는 “loadList”라는 문자열이 들어가 있는데, 이것과 같은 이름을 가진 loadList()라는 함수가 있다는 점을 기억하시기 바랍니다. 이어서 s라는 파라메터에는 사용자가 텍스트 입력란에 타이핑한 값이 들어가게 됩니다.
마지막으로 위 예제코드 어디에서도 호출하는 부분이 없는 loadList() 함수가 있습니다. 이 함수는 인자로 받은 배열의 내용을 <ul id=”list”> 요소 아래에 표시하는 역할을 합니다.
서버측 예제코드 – http://b.epiloum.net/find.php
이제 앞서의 예제코드에서 <script> 요소를 생성하여 호출하는 find.php의 소스코드를 살펴볼 차례입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
<?// Send HTTP Headerheader('Content-Type:application/javascript');// Connect to DB$dbi = mysql_connect('localhost', '****', '****');mysql_select_db('****', $dbi);mysql_query('SET NAMES utf8', $dbi);// DB Search$sql = 'SELECT name FROM member WHERE ';$sql .= 'name LIKE "%' . mysql_real_escape_string($_GET['s']) . '%"';$res = mysql_query($sql, $dbi);$dat = array();while($v = mysql_fetch_assoc($res)){ $dat[] = $v['name'];}// Outputecho $_GET['callback'] . '(' . json_encode($dat) . ')';?> |
이 소스코드는 회원명부를 담고 있는 `member` 테이블에서, 이름에 해당하는 `name` 필드에 검색어가 포함된 레코드를 LIKE 문을 사용해 검색합니다. 검색어는 GET 파라메터 s를 통해 입력받습니다. 검색한 결과는 PHP 변수인 $dat에 배열로 담아두게 됩니다. 여기까지는 그다지 특이한 것이 없어보입니다.
주목할 곳은 바로 검색결과를 출력하는 부분에 있습니다. 일반적으로 Ajax를 사용할 때는 검색결과를 JSON 형식으로 출력하고 마치는 것이 보통입니다. 그러나 JSONP 방식을 사용한 위 예제코드는 조금 달라보입니다. 바로 GET 파라메터 callback을 통해 전달받은 이름의 함수를 호출하는 자바스크립트 코드를 출력하고 있는 것이죠. 그리고 그 함수의 인자로, 회원명부에서 검색한 결과를 담은 배열이 들어갑니다.
예제코드 실행시의 결과
이제 앞서 살펴본 두 소스코드를 연결해서 생각해보면 JSONP의 전말이 드러납니다. 일단 검색화면 웹페이지에서 “john”을 입력하고 버튼을 클릭하면, 아래와 같은 <script> 요소가 생성되었을 것입니다.
<script src=”http://b.epiloum.net/find.php?callback=loadList&s=john”></script>
이렇게 호출된 find.php 파일은 아래와 같이, callback 파라메터로 전달받은 이름인 loadList() 함수를 실행하는 스크립트를 출력합니다. 함수의 인자로 “john”으로 검색한 결과가 배열이 들어오는 것은 물론입니다.
loadList([“John Miller”,”John C. Potter”])
이렇게 검색화면 웹페이지에서 정의한 loadList() 함수가 실행되면, 처음 우리가 살펴보았던대로 <ul id=”list”> 요소 아래에 John이라는 단어로 검색한 결과가 목록으로 보이게 됩니다.
JSONP의 기본원리와 한계
위 예제를 토대로 우리는 이제 JSONP가 작동하는 원리를 아래와 같이 정리할 수 있습니다.
- 데이터를 요청할 페이지에, 데이터를 받아 처리할 콜백 함수를 먼저 준비해놓습니다. 그 후에 <script> 요소를 생성하여, 데이터 요청을 합니다.
- 데이터 요청을 받은 페이지에서는 콜백 함수를 실행하는 스크립트를 출력합니다. 이 때 callback 함수의 인자에는 요청받은 데이터가 들어가게 됩니다.
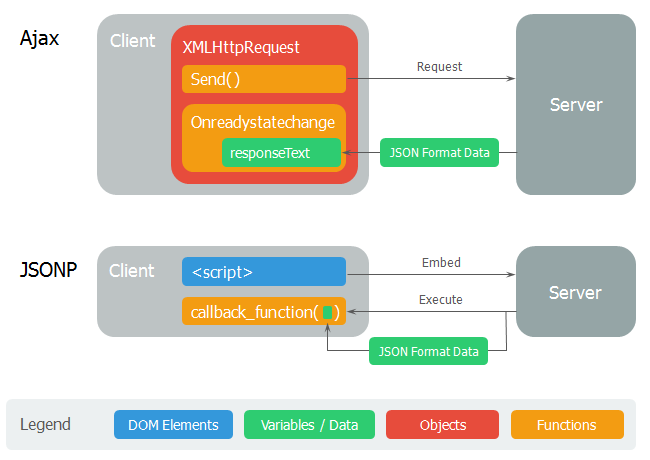
Ajax와 JSONP 비교 개념도
우리가 잘 알고 있는 Ajax와 비교해보면 흐름 자체가 크게 다르지 않습니다. 단지 콜백함수를 실행하는 타이밍이 달라졌을 뿐입니다. Ajax는 데이터 만을 일단 responseText 속성으로 가져온 후, XMLHttpRequest 객체에서 onreadystatechange 속성에 담긴 콜백함수를 실행합니다. 반면에 JSONP는 서버측에서 이미 콜백함수를 실행하는 코드를 반환하는 점이 다를 뿐입니다. 이처럼 Ajax와 동일한 효과를 가지면서도 동일출처원칙을 회피할 수 있는 것, 이것이 JSONP가 가진 효용성이라고 할 수 있습니다.
한편 Ajax와 비교하여 JSONP가 가지는 한계도 나타나는데, 바로 GET Method만을 사용할 수 있다는 점입니다. 이것은 JSONP가 <script> 요소를 사용하기 때문에 가지는 숙명적인 한계라고 할 수 있습니다.
jQuery에서 JSONP 사용하기
금번 포스팅에서는 JSONP의 원리를 설명하기 위하여 Live Javascript로 예제코드를 작성하였지만, 실무에서는 대부분 jQuery를 이용하게 될 것입니다. 위 예제파일의 find() 함수를 jQuery로 변경하면 아래와 같습니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
function find(){ var s = encodeURIComponent(document.getElementById('str').value); $.ajax({ dataType: "jsonp", type: "GET", data: {'s':s}, success: function(data){ loadList(data); } }); return false;} |
jQuery에서는 위처럼 $.ajax() 스펙을 이용하여 평소에 Ajax를 구현하던 것과 동일한 모양으로 JSONP를 구현할 수 있습니다. Ajax와 다른 점은 단지 dataType 값을 “jsonp”로 놓았다는 것 뿐입니다. 위 예제코드를 실행해보면 success 함수가 콜백함수의 역할을 하게 되는 것을 볼 수 있습니다.
다만 이렇게 JSONP를 구현할 경우 3가지 한계가 있습니다. 첫 번째로 type 값은 무조건 GET으로 고정해야 합니다. POST 등으로 설정할 경우, data 값에서 설정한 파라메터들이 실제로 전달되지 않아 정상작동하지 않는 경우가 있습니다. 두 번째로 JSONP를 사용할 경우에는 통신실패시 처리함수인 error 값은 사용할 수 없음을 유념해야 할 것입니다. 마지막으로 url 파라미터로 통신할 파일에서 콜백함수를 받는 GET 파라미터는 반드시 callback으로 고정되어야 합니다.